
为什么 .net 对字符串使用 UTF16 编码,但默认使用 UTF-8 作为保存文件?

从这里
本质上,字符串使用UTF-16字符编码形式
但是当保存与流编写器:
此构造函数创建一个具有 UTF-8 编码的 StreamWriter,而不使用字节顺序标记 (BOM),
我看到了这个示例(断开的链接已删除):
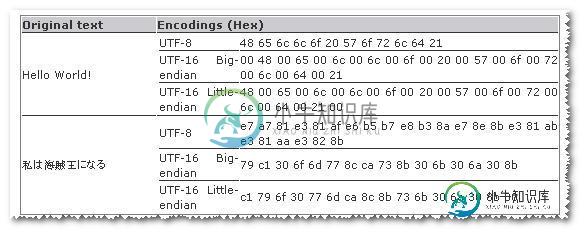
看起来有些字符串的< code>utf8更小,而有些字符串的< code>utf-16更小。
- 那么,为什么.net使用
utf16作为字符串的默认编码,而使用utf8保存文件呢
谢谢你。
p、 我已经读过那篇著名的文章了
共有3个答案

UTF-8是文本存储和传输的默认格式,因为对于大多数语言来说,它是一种相对紧凑的格式(有些语言在UTF-16中比在UTF-8中更紧凑)。每种特定的语言都有更有效的编码。
UTF-16用于内存字符串,因为它可以更快地解析每个字符并直接映射到unicode字符类和其他表。Windows中的所有字符串函数都使用UTF-16,并且多年来一直使用。

和许多“为什么选择这个”的问题一样,这是由历史决定的。1993年,Windows成为其核心的Unicode操作系统。当时,Unicode仍然只有65535个代码点的代码空间,现在称为UCS。直到1996年,Unicode才获得补充平面,将编码空间扩展到一百万个码点。和代理对,使它们适合16位编码,从而建立了utf-16标准。
.NET字符串是utf-16,因为它非常适合操作系统编码,不需要转换。
utf-8的历史更加模糊。RFC-3629是从1993年11月开始的Windows NT版本,它肯定已经过时了。它花了一段时间才站稳脚跟,互联网是工具。

如果您乐于忽略代理对(或者等价地,您的应用程序需要基本多语言平面之外的字符的可能性),UTF-16有一些很好的属性,基本上是因为每个代码单元总是需要两个字节,并且每个代码单元在一个代码单元中表示所有BMP字符。
考虑基元类型<code>char</code>。如果我们使用UTF-8作为内存中的表示,并希望处理所有Unicode字符,那么它应该有多大?它可能多达4个字节…这意味着我们总是需要分配4个字节。在这一点上,我们不妨使用UTF-32!
当然,我们可以使用UTF-32作为< code>char表示法,但在< code>string表示法中使用UTF-8,并随着我们的进行进行转换。
UTF-16的两个缺点是:
- 每个Unicode字符的代码单位数是可变的,因为并非所有字符都在BMP中。在表情符号流行之前,这并没有影响许多日常使用的应用程序。如今,对于消息应用等,使用UTF-16的开发人员确实需要了解代理对
- 对于普通ASCII(至少在西方有很多文本),它占用的空间是等效UTF-8编码文本的两倍
(顺便说一句,我相信Windows使用UTF-16作为Unicode数据,这是有意义的。NET出于互操作的原因效仿。不过,这只是将问题推到了一步。)
考虑到代理对的问题,我怀疑如果一种语言/平台是从零开始设计的,没有互操作需求(但是基于Unicode的文本处理),UTF-16不会是最好的选择。UTF-8(如果您希望提高内存效率,并且不介意到达第n个字符时的处理复杂性)或UTF-32(反之)将是更好的选择。(由于不同的规范化形式,即使到达第n个字符也有“问题”。文本很难...)
-
问题内容: 我有一个带有“ñ”字符的字符串,并且我有一些问题。我需要将此字符串编码为UTF-8编码。我已经通过这种方式尝试过,但是没有用: 如何将该字符串编码为utf-8? 问题答案: Java中的对象使用无法修改的UTF-16编码。 唯一可以使用不同编码的是。因此,如果你需要UTF-8数据,则需要一个。如果你有一个包含意外数据的,则问题出在较早的地方,该错误地将一些二进制数据错误地转换为a (即
-
问题内容: 他们在“ PHP Cookbook”中说(第589页),要将传出数据的char编码正确设置为utf-8,必须将配置编辑为utf-8。 但是,我在中找不到此配置。我是否应该简单地添加一行内容? 我有一个。如您所见(),目前尚未激活。我应该删除分号并将其设置为吗?这样可以处理默认编码吗? 我还发现了其他我不知道该怎么做的编码指令: 有什么原因为什么我不能简单地将它们全部替换为? 问题答案:
-
问题内容: 我目前正在从事一个项目,我不使用常规的MySQL查询,而是继续学习如何使用PDO。 我有一个称为参赛者的表,数据库,表和所有列均位于utf-8中。我的参赛者表中有10个条目,而它们的“名称”列中包含诸如åäö之类的字符。 现在,当我从数据库中获取一个条目并使用var_dump的名称时,我得到了一个很好的结果,即一个包含所有特殊字符的字符串。但是我需要做的是按字符分割字符串,将它们放入数
-
我有一个使用UTF-8编码的XML文件,在XML声明中正确指定。 该文件包括一些标准ASCII以外的字符。特别地,它包括带元音字符的o。它已经正确地将其表示为一个2字节的UTF-8序列c0b6。但在IE或Firefix中打开时,它会显示为除法符号“÷”,即使我已经将默认字体设置为Arial Unicode。浏览器正在正确地检测到(显式指定的)UTF-8编码。 显示如下所示: 我可以上传文件,但它相
-
问题内容: 我遇到了这行遗留代码,我试图找出这些遗留代码: 据我了解,它是使用相同的charSet进行编码和解码。 这与以下内容有何不同? 在任何情况下,两条生产线的输出将不同? ps:只是要澄清一下,是的,我知道Joel Spolsky撰写的关于编码 的出色文章! 问题答案: 这可能是很复杂的方式 这缩短了String,而所使用的基础char []则更长。 但是,更具体地说,将检查每个字符是否都
-
本章是由 Alex Cabal 最初撰写在 PHP Best Practices 中的,我们使用它作为进行建议的基础。 这不是在开玩笑。请小心、仔细并且前后一致地处理它。 目前,PHP 仍未在底层实现对 Unicode 的支持。虽然有很多途径可以确保 UTF-8 字符串能够被正确地处理,但这并不是很简单的事情,通常需要对 Web 应用进行全方面的检查,从 HTML 到 SQL 再到 PHP。我们将