
问题:

将工作簿中的多个Excel工作表合并为一个工作表Python
赏夕
所以我有 1500 个 Excel 工作簿,每个工作簿都有 10 张结构完全相同的工作表。我尝试将多个Excel工作簿合并到一个文件中,并使用以下代码成功:
import os
import pandas as pd
cwd = os.path.abspath('')
files = os.listdir(cwd)
df = pd.DataFrame()
for file in files:
if file.endswith('.xlsx'):
df = df.append(pd.read_excel(file), ignore_index=True)
df.head()
df.to_excel('Combined_Excels.xlsx')
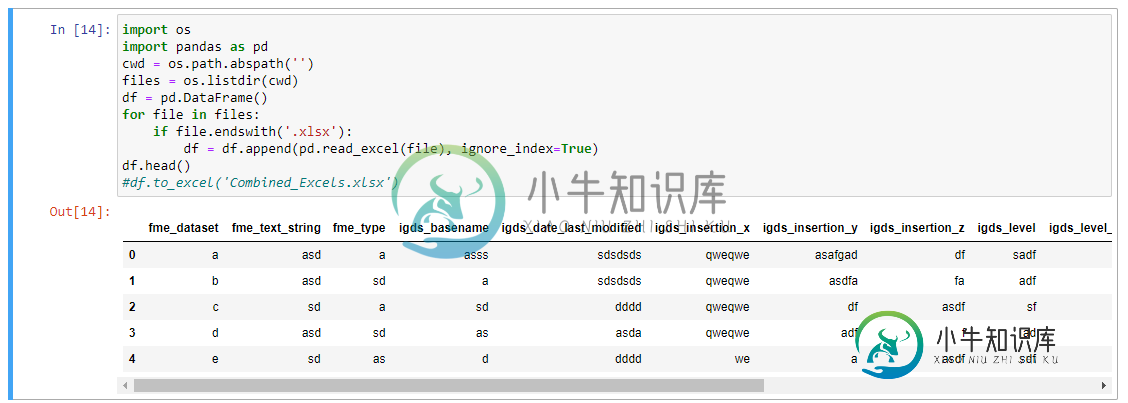
import os
import pandas as pd
cwd = os.path.abspath('')
files = os.listdir(cwd)
df = pd.DataFrame()
for file in files:
if file.endswith('.xlsx'):
df = df.append(pd.read_excel(file, sheet_name=None), ignore_index=True)
df.head()
df.to_excel('Combined_Excels.xlsx')
谢谢,努尔贝克
共有1个答案

苏磊
您可能会找到更好、更有效的方法来解决这个问题,但我是这样做的:
import os
import pandas as pd
# First, combine all the pages in each Workbook into one sheet
cwd = os.path.abspath('')
files = os.listdir(cwd)
df_toAppend = pd.DataFrame()
for file in files:
if file.endswith('.xlsx'):
df_toAppend = pd.concat(pd.read_excel(file, sheet_name=None), ignore_index=True)
df_toAppend.to_excel(file)
# And then append all the Workbooks into single Excel Workbook sheet
cwd_2 = os.path.abspath('')
files_2 = os.listdir(cwd_2)
df_toCombine = pd.DataFrame()
for file_2 in files_2:
if file_2.endswith('.xlsx'):
df_toCombine = df_toCombine.append(pd.read_excel(file_2), ignore_index=True)
df_toCombine.to_excel('Combined_Excels.xlsx')
对于大数据集,可能需要相当多的时间来组合。希望这最终能帮助到某人。
类似资料:
-
我有一个Excel工作簿,其中包含36个不同的工作表,我每两周收到一次,工作表在所有标签上都有共同的标题,并且每个标签上都有不同的唯一标题,但每条记录都有一个唯一的ID,可以有多个记录。 我要做的是从所有的工作表中提取唯一的id,然后将每个工作表中的数据提取到一个工作表中,其中包含所有的公共标题和唯一标题。 我正在考虑使用下面帖子中的代码将其导入Access。连接表并将其导出回Excel中的一个工
-
我知道如何复制工作表,但这将导致多个工作表。我需要的是一个输出工作表,一个接一个地包含所有的工作表。 目前我正在做的是将每个工作表导出为< code>DataTable,然后逐个导入: 但这样,我就失去了单元格样式和文本格式 有没有办法用保留样式?
-
试图从当前工作簿“Create Report.xlsm”中复制工作表名称“Headings Explantions”,该工作簿打开到我要求打开的工作簿中,我得到了下标超出范围的错误
-
然后另一个问题是工作簿的名称都不同,所有300个。是否有一个宏可以复制我打开的工作簿,而不是每次都输入实际的名称?
-
2)有没有一种方法可以让。value=.value与数据透视表一起使用?在以前的宏中,这从来没有与数据透视一起使用过,所以我必须使用复制和粘贴,如下所示。 非常感谢您的帮助!