
Kafka DSL Kstream->Ktable联接-联接序列化编译错误

我试图根据Kafka的文档实现这个连接。
我不知道为什么这个连接不起作用。。。
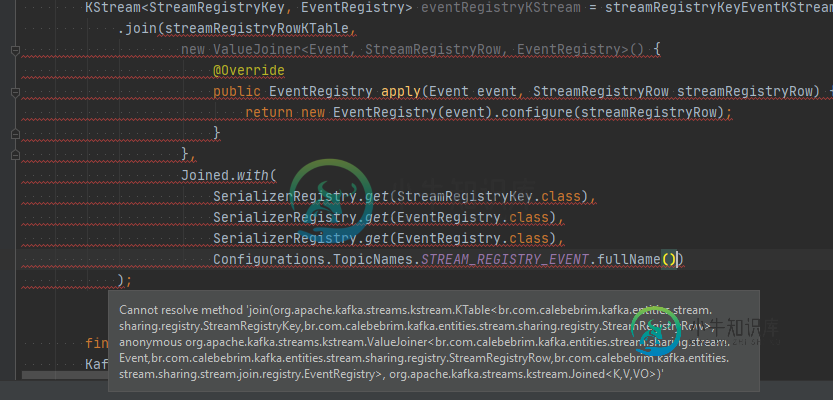
首先我通过了所有的值。
如果未加入序列化选项,我将收到此运行时异常:
线程“StreamAPP-stream-event-b3dc5fff-abee-4fa0-92f9-e1690f8fd152-StreamThread-1”组织中出现异常。阿帕奇。Kafka。溪流。错误。StreamsException:ClassCastException在为主题StreamAPP-stream-event-KSTREAM-KEY-SELECT-00000000 25重新分区生成数据时发生。序列化程序(key:org.apache.kafka.common.serialization.ByteArraySerializer/value:org.apache.kafka.common.serialization.ByteArraySerializer)与实际的键或值类型不兼容(键类型:br.com.calebebibrim.kafka.entities.stream.sharing.registry.streamRegistry键/值类型:br.com.calebebibrim.kafka.entities.stream.sharing.stream.Event)。更改StreamConfig中的默认SERDE或通过方法参数提供正确的SERDE(例如,如果使用DSL,#to(字符串主题,已生成
有人能帮我吗?
谢谢
共有1个答案

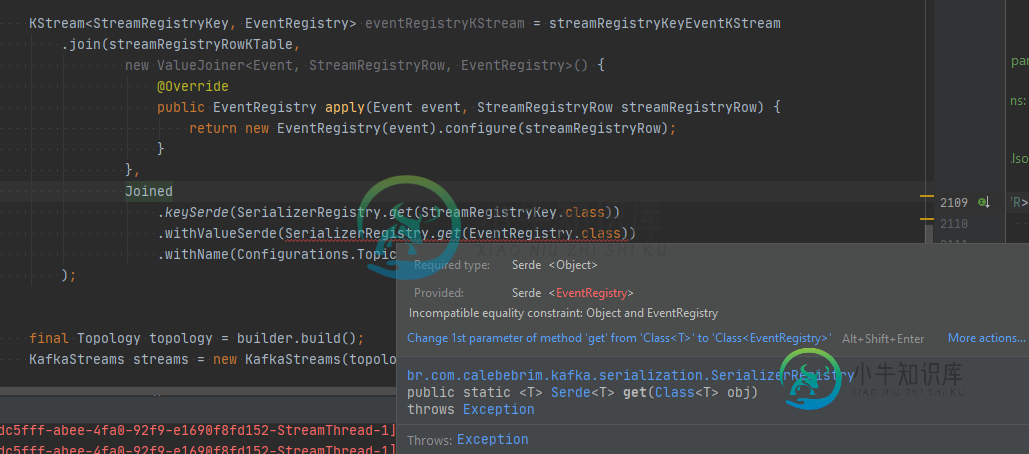
解决了,
我发现连接操作不能转换数据。
所以,我之前只是应用了mapvalue,比如:
-
我正在使KStream-KStream连接,其中创建2个内部主题。而KStream-KTable join将创建1个内部主题+1个表。 就性能和其他因素而言,哪个更好?
-
问题内容: 在我的办公室里,关于sql联接中联接列的顺序正在进行很大的讨论。我很难解释它,所以我只介绍两个sql语句。考虑到sql最佳实践,哪个更好? 或者 因此,在联接的ON部分中,是否编写是否重要? 问题答案: 此处的最佳实践是选择一个并 在团队中 坚持使用。就我个人而言,我更喜欢它,因为它对我来说似乎更干净。
-
我目前正在尝试使用KStream到KTable的连接来执行Kafka主题的充实。对于我的概念证明,我目前有一个Kafka流,其中有大约600,000条记录,它们都有相同的键,还有一个KTable,它是从一个主题创建的,其中KTable主题中的键与创建KStream的主题中的600,000条记录中的键匹配。 当我使用左联接(通过下面的代码)时,所有记录在ValueJoiner上都返回NULL。 下面
-
我有两个数据帧df1(Employee表) 和 在我连接了df1.dept_id和df2.id上的这两个表之后: 同时将其保存在文件中, 它给出错误: 我读过有关使用字符串序列来避免列重复的信息,但这适用于要对其执行连接的列。我需要对未连接的列具有类似的功能。 有没有一种直接的方法可以将重复列嵌入表名以便保存? 我想出了一个解决方案,匹配两个df的列,并重命名重复的列,将表名附加到列名上。但是有直
-
我需要帮助理解在Kafka2.2中使用max.task.idle.ms时的Kafka流行为。 我有一个KStream-KTable联接,其中KStream已被重新键入: 所有主题都有10个分区,为了测试,我将max.task.idle.ms设置为2分钟。myTimeExtractor只有在消息被标记为“快照”时才更新消息的事件时间:stream1中的每个快照消息都将其事件时间设置为某个常数T,st
-
我正在尝试执行 KTable-KTable 外键联接,但我收到一个错误,因为 Kafka 流正在尝试对外键使用字符串 serde。 我希望它使用Kotlinx序列化服务器。如何指定? 我想使用FK选择器将两个KTables的数据连接在一起,并将值重新映射到一个聚合对象中。 然而,我得到一个错误,因为Kafka Streams正在使用(我的默认Serde)用于反序列化外键。但它是一个JSON对象,我