
库伯内特斯·德普洛伊姆斯

我在Kubernetes是个新手。我想知道在kubernetes环境中最好的生产部署场景是什么。
在过去的学派中,我习惯于将Web服务器(例如Nginx或Apache)放在DMZ层,而将其放在其他层(我们称之为层)。这样,只有web服务器在DMZ上,恶意攻击只能在web服务器VM上进行。
据我所知,K8S部署不再需要这种方法;这是因为K8S自己处理网络、吊舱和流量。所以我在考虑最确定的部署方案。
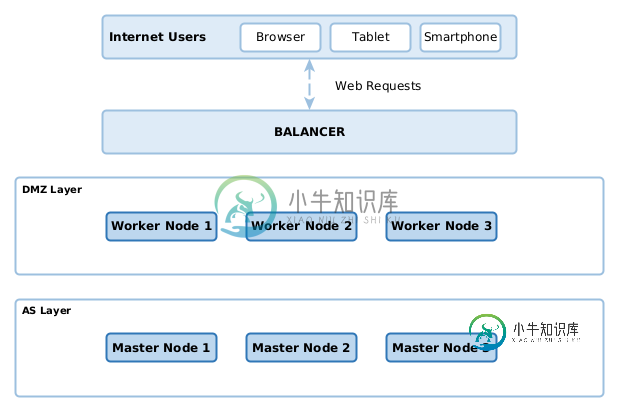

你对这两种方法有什么看法?哪一个是“最好的”?
谢谢。
安杰洛
共有1个答案

在Kubernetes中有多种方法来处理这种情况。我想你是在处理一个临时部署。
- 您可以在DMZ中有一个前端集群,在公司防火墙中有一个内部集群。这是最安全的选择,但实现和管理成本高且耗时。
- 您可以为DMZ和内部系统创建单独的节点池,并实现网络策略来限制它们之间的网络通信量。我将确保DMZ nodepool不是默认的nodepool,因此部署需要显式地针对DMZ池。
- 仅使用命名空间和网络策略来限制在DMZ中运行的豆荚之间的通信量。在大多数情况下,这应该足够安全,因为吊舱运行在操作系统监狱中,只能访问分配给它们的资源。
要记住的一件重要的事情是,pods中的容器应该在普通用户帐户下运行,而不是在root帐户下运行,除了init容器。
-
主要内容:弗洛伊德算法的实现思路,弗洛伊德算法的具体实现在一个加权图中,如果想找到各个顶点之间的最短路径,可以考虑使用弗洛伊德算法。 弗洛伊德算法既适用于无向加权图,也适用于有向加权图。使用弗洛伊德算法查找最短路径时,只允许环路的权值为负数,其它路径的权值必须为非负数,否则算法执行过程会出错。 弗洛伊德算法的实现思路 弗洛伊德算法是基于 动态规划算法实现的,接下来我们以在图 1 所示的有向加权图中查找各个顶点之间的最短路径为例,讲解弗洛伊德算法的实现思
-
我假设没有愚蠢的问题,所以这里有一个我找不到直接答案的问题。 现在的情况 我目前有一个运行1.15的Kubernetes集群。AKS上的x,通过Terraform部署和管理。AKS最近宣布Azure将在AKS上停用Kubernetes的1.15版本,我需要将集群升级到1.16或更高版本。现在,据我所知,直接在Azure中升级集群不会对集群的内容产生任何影响,即节点、豆荚、秘密和当前在那里的所有其他
-
本文向大家介绍基于Python实现迪杰斯特拉和弗洛伊德算法,包括了基于Python实现迪杰斯特拉和弗洛伊德算法的使用技巧和注意事项,需要的朋友参考一下 图搜索之基于Python的迪杰斯特拉算法和弗洛伊德算法,供大家参考,具体内容如下 Djstela算法 FLOYD算法 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
我的kubernetes部署中有一个多容器吊舱: java redis nginx 对于每一个集装箱,普罗米修斯出口商也有一个集装箱。 问题是,如果annotations部分只支持每个pod一个端口,我如何向Prometheus公开这些端口? 但是我需要这样的东西: 也许还有其他方法可以从我的多容器pod中获取所有指标?提前感谢您的帮助。
-
我在Linux服务器的Kubernetes上安装了带有2或3个pod的Spring Boot应用程序。为了监控它,我也安装了普罗米修斯。目前,从应用程序到普罗米修斯的衡量标准进展顺利。 但我怀疑普罗米修斯只从一个豆荚中提取指标。对于普罗米修斯配置文件中的如下作业,普罗米修斯是否只从一个pod中获取指标?我怎样才能让普罗米修斯同时刮掉所有的豆荚呢?
-
据我所知,作业对象应该在一定时间后收获豆荚。但是在我的GKE集群(库伯内特斯1.1.8)上,“kubectl get pods-a”似乎可以列出几天前的豆荚。 所有这些都是使用乔布斯API创建的。 我确实注意到在使用 kubectl 删除作业后,pod 也被删除了。 我在这里主要担心的是,我将在批量作业中在集群上运行成千上万个pod,并且不想让内部待办系统过载。