
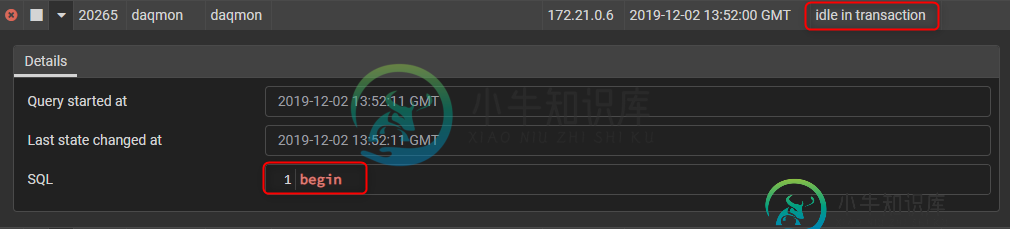
什么可能导致“BEGIN”语句的“事务中空闲”

我们有一个node.js的应用程序,它通过pg-promise连接到Postgres 11服务器-所有进程都在docker容器中的单个云服务器上运行。
有时我们会遇到应用程序不再反应的情况。
我认为情况是这样的:
- 应用程序已通过向数据库发送
BEGINsql 命令来启动事务 - 数据库获得此命令并开始新事务,从而获得了模式
virtualxid的独占锁 - 现在数据库等待应用程序发送下一个语句(直到它收到
COMMIT或ROLLBACK)- 然后它将释放模式virtualxid的独占锁 - 但由于某种原因,它不再得到语句:
我认为节点.js事件循环被阻塞了 - 因为当时,当我们看到这些锁时,node.js应用程序不再记录语句。但是 Web 服务器仍然收到请求并报告了一些上游超时请求。
这有意义吗(我真的不确定2.和3.)
为什么所有交易在开始时都会阻塞?这只是巧合还是显示的SQL可能是错误的?
顺便说一句:在我发现的这个答案中,我们可以设置idle_in_transaction_session_timeout,以便这些事务将在超时后释放——这很好,但我试图理解是什么导致了这个问题。
共有3个答案

不出所料,问题是由我们的应用程序代码引起的。交易使用错误:
-
< Li > RESTendpoint之一使用Database.tx()立即启动了一个新事务。 < li >此事务被向下传递了多个级别,但是链中的一个函数出现错误,并且将< code>undefined而不是事务传递到下一个级别 < li >最低存储库级别的函数通过再次使用Database.tx()启动了一个新的事务(因为事务参数< code >未定义)
这在重载下开始失败:
-
< li >连接池大小被设置为10 < li >当对此endpoint有许多并发请求时,我们遇到了这样一种情况,其中10个请求已启动(打开了外部事务),但尚未到达将请求第二个事务的存储库代码。 < li >当这些请求到达存储库代码时,它们从连接池中请求一个新的(第二个)连接。但是这个调用将被阻塞,因为当前所有的连接都在使用中。 < li >所以我们有一个讨厌的应用程序级死锁
所以解决方案是修复应用程序代码(中间函数必须正确地传递事务)。然后一切正常。
此外,我强烈建议设置合理的idle_in_transaction_session_timeout和连接超时。然后,即使在将来的版本中再次引入这种应用程序死锁,应用程序也可以在超时后自动恢复
注释:
- v 10.3.4 之前的 pg-postgres 包含一个与
连接超时相关的小错误 #682 - 10.3.5 版之前的 PG-promise 无法从
空闲事务超时中重新转换,并使连接处于断开状态:请参阅 PG-promise #680
基本上还有另一个问题:不需要使用事务——因为所有函数都只是读取数据:所以我们可以只使用Database.task()而不是Database.tx()

你的解释是正确的。至于为什么会这样,那就很难说了。看起来好像在你的应用程序中有某种错误(可能是未被发现的死锁),或者可能在nodes.js或pg-promise中。您必须在该级别进行调试。

事务根本没有阻塞。数据库正在等待应用程序发送下一条语句。
事务ID上的锁只是事务相互阻塞的一种技术,即使它们没有争夺表锁(例如,如果它们正在等待行锁):每个事务都持有自己事务ID上的独占锁,如果它必须等待并发事务完成,它可以请求该事务ID上的锁(并被阻塞)。
如果所有事务都像这样,那么锁一定在您的应用程序中的某个地方;不涉及数据库。
在数据库中查找阻塞的进程时,在< code>pg_locks中查找< code>granted为false的行。
-
我正在与用propagation.requires_new注释的方法的奇怪行为作斗争。 以下是TransactionManager的日志:
-
我主要担心的是,由于使用乐观锁定,当我将有多个进程(比键数多得多,键数只有4个)试图更新值时,事务失败率将非常高。 这是正确的吗?有没有办法防止这种情况发生?
-
如果另一个客户机在我们调用watch之后更改了powerlevel的值,我们的事务将失败。如果没有客户端更改该值,则该集合将工作。我们可以在循环中执行这段代码,直到它起作用为止。 为什么不能在不能被其他命令打断的事务中执行增量?为什么我们需要迭代而不是等到没有人改变值才开始事务?
-
本文向大家介绍Oracle中死事务的检查语句,包括了Oracle中死事务的检查语句的使用技巧和注意事项,需要的朋友参考一下 查询v$px_session和v$fast_start_servers,显示很多并行进程在rollback,根据以往的工程经验: 于是改为 之后,再次运行 使用如下脚本查看回滚完毕的预计时间(以天为单位): 24*0.21=5.04小时。即:预计5.04小时后回滚完毕。 另外
-
我最近发现了一个项目,我在一段时间以前正在进行的一个项目中更新了依赖项,与此事件相关,我将FireStore的依赖项()从17.1.5更新到了最新的18.2.0。因为这次更新,现在我的app突然抛出如下错误: IllegalStateException:FragmentManager已经在执行事务 在片段的方法中调用时。(由于错误是关于的,我认为这可能是相关的) 具体代码如下: 当我将依赖关系恢复
-
对于我的Java类,要求我们在working For语句中添加分号,并解释为什么输出是这样的。我不明白为什么添加分号会产生错误的树类型错误,导致代码无法编译。代码下面是输出;我还向any标记添加了反斜杠,因为它不会以其他方式显示。那么,为什么for语句后面的分号会导致这样的错误呢?提前谢谢。 运行时间: