
使用Python OneDrive SDK将文件上载到MS SharePoint

是否可以将一个文件上传到一个网站的共享文档库
带有[Python OneDrive]的Microsoft SharePoint站点
软件开发包
?
本文件说它应该
是(在第一句中),但我不能使它工作。
我可以通过Azure AD进行身份验证并上传到OneDrive文件夹,
但是当我试图上传到一个SharePoint文件夹时,我总是得到这个
错误:
“类型异常”Microsoft.IdentityModel.Tokens.
引发了AudienceUriValidationFailedException‘
我使用的代码返回一个带有错误的对象:
(...authentication...)
client = onedrivesdk.OneDriveClient('https://{tenant}.sharepoint.com/{site}/_api/v2.0/', auth, http)
client.item(path='/drive/special/documents').children['test.xlsx'].upload('test.xlsx')
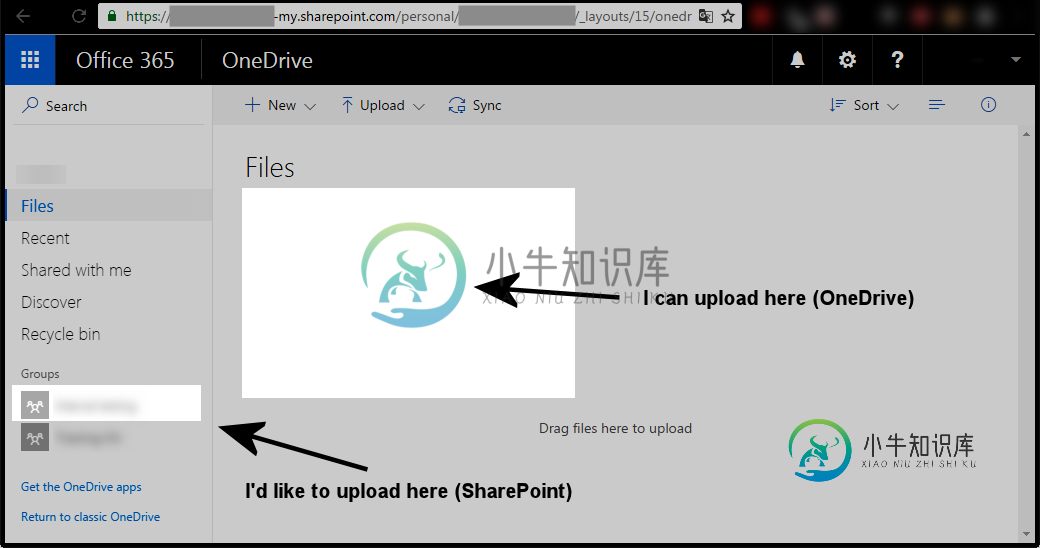
I can successfully upload to https://{tenant}-my.sharepoint.com/_api/v2.0/
(notice the ” -my ” after the {tenant}) with the following code:
client = onedrivesdk.OneDriveClient('https://{tenant}-my.sharepoint.com/_api/v2.0/', auth, http)
returned_item = client.item(drive='me', id='root').children['test.xlsx'].upload('test.xlsx')
如何将同一个文件上载到SharePoint网站?
更新:这是我的完整代码和输出。敏感原始数据
替换为类似格式的胡言乱语
import re
import onedrivesdk
from onedrivesdk.helpers.resource_discovery import ResourceDiscoveryRequest
# our domain (not the original)
redirect_uri = 'https://example.ourdomain.net/'
# our client id (not the original)
client_id = "a1234567-1ab2-1234-a123-ab1234abc123"
# our client secret (not the original)
client_secret = 'ABCaDEFGbHcd0e1I2fghJijkL3mn4M5NO67P8Qopq+r='
resource = 'https://api.office.com/discovery/'
auth_server_url = 'https://login.microsoftonline.com/common/oauth2/authorize'
auth_token_url = 'https://login.microsoftonline.com/common/oauth2/token'
http = onedrivesdk.HttpProvider()
auth = onedrivesdk.AuthProvider(http_provider=http, client_id=client_id,
auth_server_url=auth_server_url,
auth_token_url=auth_token_url)
should_authenticate_via_browser = False
try:
# Look for a saved session. If not found, we'll have to
# authenticate by opening the browser.
auth.load_session()
auth.refresh_token()
except FileNotFoundError as e:
should_authenticate_via_browser = True
pass
if should_authenticate_via_browser:
auth_url = auth.get_auth_url(redirect_uri)
code = ''
while not re.match(r'[a-zA-Z0-9_-]+', code):
# Ask for the code
print('Paste this URL into your browser, approve the app\'s access.')
print('Copy the resulting URL and paste it below.')
print(auth_url)
code = input('Paste code here: ')
# Parse code from URL if necessary
if re.match(r'.*?code=([a-zA-Z0-9_-]+).*', code):
code = re.sub(r'.*?code=([a-zA-Z0-9_-]*).*', r'\1', code)
auth.authenticate(code, redirect_uri, client_secret, resource=resource)
# If you have access to more than one service, you'll need to decide
# which ServiceInfo to use instead of just using the first one, as below.
service_info = ResourceDiscoveryRequest().get_service_info(auth.access_token)[0]
auth.redeem_refresh_token(service_info.service_resource_id)
auth.save_session() # Save session into a local file.
# Doesn't work
client = onedrivesdk.OneDriveClient(
'https://{tenant}.sharepoint.com/sites/{site}/_api/v2.0/', auth, http)
returned_item = client.item(path='/drive/special/documents')
.children['test.xlsx']
.upload('test.xlsx')
print(returned_item._prop_dict['error_description'])
# Works, uploads to OneDrive instead of SharePoint site
client2 = onedrivesdk.OneDriveClient(
'https://{tenant}-my.sharepoint.com/_api/v2.0/', auth, http)
returned_item2 = client2.item(drive='me', id='root')
.children['test.xlsx']
.upload('test.xlsx')
print(returned_item2.web_url)
Output:
Exception of type 'Microsoft.IdentityModel.Tokens.AudienceUriValidationFailedException' was thrown.
https://{tenant}-my.sharepoint.com/personal/user_domain_net/_layouts/15/WopiFrame.aspx?sourcedoc=%1ABCDE2345-67F8-9012-3G45-6H78IJKL9M01%2N&file=test.xlsx&action=default
问题答案:
在sytech的帮助下,我终于找到了一个解决方案。我最初的问题的答案是使用原始的[Python]
OneDrive SDK](https://github.com/OneDrive/OneDrive-sdk-python)
,不是
可能将文件上载到SharePoint的“共享文档”文件夹
Onlinesite(在撰写本文时):当SDK查询[**资源发现 服务**](https://dev.onedrive.com/auth/aad_oauth.htm#步骤-3-发现-- onedrive for business resource uri),它会删除服务api版本不是v2.0。但是,我得到了SharePoint服务使用“v1.0”,所以它被删除了,尽管可以使用API v2.0访问它我也是。
但是,通过扩展“ResourceDiscoveryRequest”类(在
OneDrive SDK),我们可以为此创建一个解决方法。我设法上传了一个文件这样:
import json
import re
import onedrivesdk
import requests
from onedrivesdk.helpers.resource_discovery import ResourceDiscoveryRequest, \
ServiceInfo
# our domain (not the original)
redirect_uri = 'https://example.ourdomain.net/'
# our client id (not the original)
client_id = "a1234567-1ab2-1234-a123-ab1234abc123"
# our client secret (not the original)
client_secret = 'ABCaDEFGbHcd0e1I2fghJijkL3mn4M5NO67P8Qopq+r='
resource = 'https://api.office.com/discovery/'
auth_server_url = 'https://login.microsoftonline.com/common/oauth2/authorize'
auth_token_url = 'https://login.microsoftonline.com/common/oauth2/token'
# our sharepoint URL (not the original)
sharepoint_base_url = 'https://{tenant}.sharepoint.com/'
# our site URL (not the original)
sharepoint_site_url = sharepoint_base_url + 'sites/{site}'
file_to_upload = 'C:/test.xlsx'
target_filename = 'test.xlsx'
class AnyVersionResourceDiscoveryRequest(ResourceDiscoveryRequest):
def get_all_service_info(self, access_token, sharepoint_base_url):
headers = {'Authorization': 'Bearer ' + access_token}
response = json.loads(requests.get(self._discovery_service_url,
headers=headers).text)
service_info_list = [ServiceInfo(x) for x in response['value']]
# Get all services, not just the ones with service_api_version 'v2.0'
# Filter only on service_resource_id
sharepoint_services = \
[si for si in service_info_list
if si.service_resource_id == sharepoint_base_url]
return sharepoint_services
http = onedrivesdk.HttpProvider()
auth = onedrivesdk.AuthProvider(http_provider=http, client_id=client_id,
auth_server_url=auth_server_url,
auth_token_url=auth_token_url)
should_authenticate_via_browser = False
try:
# Look for a saved session. If not found, we'll have to
# authenticate by opening the browser.
auth.load_session()
auth.refresh_token()
except FileNotFoundError as e:
should_authenticate_via_browser = True
pass
if should_authenticate_via_browser:
auth_url = auth.get_auth_url(redirect_uri)
code = ''
while not re.match(r'[a-zA-Z0-9_-]+', code):
# Ask for the code
print('Paste this URL into your browser, approve the app\'s access.')
print('Copy the resulting URL and paste it below.')
print(auth_url)
code = input('Paste code here: ')
# Parse code from URL if necessary
if re.match(r'.*?code=([a-zA-Z0-9_-]+).*', code):
code = re.sub(r'.*?code=([a-zA-Z0-9_-]*).*', r'\1', code)
auth.authenticate(code, redirect_uri, client_secret, resource=resource)
service_info = AnyVersionResourceDiscoveryRequest().\
get_all_service_info(auth.access_token, sharepoint_base_url)[0]
auth.redeem_refresh_token(service_info.service_resource_id)
auth.save_session()
client = onedrivesdk.OneDriveClient(sharepoint_site_url + '/_api/v2.0/',
auth, http)
# Get the drive ID of the Documents folder.
documents_drive_id = [x['id']
for x
in client.drives.get()._prop_list
if x['name'] == 'Documents'][0]
items = client.item(drive=documents_drive_id, id='root')
# Upload file
uploaded_file_info = items.children[target_filename].upload(file_to_upload)
Authenticating for a different service gives you a different token.
-
根据SkyDrive api(http://msdn.microsoft.com/en-us/library/live/hh826531.aspx#uploading_files),我在帖子请求的正文中以字节[]传递图像的内容。文件创建发生在skyDrive服务器上,但当我在skyDrive中打开它时,它说“文件应用程序被损坏或损坏”。 请求的正文 --A300x内容处理:表单数据;name=“f
-
我尝试使用C#将文件上传到FTP服务器。文件已上传,但字节为零。
-
我在尝试将文件上传到我的S3存储桶时遇到了问题。一切正常,除了我的文件参数似乎不合适。我正在使用Amazon S3 sdk从nodejs上传到s3。 以下是我的路线设置: 这是个项目。upload()函数: 将“Body”参数设置为类似“hello”的字符串可以正常工作。根据doc,Body必须获取(Buffer、类型化数组、Blob、String、ReadableStream)对象数据。但是,上
-
我正在尝试上传一个文本文件(也尝试了PDF等)到Salesforce。文本文件包含“Hello World”。 这是我正在使用的代码 这将导致以下看起来符合Salesforce指导原则的请求正文:https://developer.Salesforce.com/docs/atlas.en-us.api_rest.meta/api_rest/dome_sobject_insert_update_bl
-
我正在使用wget命令将文件上载到http。 这是我的错误消息: `FOLDER\u NAME'解析示例。网络。。。我连接到示例。净值| 10.00.00.009 |:80。。。有联系的。HTTP请求已发送,正在等待响应。。。401连接示例时拒绝访问。净值| 10.00.00.009 |:80。。。有联系的。HTTP请求已发送,正在等待响应。。。500内部服务器错误 请帮助解决此错误。 注意:服务
-
httpclient,HttpTime 4.1.3 我试图通过http将文件上载到远程服务器,但没有成功。 这是我的代码: 服务器是Solr。 这是为了替换像这样调用的工作bash脚本, <代码>卷曲http://localhost:8080/solr/update/extract?literal.id=bububu 如果我尝试设置“内容类型”“多部分/表单数据”,接收部分会说没有边界(这是真的)
-
但事实证明,Firebase无法从服务器端上传文件,正如它在文档中明确说明的那样: Firebase存储不包括在服务器端Firebase npm模块中。相反,您可以使用gcloud Node.js客户机。 我的第二次尝试是使用库,就像文档中提到的:
-
我想添加时间字符串的文件名,我上传到谷歌驱动器使用pydrive的结束。基本上,我尝试编写以下代码,但我不知道如何适应新的文件变量: 获取类型错误:应为str、字节或os。类路径对象,而不是GoogleDriveFile