
SSIS将数据从csv文件加载到sql表

我正在通过SSIS将数据从csv文件加载到我的sql表中。是否对从csv文件读取的记录数指定了默认限制?
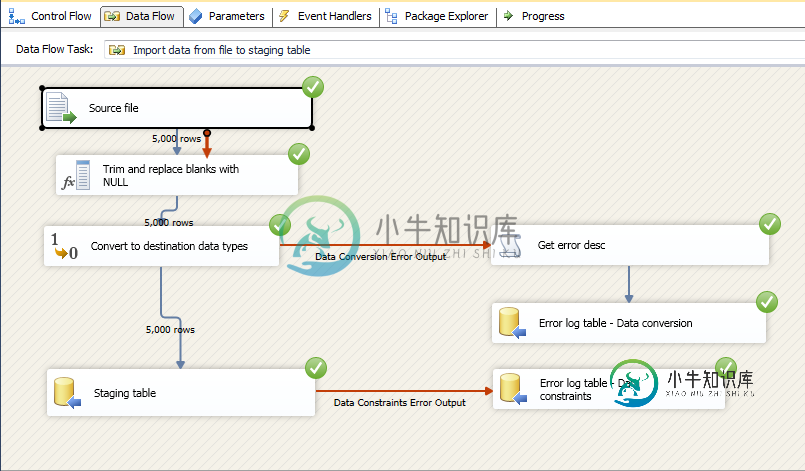
在加载csv文件时,我的数据流组件只处理5000条记录,尽管它包含5341条记录,如下面的图像所示。我如何修复这个问题?
共有1个答案

您是否[错误地]吞下了错误行?
在源错误输出中设置了什么?
-
问题内容: 我需要从多个JSON文件中加载数据,每个文件中都有多个记录到Postgres表中。我正在使用以下代码,但无法正常工作(在Windows上使用pgAdmin III) SAMPLE.JSON文件的内容是这样的(从许多这样的记录中得到两个记录): 问题答案: 试试这个:
-
我正在使用Tibco ComputeDB,这对我来说是新的。它使用sparkDB和snappydata。我想把数据从MS SQL添加到SnappyData的内存表中。 我可以从CSV读取数据,并使用以下命令将其加载到snappyDaya中。 现在,同样的方式,我想从MS SQL读取数据,并想将其添加到snappyData中,但无法找到正确的方法。我遵循了下面的文档,能够连接到MS SQL serv
-
问题内容: 我想在数据库中使用csv文件 问题答案: 由于SQLAlchemy的强大功能,我还在项目中使用了它。它的强大功能来自于与数据库“对话”的面向对象的方式,而不是硬编码难以管理的SQL语句。更不用说,它也快很多。 坦率地回答您的问题,是的!使用SQLAlchemy将数据从CSV存储到数据库中简直是小菜一碟。这是一个完整的工作示例(我使用了SQLAlchemy 1.0.6和Python 2.
-
问题内容: 我正在尝试使用Java + Hibernate + Spring将CSV文件加载到mySQL数据库中。我在DAO中使用以下查询来帮助我加载到数据库中: 我有一些想法可以从http://dev.mysql.com/doc/refman/5.1/en/load- data.html 使用它,以及如何从hibernate +spring应用程序将csv文件导入到mysql中? 但是我得到了错
-
我正在使用hazelcast IMap存储我的应用程序数据。 我面临着一个小问题。 问题说明:- 当我启动spring-boot应用程序时,我正在将数据库表数据加载到hazelcast中。 示例:- 但是当我获取相同的数据时,我得到的顺序不同。 那么有没有办法按照插入的顺序获取数据呢?