
怎么读俺”。来自azure blob存储的owl

我得把我的项目转移到databricks。我的项目要求我阅读“的本体文件。猫头鹰”分机。我在用owlready2包阅读。owl文件。
但是我无法从blob存储中读取owl文件。
我试过了
- 使用<code>请求。get(“azure file url”),但这会引发错误:“指定的资源不存在”
- owlready2.get_ontology(“azure file url”),但此操作失败,错误为-“HTTP错误404:指定的资源不存在
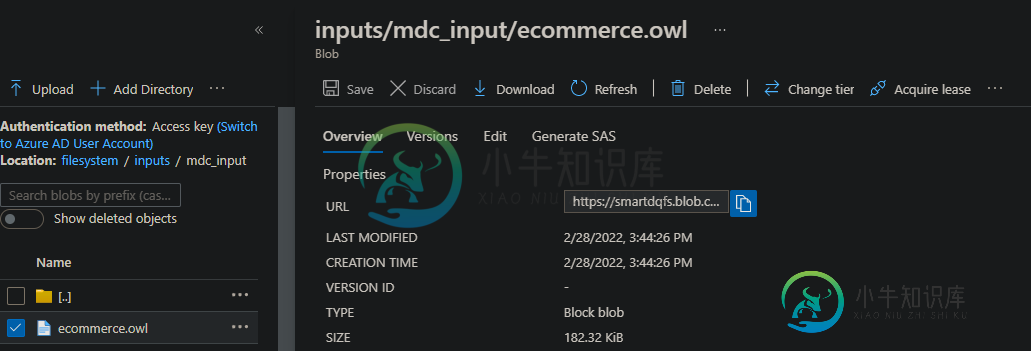
寻找从blob存储器中读取owl文件的方法。
共有1个答案

出现此错误的原因是,您尝试读取的blob位于“私有”blob容器中(即不允许公共读取访问)。
为您尝试读取的blob创建一个至少具有“读取”权限的共享访问签名(SAS ),并在您的代码中使用SAS URL。要创建服务协议,请单击屏幕截图中显示的“生成服务协议”按钮。
要了解有关容器 ACL 的更多信息,请参阅此链接:https://learn.microsoft.com/en-us/rest/api/storageservices/get-container-acl。
要了解有关共享访问签名的更多信息,请查看此链接:https://learn.microsoft.com/en-us/rest/api/storageservices/delegate-access-with-shared-access-signature.
-
我想从JPA存储库中创建一个流。目标是将来自回购的实体(可能超过一百万)映射到其他实体,这些实体将依次存储在另一个回购中。 到目前为止,我构建了一个收集器,它将收集给定数量(例如1000)实体,然后将其存储到目标存储库中。这将在并行流中工作。我现在需要的是一种从源存储库中提取实体并在需要时将它们馈送到流中的好方法。 到目前为止,最有希望的是实现供应商(http://docs.oracle.com/
-
这是可行的,但这里的问题是,在流回此方法的客户端之前,它必须首先缓冲所有字节。这会导致很多延迟,尤其是当存储在GCS中的文件很大时。 是否有一种方法可以从GCS获取文件并将其直接流到OutputStream,这里的OutputStream是针对servlet的。
-
我正在尝试从包应用程序Oracle10g调用存储过程“GetGlobalParamValue org.springframework.boot版本“2.2.0.release” 当我在SQL developer中运行它时,一切正常我得到了正确的结果 我试过了 1. 或者2。 它不起作用 我得到一个错误:
-
KAG 中、游戏的存储/读取、是通过(*)「栞(标签)」进行的。( 对无法使用此标记的用户,请修改 MainWindow.tjs )。 关于书签的说明,也请参考一下 游戏存档文件相关 的内容。 很遗憾的是、KAG 内建的存储・读取功能还无法做到随时存档。而是需要作者自行在剧本档中加入允许存储标签、也就是必须要设定存储・读取的「场所」。(译注:KAGeXpress内建了自动存档点,在每次使用[
-
ChatGPT怎么读?