
在扫描的文档中分割文本行

我正在尝试寻找一种方法来打破已自适应阈值的扫描文档中的文本行。现在,我将文档的像素值存储为0到255之间的无符号整数,并获取每行像素的平均值,然后根据像素值的平均值是否为0将行划分为多个范围大于250,然后将其取为各行范围的中值。但是,此方法有时会失败,因为图像上可能会出现黑色斑点。
有没有更好的抗噪方法来执行此任务?
编辑:这是一些代码。“扭曲”是原始图像的名称,“剪切”是我要分割图像的位置。
warped = threshold_adaptive(warped, 250, offset = 10)
warped = warped.astype("uint8") * 255
# get areas where we can split image on whitespace to make OCR more accurate
color_level = np.array([np.sum(line) / len(line) for line in warped])
cuts = []
i = 0
while(i < len(color_level)):
if color_level[i] > 250:
begin = i
while(color_level[i] > 250):
i += 1
cuts.append((i + begin)/2) # middle of the whitespace region
else:
i += 1
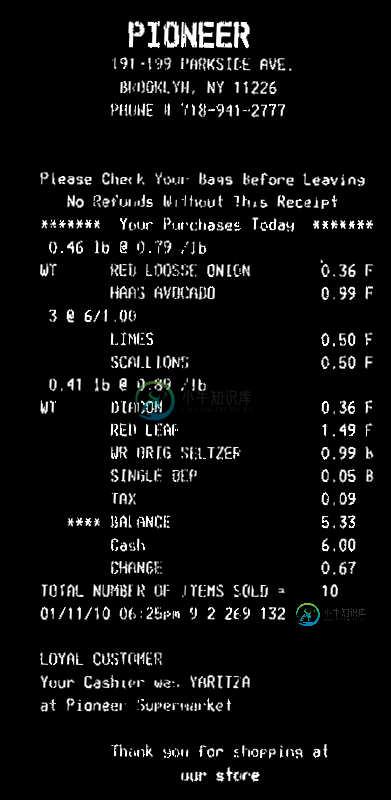
编辑2:添加了示例图像

问题答案:
在输入图像中,您需要将文本设置为白色,将背景设置为黑色
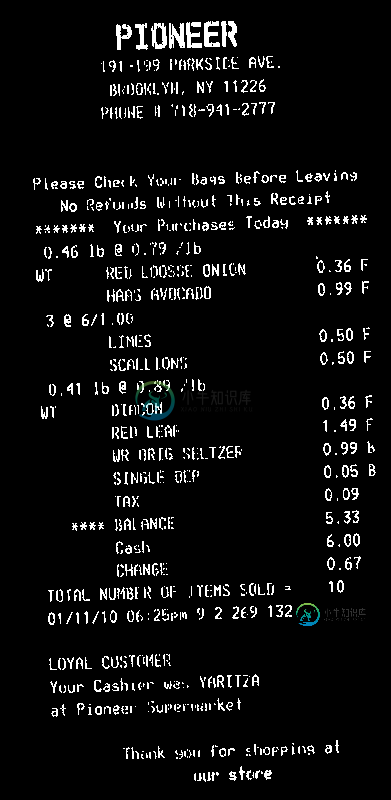
然后,您需要计算账单的旋转角度。一种简单的方法是找到minAreaRect所有白点(findNonZero),然后得到:
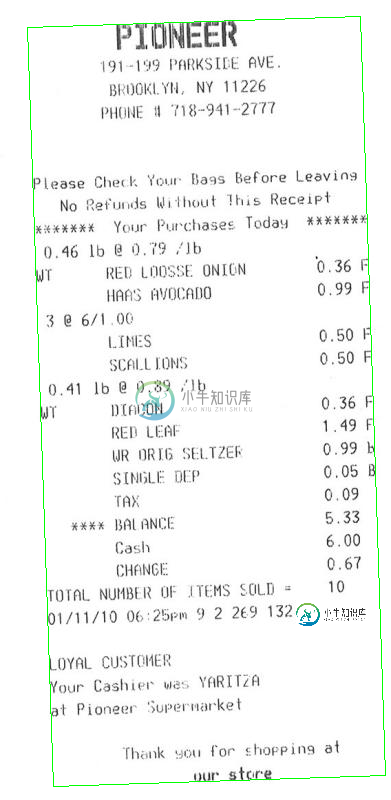
然后,您可以旋转帐单,使文本为水平:
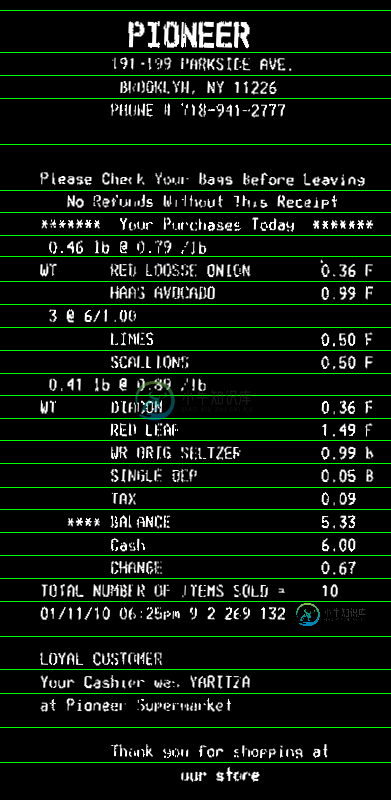
现在您可以计算水平投影(reduce)。您可以在每行中取平均值。th在直方图上应用阈值以解决图像中的一些噪点(在此我使用了0,即没有噪点)。仅背景的行将具有值>0,文本行在0直方图中将具有值。然后,获取直方图中白色bin的每个连续序列的平均bin坐标。那将是y您行的坐标:
这里的代码。它使用C ++,但是由于大多数工作都是使用OpenCV函数,因此应该可以轻松转换为Python。至少,您可以将其用作参考:
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
int main()
{
// Read image
Mat3b img = imread("path_to_image");
// Binarize image. Text is white, background is black
Mat1b bin;
cvtColor(img, bin, COLOR_BGR2GRAY);
bin = bin < 200;
// Find all white pixels
vector<Point> pts;
findNonZero(bin, pts);
// Get rotated rect of white pixels
RotatedRect box = minAreaRect(pts);
if (box.size.width > box.size.height)
{
swap(box.size.width, box.size.height);
box.angle += 90.f;
}
Point2f vertices[4];
box.points(vertices);
for (int i = 0; i < 4; ++i)
{
line(img, vertices[i], vertices[(i + 1) % 4], Scalar(0, 255, 0));
}
// Rotate the image according to the found angle
Mat1b rotated;
Mat M = getRotationMatrix2D(box.center, box.angle, 1.0);
warpAffine(bin, rotated, M, bin.size());
// Compute horizontal projections
Mat1f horProj;
reduce(rotated, horProj, 1, CV_REDUCE_AVG);
// Remove noise in histogram. White bins identify space lines, black bins identify text lines
float th = 0;
Mat1b hist = horProj <= th;
// Get mean coordinate of white white pixels groups
vector<int> ycoords;
int y = 0;
int count = 0;
bool isSpace = false;
for (int i = 0; i < rotated.rows; ++i)
{
if (!isSpace)
{
if (hist(i))
{
isSpace = true;
count = 1;
y = i;
}
}
else
{
if (!hist(i))
{
isSpace = false;
ycoords.push_back(y / count);
}
else
{
y += i;
count++;
}
}
}
// Draw line as final result
Mat3b result;
cvtColor(rotated, result, COLOR_GRAY2BGR);
for (int i = 0; i < ycoords.size(); ++i)
{
line(result, Point(0, ycoords[i]), Point(result.cols, ycoords[i]), Scalar(0, 255, 0));
}
return 0;
}
-
我已经做了很多关于这个主题的研究,但我发现的一切都是每次“使用的函数getOverContent的压模”。我做了这个,但还是不行。 我做了一个程序,合并在一起的PDF的汇编,然后它分页这个新的文件(我希望你可以跟随我写的)。原始PDF是自制的(直接保存在PDF中)或不是(扫描)。这是最后几个有麻烦的地方。分页显示在第一个,但不是在秒(它可能存在,但它应该在图像后面)! 这里是分页的代码,有人知道我
-
我正在尝试编写一个应用程序,它将占用一个非常大的sql文本文件~60GB(2.57亿行),并将每个COPY语句拆分为单独的文本文件。 但是,我目前使用的代码会导致OutOfMemoryError,因为行超过了扫描仪缓冲区限制。第一个语句将是4000万行。 请提供建议,说明这是执行此操作的错误方法还是对现有方法的修改。 谢啦
-
主要内容:分割PDF文档中的页面,示例在前一章中,我们已经看到了如何将JavaScript添加到PDF文档。 现在来学习如何将给定的PDF文档分成多个文档。 分割PDF文档中的页面 可以使用类将给定的PDF文档分割为多个PDF文档。 该类用于将给定的PDF文档分成几个其他文档。 以下是拆分现有PDF文档的步骤 第1步:加载现有的PDF文档 使用类的静态方法加载现有的PDF文档。 此方法接受一个文件对象作为参数,因为这是一个静态方法,可
-
我正在处理这样的文本文件: 第01章 乱数假文 多洛·希特·阿梅特,一位杰出的献身者,他是一位临时顾问 第02章 献祭 临时行政长官 第03章 等等,多洛尔·马格纳·阿利夸。 带有分隔符,如“章”、“章”、“章”等...和1或2位数(“第1章”或“第01章”)。 我使用和 现在我需要拆分我的字符串,以便获得“第二十章”的文本。 对于第02章,这将是: 献祭 临时行政长官 我是Python新手,我读
-
问题内容: 我要分割以下数据。 获取每个值: 1 167 2 ‘LT2A’ 45 ‘每周’ ‘1,2,3,4,5,6,7,8,9,10,11,12,13’ 我使用的扫描仪类来做到这一点,用 , 作为分隔符。但由于最后一个字符串,我遇到了问题。 因此,我想就如何拆分这些数据提出一些建议。 我也尝试过使用’作为分隔符,但字符串包含不带’的数据。 这个问题是非常适合我的需求的,但是如果有人可以给我一些建
-
问题内容: 我想像这将是一个简单的任务,但在以前的StackOverflow问题中我找不到我正在寻找的东西…… 我有一个专有格式的大文本文件,看起来像这样: 依此类推。 文本文件的大小从10kb到100mb不等。我需要用定界符分割此文件。如何基于块处理每个文件? 问题答案: 您可以使用itertools.groupby对列表中出现的行进行分组: 产量 或者,要处理组,您实际上不需要转换为列表: