
使用CDO将netCDF转换为CSV文件时出现问题

这篇文章很长,因为我想更好地解释上下文。
我的主要数据源是netCDF格式,我想转换成CSV文件。
有一段时间,我一直在用Python进行转换。作为一个例子,我使用一个先前修改过的netCDF数据(m
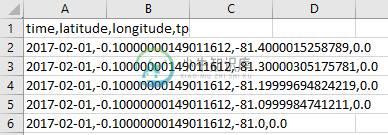
可以注意到:
-
< li >第一行包括用逗号分隔的变量名。第二行及以上的值也用逗号分隔。 < li >纬度和经度值不四舍五入。
如上图所示,是所需的数据表示。
之后,我决定使用气候数据操作员(CDO),因为它更容易应用一些功能。在WSL上的Ubuntu中,我将netCDF文件转换为CSV文件。这些是我使用的代码:
第一个代码
cdo-输出选项卡,日期,lat,lon,值era5land_total_precipitation_daily_feb-nov_2017_mm.nc
输出数据显示为

变量名称所在的第一行前面是“#”,而它不应该在那里。此外,值由空格分隔。
第二个代码
cdo输出选项卡,日期,纬度:6,纬度:6,值:8era5land_total_precipitation_daily_feb-nov_2017_mm.nc|grep-v '#' | se-e's/*/,/g'
第三个代码
< code>cdo -outputtab,date,lat:6,lon:6,value:8 era 5 land _ total _ deposition _ daily _ Fe B- nov _ 2017 _ mm . NC | sed ' s/[[:space:]]/,/g '
最后两行代码显示相同的输出

这个问题用逗号分隔的值部分解决了,尽管在一些观察中,最后两个值仍然被空格除以。此外,顶部没有变量名。
第四个代码
cdo-out辨别,日期,纬度:6,纬度:6,值:8era5land_total_precipitation_daily_feb-nov_2017_mm.nc|awk'FNR==1{row=2美元","3美元","4美元","5美元;打印行}FNR1=1{row=1美元","2美元","3美元","4美元;打印行}'
输出包含
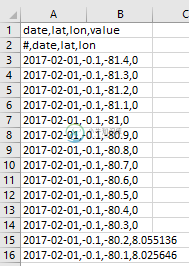
最后一个代码的结果最接近我想要获得的结果,除了需要删除图像内容中的第二行并且纬度/经度值仍然四舍五入。有什么建议来获得像图像 1 这样的数据集吗?
额外帮助:有谁知道这些代码的含义?
...| grep -v '#' | sed -e 's/ */,/g'
<代码>...| sed 's/[[:space:]]/,/g'
…|awk'FNR==1{行=$2”,“$3”,“$4”,“$15;打印行}FNR1=1{行=$1”,“$s”,“%3”,“%4;打印行}'
提前非常感谢!
共有1个答案

我在另一个论坛上问了同样的问题,我得到了以下解决方案:
cdo -outputtab,date,lat:6,lon:6,value:8 infile.nc | grep -v '#' | tr -s ' ' | sed -e 's/ /,/g;s/^.//;s/.$//'
谨记
第一行包含变量的通用名称:v1、v2、v3和v4,而不是日期、纬度、经度和tp。- 所有值都以逗号分隔。
-
问题内容: 我需要帮助来理解使用java将XML文件转换为CSV文件所涉及的步骤。这是XML文件的示例 这是生成的CSV文件。 我当时正在考虑使用DOM解析器读取xml文件。我遇到的问题是,我需要按名称指定要编码的特定元素,但我希望它能够解析它而不这样做。 Java中是否有任何工具或库可以帮助我实现这一目标。 如果我下面有这种格式的XML文件,并且想在与MSgId相同的行中添加InitgPty的值
-
此过程中的主要问题是下面的代码: 产生以下错误: 我有两个CSV文件,其中一个包含变量(降水量)的所有实际数据,每一列都是一个站点,它们的对应坐标在第二个单独的CSV文件中。我的示例数据在这里的谷歌驱动器中。 如果您想查看数据本身,但我的第一个 CSV 文件具有形状(39811、144),第二个 CSV 文件具有形状(171、10),但请注意;我仅将切片数据帧用作 (144, 2)。 这是代码:
-
当尝试使用将文件转换为文件时,会出现以下异常: RuntimeException:Scanline必须以EOL代码字开头。在com.itextpdf.text.pdf.codec.tifffaxdecoder.readeol(tifffaxdecoder.java:1303),在com.itextpdf.text.pdf.codec.tifffaxdecoder.decode2d(tifffaxd
-
我有一个CSV文件,我想在我的弹性搜索中导入它。 我用的是Windows 10,我也有一个Kibana,可以在导入后浏览数据。我使用Logstash来尝试导入。 我的所有服务(Kibana、es和Logstash)都在我的本地主机上运行。 我尝试使用以下Logstash配置文件(我的csv文件在正确的路径中): 如您所见,我试图使用“csv”或“grok”过滤器。 然后,我在详细模式下使用以下配置
-
问题内容: 嗨,我正在尝试将oracle jdbc结果集转换为csv文件。下面是使用的代码。当字段中具有如下所示的值时,就会发生问题。它会使输出csv变形,所有这些都放在单独的行而不是一个字段中。 栏位中的值在csv中列为 [<333message:脚本中的运行时错误’ProcessItem:’类型:’ITEM’“ 1:0)。内部脚本错误:java.lang.NullPointerExceptio
-
我现在正在解析一个26页的文件。带有图像、表格、斜体和下划线的docx。我能清除 我使用ApachePOI创建了带有XWPF段落列表的XWPF文档格式。当我遍历XWPF段落时,如果一个段落包含不同的样式,我无法获得各行的样式(斜体、下划线、粗体)。 我尝试过使用XWPF。段落getrun()。XWPF。。。跑getfamilyfont()我将得到null。但是当我运行XWPF时,我在段落级别获得数