
nunit为什么不运行包含控制/特殊字符的测试

如果我有一个测试类
public class Tests
{
[TestCaseSource(nameof(TestSource))]
public void Test(string c)
{
Assert.Pass();
}
public static IEnumerable<object> TestSource()
{
for (char c = '\0'; c < 255; c++)
{
yield return c.ToString();
}
}
}
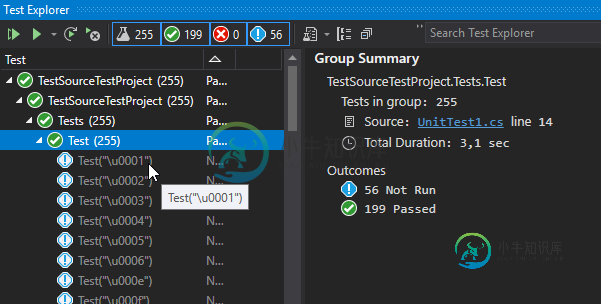
则Visual Studio中的测试运行程序可以发现所有测试,但不会运行所有测试。
以下是未运行的ascii字符范围:
U_0001 - U_0006
U_000E - U_001F
U_007F - U_0084
U_0086 - U_009F
我们目前将其中一些字符(如u_0002)用于与网络工作相关的测试,这些字符包含在测试中,但目前未运行
这是测试运行的输出
---------- Starting test discovery for requested test run ----------
NUnit Adapter 3.17.0.0: Test discovery starting
NUnit Adapter 3.17.0.0: Test discovery complete
========== Test discovery finished: 255 Tests found in 4,8 sec ==========
---------- Starting test run ----------
NUnit Adapter 3.17.0.0: Test execution started
Running selected tests in C:\Users\WEIK014\source\repos\TestSourceTestProject\TestSourceTestProject\bin\Debug\netcoreapp2.1\TestSourceTestProject.dll
NUnit3TestExecutor discovered 199 of 199 NUnit test cases
NUnit Adapter 3.17.0.0: Test execution complete
========== Test run finished: 199 Tests run in 8,6 sec (199 Passed, 0 Failed, 0 Skipped) ==========
正如您所看到的,它甚至不知道它跳过了测试。
项目中的版本:
- Project.NET Core 2.1
- n单元3.13.1
- NUnit3TestAdapter 3.17.0
共有1个答案

好吧,这听起来可能是Visual Studio或测试适配器中显示Unicode控制字符的某个地方的bug。作为一种解决办法,您可以覆盖控制字符的测试显示名称:
public static IEnumerable<TestCaseData> TestSource()
{
for (char c = '\0'; c < 255; c++)
{
var data = new TestCaseData(c.ToString());
if (char.IsControl(c))
{
data.SetArgDisplayNames($"{(int)c:X4}");
}
yield return data;
}
}
这将保留可打印字符的显示(例如测试(“A”)),控制字符将显示为测试(0001)等。
-
我必须使用exe来运行某个函数。但是该目录包含某些具有特殊字符的文件夹,比如“.”,“-”,所以它不会被执行。我可以像重命名文件名一样重命名目录名吗?我不确定需要做什么。 我使用Linux环境。下面是一段代码, 有人能建议我吗?谢谢
-
我正在尝试使用ansible在本地主机中安装kubectl,但收到以下错误消息: 致命:[localhost]:失败!= 我相信问题可能在于url中的回勾字符。我尝试过用单引号和反斜杠来包围它们,但都没用。这是我的剧本:
-
问题内容: 我正在编写用于更改JSON文件的脚本,但是当文件转换回JSON时,它将扩展特殊字符。 例如,JSON文件包含带有“&”的密码。复制问题的快速方法是使用以下命令: PS>“密码和123” | Convertto-Json输出为:“ Password \ u0026123” -这是简化的JSON FILE的示例 问题答案: 这是由的自动字符转义功能引起的,并且会影响多个符号,例如 Conv
-
我有一长串字符串的数据,我想将它们转换为整数,但仍保留一些包含特殊字符的字符串:,
-
问题内容: 我正在尝试使用该SQL从XML Server Expression的SQL Server 2008表中获取名字和姓氏。数据包含特殊字符。当我尝试sql时,出现以下错误: FOR XML无法序列化节点“ LastName”的数据,因为它包含XML不允许的字符(0x001B)。要使用FOR XML检索此数据,请将其转换为二进制,varbinary或图像数据类型,并使用BINARY BASE
-
事情是这样的。我有一个术语存储在索引中,它包含特殊字符,比如'-',最简单的代码是这样的: 然后使用QueryParser创建一个查询,如下所示: 不使用QueryParser而直接使用TermQuery可以做我想做的事情,但是这种方式对于用户输入文本来说不够灵活。 我想可能StandardAnalyzer做了一些事情来省略查询字符串中的特殊字符。我尝试了debug,我发现字符串是拆分的,实际查询