
Kafka的延迟非常高

我不熟悉ApacheStorm和kafka,作为POC的一部分,我正在尝试使用kafka和ApacheStorm处理消息流。我使用的是暴风Kafka的来源https://github.com/apache/storm/tree/master/external/storm-kafka,我能够创建一个示例程序,该程序使用KafkaSpout读取来自kafka主题的消息,并将其输出到另一个kafka主题。我有3个节点的kafka(所有三个都在同一台服务器上运行)集群,并创建了具有8个分区的主题。我将KafkaSpout并行设置为8,bolt的并行设置为8,并尝试了8个执行器和任务。我已经尝试在kafka级别、SpoutConfig级别和storm级别设置了很多tunnig参数,但总体延迟问题非常严重。我需要消息处理Garunte,所以确实需要确认。Storm群有一个管理员,动物园管理员有3个noed,由Kafka和Storm共享。它运行在Red Hat Linux机器上,具有144MB RAM和16CPU。有了下面的参数,我会得到非常高的喷口进程延迟约40秒,我需要得到大约50K味精/秒的水平,你能帮我配置实现它吗。我在不同的网站上浏览了很多帖子,尝试了很多调优选项,但没有结果。
Storm config
topology.receiver.buffer.size=16
topology.transfer.buffer.size=4096
topology.executor.receive.buffer.size=16384
topology.executor.send.buffer.size=16384
topology.spout.max.batch.size=65536
topology.max.spout.pending=10000
topology.acker.executors=20
Kafka config
fetch.size.bytes=1048576
socket.timeout.ms=10000
fetch.max.wait=10000
buffer.size.bytes=1048576
提前谢谢。
Storm UI截图
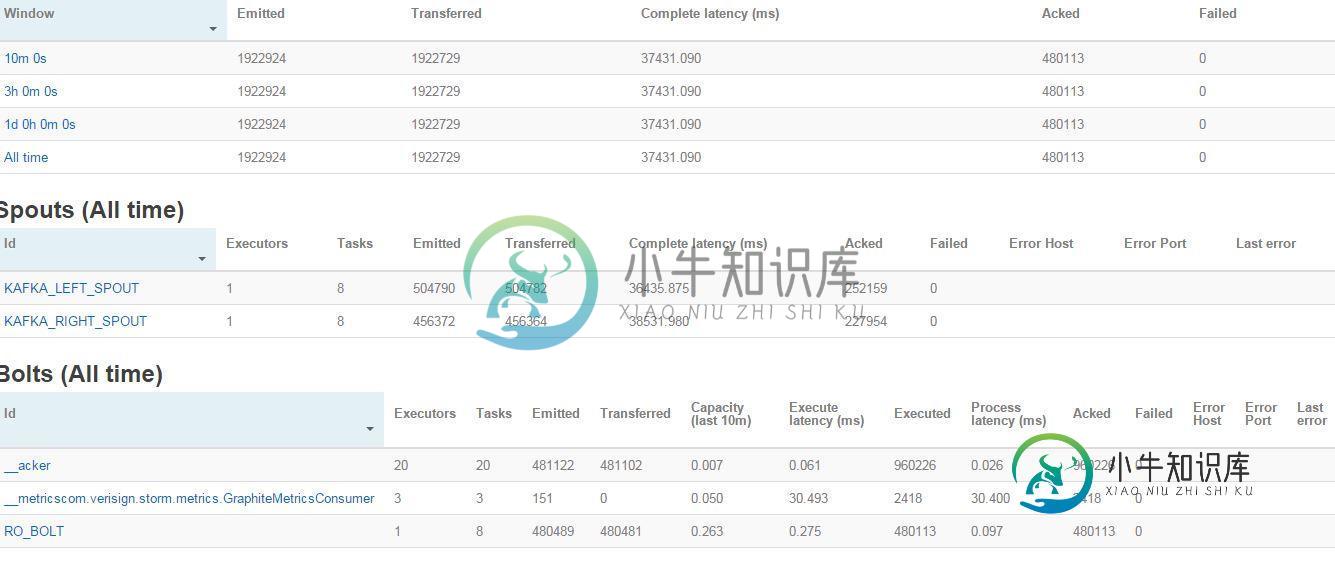
共有3个答案

我不知道你的问题是否解决了,但除了调整拓扑结构之外。马克斯,喷口。待定根据延迟要求,您还需要调整批处理大小。设置拓扑。喷口最大批量。将大小设置为较低的数字可能有助于减少延迟。

看看你的UI屏幕截图,你的喷口似乎会释放出更多的数据,就像你的螺栓可以处理的那样。两个喷口都发出了大约500K条消息,但只有250k条得到了确认(通过bolt执行的元组数可以推断出这一点——大约480K,即两个喷口发出的元组的一半)。40秒的延迟从一开始就是相同的值吗?或者延迟会随着时间的推移而增加?如果它随着时间的推移而增加,很明显,你的螺栓是瓶颈。您有两个选择:
- 增加螺栓和/或的平行度
只有当您有足够的内核时,第一个选项才有意义(但到目前为止,这应该不是一个问题,因为您提到了16个可用的CPU)。如果第二个选项适用于您,则取决于您想要实现的吞吐量。您提到了50K msg/sec,但UI没有显示当前吞吐量(即,喷口输出速率),因此我无法判断节流是否是一个选项。此外,必须确定喷口的最佳值。max.pending尝试一个错误(从1000的值开始对我来说似乎是合理的)。

您的拓扑有几个问题:
- 您应该拥有与kafka分区相同数量的spout执行器
- 你的拓扑不能足够快地处理元组。我对元组如何没有开始在超时时失败感到惊讶。使用合理的价值为topology.max.spout.pending,我建议150或
- 这只会防止超时,您的喷口会慢慢消耗元组,因为拓扑的其余部分无法处理它。
-
我在一个公认的缓慢配置中设置了Kafka——但我不期待我看到的数字。 我将集群设置为<code>LogAppendTime</code>,因此我正在测量事件写入Kafka(由代理决定)与服务接收到事件之间的时间。代理和应用程序都位于“同一位置”,因此服务器之间的ping时间很短,时钟应该同步或接近。 我看到延迟在 到 600ms 之间,很多是 ......巨大的差异让我觉得我的设置出了问题。它因消
-
如何使用Apache Kafka生成/使用延迟消息?标准的Kafka(和Java的kafka-client)功能似乎没有这个特性。我知道我自己可以用标准的等待/通知机制来实现它,但是它看起来不是很可靠,所以任何建议和好的实践都很感谢。 找到相关问题,但没有帮助。正如我所看到的:Kafka基于从文件系统的顺序读取,并且只能用于直接读取主题,保持消息的顺序。我说的对吗?
-
我有一个Kafka连接接收器记录从Kafka主题到S3。它在工作,但太慢了。Kafka主题每秒接收约30000条消息。连接接收器无法跟上。我已经尝试增加Kafka连接器的任务。最大值从1到3,这会创建更多任务,但这似乎无助于提高消息/秒的速度。我试着增加Kafka连接工人的CPU分配,这似乎也没有帮助。 我还能试什么?哪些指标有助于监控以进一步识别瓶颈? 更新:Kafka主题有5个分区。Kafka
-
本文向大家介绍kafka如何实现延迟队列?相关面试题,主要包含被问及kafka如何实现延迟队列?时的应答技巧和注意事项,需要的朋友参考一下 Kafka并没有使用JDK自带的Timer或者DelayQueue来实现延迟的功能,而是基于时间轮自定义了一个用于实现延迟功能的定时器(SystemTimer)。JDK的Timer和DelayQueue插入和删除操作的平均时间复杂度为O(nlog(n)),并不
-
我正在使用Spring Kafka1.0.3来消费kafka消息。Kafka的2个主题,每个主题有1个分区。在java代码中,有2@KafKalistener来消费每个主题消息。ConcurrentKafkaListenerContainerFactory的并发设置为1。但消息有时会延迟20秒以上。 有人知道为什么吗? 添加调试日志,并且延迟不是每次都可以,有时也可以:
-
我有一个基于Spring的webapp,我的问题是在代码更改后,我开始出现延迟加载异常。下面我详细描述了这种情况: 在开始的时候 我有一个账户和文字实体。一个帐户可以有多个单词,一个单词可以分配给多个帐户。 一个ccount.class 单词班 除了每个账户只能有一个“WordForToday”,它由账户中映射的单词实体表示。类如下: 一切都正常工作。特别是我有一个@Schedilly方法,每天调