
将现有的DynamoDB数据源与Amplify和AppSync一起使用

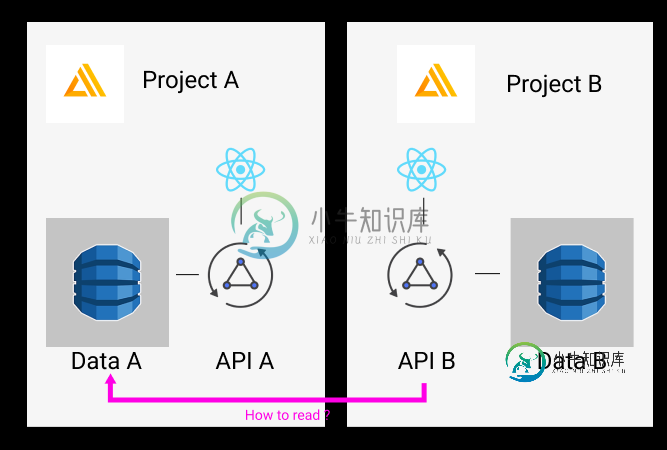
我有一个使用Amplify(使用AppSync API和Cognito)制作的工作应用程序。我想制作另一个不同的应用程序,但与我的第一个项目共享一些数据(相同的产品,但不同的目标、用法和安全规则)。
有没有一种干净的方法可以在新项目中使用Amplify,告诉GraphQLAPI从我的第一个Amplify项目中获取DynamoDB中的一些数据?
这些数据会经常变化,而且会很重——所以我不太喜欢任何同步解决方案。
我考虑过这些解决方案,但我没有足够的经验来判断其中一个是否好:
- 在这个新项目中不使用放大器,而是使用SAM(但我将失去放大器提供的所有构建管道)
- 为主机和认证使用放大器,但使用SAM配置AppSync并将其插入现有的DataSource
- 也许云形成可以是答案,但我不知道如何在放大器中直接与它交互
共有1个答案

亚马逊有一篇关于微服务架构的文章可能对你有用https://aws.amazon.com/blogs/mobile/appsync-microservices/
我不确定Amplify是否支持向其添加多个api,如果支持,您可以添加它,然后只在其上拉api。
在我看来,最简单的方法就是创建一个查询endpoint,使用lambda从其他数据源获取数据。
所以,在这种情况下,您可以将您的模式编辑成这样
query
{
externalData [ExternalData] @function(name: "getExternalData")
}
然后需要添加lambda函数getExternalData,该函数将负责根据需要查询数据。
上面的文章有关于此体系结构的更深入的细节
-
我目前正在使用Aws Appsync、Aws Lambda和Aws Neptune作为应用程序。我的Lambda函数使用NodeJS 12。现在我的问题是,当我执行一个变异并最终执行一个查询时,从Neptune(更具体地说是gremlin)那里为我的graphql api(appsync)获取适当的JSON格式(我想确保变异首先起作用)。例如: 这是我的图ql模式的Post类型,上面有addPos
-
我有一个react应用程序,我正在使用AWS amplify。我的问题是,当我从DynamoDB查询数据时,通过AWS AppSync的正确方式是正确的,然后我是否有一个lambda函数来查询数据库,还是AppSync只是这样做?这样做的正确途径是什么?它会反应吗-
-
Amplify是否支持此处概述的脱机功能:https://docs.aws.amazon.com/appsync/latest/devguide/building-a-client-app-react.html#offline-背景 我应该这样设置吗?https://aws.github.io/aws-amplify/media/api_guide#configuration-for-graphq
-
我使用AWS加密客户端。下面的代码抛出错误为 错误:@DoNotTouch不适用于现场 然而,如果我给出@DoNotTouch配置,如下所示[使用getter和setter] 这很好用。我猜lombok生成的getter和setter不会被AmazoneCryptionClient识别 我在跟踪这个aws doc:https://aws.amazon.com/blogs/developer/cli
-
问题内容: 我有一个带有jquery和bootstrap的现有PHP项目,没有使用任何前端框架。 我正在尝试使用webpack模块捆绑器来为我的项目资源创建单个入口点,使用节点js包管理器管理js依赖项,以缩小js css的方式运行任务,调整图像大小等。并缩短了加载单个页面所需的浏览器加载时间。 我遇到了webpack教程,必须安装并安装它的dev-server,但是问题是我无法理解如何转换项目中
-
问题内容: 我正在使用Spring,Spring Data JPA,Spring Security,Primefaces的项目中工作… 在本教程中,你只能在预定义的数据源之间实现动态数据源切换。 这是我的代码的片段: springContext-jpa.xml 我想做的就是使targetDataSources映射也与其元素一样动态。 换句话说,我想获取某个数据库表,使用存储在该表中的属性创建我的数