
我如何找到生产系统中Python进程中正在使用内存的内容?

我的生产系统偶尔会出现内存泄漏,而这是我在开发环境中无法复制的。我在开发环境中使用了Python内存事件探查器(特别是Heapy),但取得了一些成功,但是它无法帮助我解决无法重现的问题,并且我不愿意使用Heapy来检测生产系统需要花点时间来完成它的工作,并且它的线程化远程接口在我们的服务器中无法正常工作。
我想我想要的是一种转储生产Python进程(或至少gc.get_objects)快照,然后离线分析快照以查看其在哪里使用内存的方法。
我如何获得像这样的python进程的核心转储?
一旦有了一个,我该如何做些有用的事情?
问题答案:
我将从最近的经历中进一步了解布雷特的回答。推土机包是
很好的维护,尽管进步,像添加tracemalloc在Python 3.4
STDLIB,其gc.get_objects计数图是我去到的工具来解决内存泄漏。在下面,我使用dozer > 0.7在撰写本文时尚未发布的内容(好吧,因为我最近在那里做了一些修复)。
让我们看一个不平凡的内存泄漏。我将在此处使用Celery
4.4,并最终揭示导致泄漏的功能(由于这是错误/功能,因此可以将其称为纯粹的错误配置,由无知引起)。所以这是一个Python 3.6 VENV
在哪里pip install celery < 4.5。并具有以下模块。
演示
import time
import celery
redis_dsn = 'redis://localhost'
app = celery.Celery('demo', broker=redis_dsn, backend=redis_dsn)
@app.task
def subtask():
pass
@app.task
def task():
for i in range(10_000):
subtask.delay()
time.sleep(0.01)
if __name__ == '__main__':
task.delay().get()
基本上是一个计划一堆子任务的任务。有什么问题吗?
我将用于procpath分析Celery节点的内存消耗。pip install procpath。我有4个终端:
procpath record -d celery.sqlite -i1 "$..children[?('celery' in @.cmdline)]"记录Celery节点的进程树统计信息docker run --rm -it -p 6379:6379 redis运行Redis,它将充当Celery经纪人和结果后端celery -A demo worker --concurrency 2用2个工人运行节点python demo.py最后运行示例
(4)将在2分钟内完成。
Then I use sqliteviz (pre-built
version) to visualise what procpath
has recorder. I drop the celery.sqlite there and use this query:
SELECT datetime(ts, 'unixepoch', 'localtime') ts, stat_pid, stat_rss / 256.0 rss
FROM record
And in sqliteviz I create a line chart trace with X=ts, Y=rss, and add
split transform By=stat_pid. The result chart is:
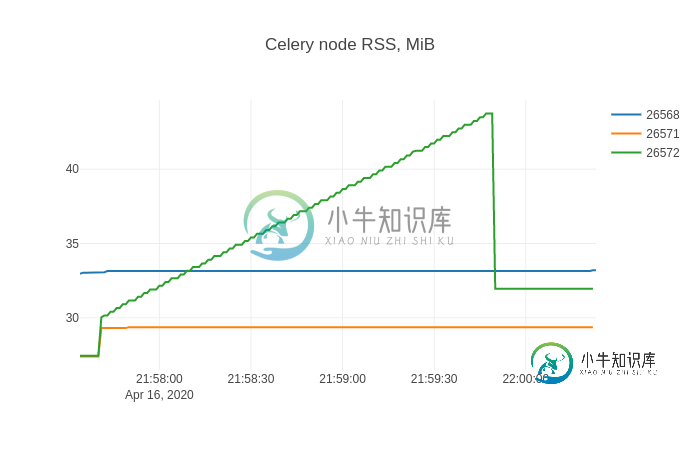
This shape is likely pretty familiar to anyone who fought with memory leaks.
Finding leaking objects
Now it’s time for dozer. I’ll show non-instrumented case (and you can
instrument your code in similar way if you can). To inject Dozer server into
target process I’ll use Pyrasite. There
are two things to know about it:
- To run it, ptrace has to be configured as “classic ptrace permissions”:
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope, which is may be a security risk - There are non-zero chances that your target Python process will crash
With that caveat I:
pip install https://github.com/mgedmin/dozer/archive/3ca74bd8.zip(that’s to-be 0.8 I mentioned above)pip install pillow(whichdozeruses for charting)pip install pyrasite
After that I can get Python shell in the target process:
pyrasite-shell 26572
And inject the following, which will run Dozer’s WSGI application using
stdlib’s wsgiref‘s server.
import threading
import wsgiref.simple_server
import dozer
def run_dozer():
app = dozer.Dozer(app=None, path='/')
with wsgiref.simple_server.make_server('', 8000, app) as httpd:
print('Serving Dozer on port 8000...')
httpd.serve_forever()
threading.Thread(target=run_dozer, daemon=True).start()
Opening http://localhost:8000 in a browser there should see something like:
After that I run python demo.py from (4) again and wait for it to finish.
Then in Dozer I set “Floor” to 5000, and here’s what I see:
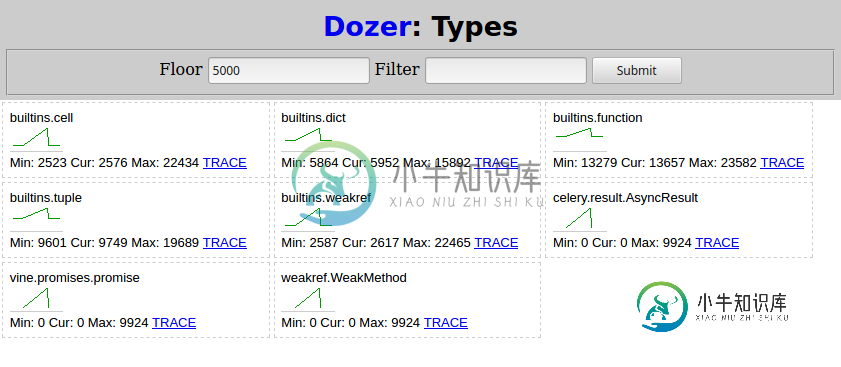
Two types related to Celery grow as the subtask are scheduled:
celery.result.AsyncResultvine.promises.promise
weakref.WeakMethod has the same shape and numbers and must be caused by the
same thing.
Finding root cause
At this point from the leaking types and the trends it may be already clear
what’s going on in your case. If it’s not, Dozer has “TRACE” link per type,
which allows tracing (e.g. seeing object’s attributes) chosen object’s
referrers (gc.get_referrers) and referents (gc.get_referents), and
continue the process again traversing the graph.
But a picture says a thousand words, right? So I’ll show how to use
objgraph to render chosen object’s
dependency graph.
pip install objgraphapt-get install graphviz
Then:
- I run
python demo.pyfrom (4) again - in Dozer I set
floor=0,filter=AsyncResult - and click “TRACE” which should yield
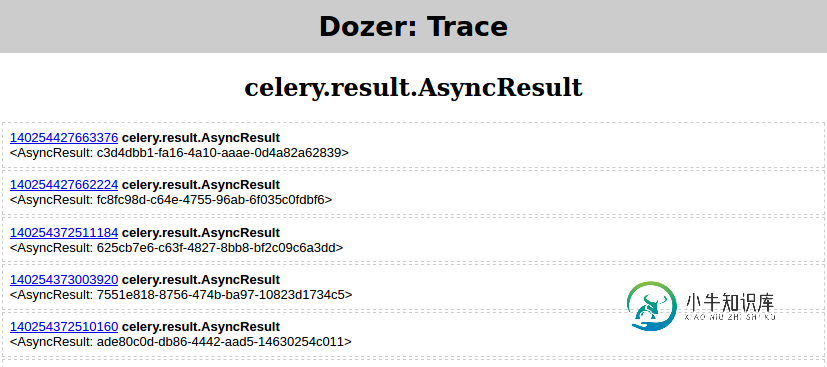
Then in Pyrasite shell run:
objgraph.show_backrefs([objgraph.at(140254427663376)], filename='backref.png')
The PNG file should contain:
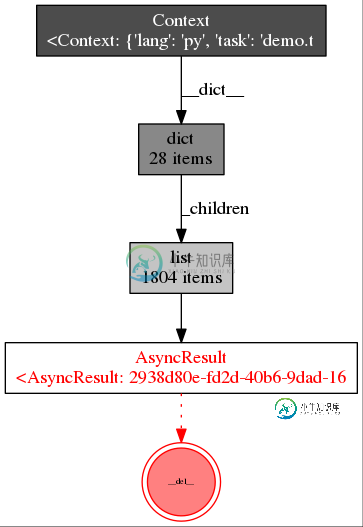
Basically there’s some Context object containing a list called _children
that in turn is containing many instances of celery.result.AsyncResult,
which leak. Changing Filter=celery.*context in Dozer here’s what I see:
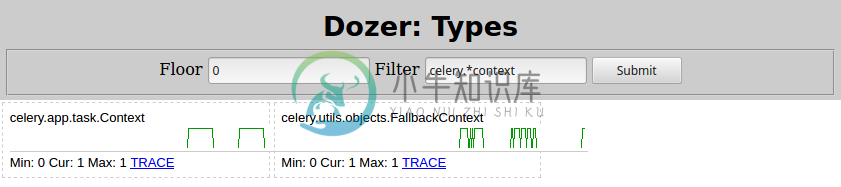
So the culprit is celery.app.task.Context. Searching that type would
certainly lead you to Celery task
page.
Quickly searching for “children” there, here’s what it says:
trail = TrueIf enabled the request will keep track of subtasks started by this task, and
this information will be sent with the result (result.children).
Disabling the trail by setting trail=False like:
@app.task(trail=False)
def task():
for i in range(10_000):
subtask.delay()
time.sleep(0.01)
Then restarting the Celery node from (3) and python demo.py from (4) yet
again, shows this memory consumption.
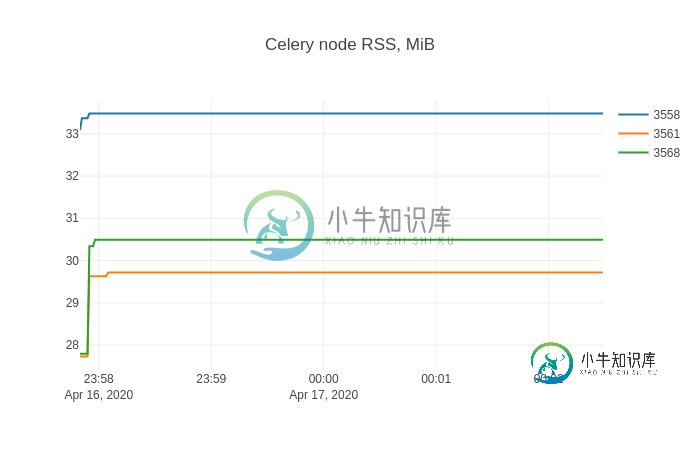
Problem solved!
-
问题内容: 我在具有16GB Ram和64位OS的Linux机器上运行Python 2.7。我编写的python脚本可能会将过多的数据加载到内存中,这使计算机的运行速度降低到我什至无法杀死进程的地步。 虽然可以通过以下方式限制内存: 在运行脚本之前,请在外壳程序中添加一个限制选项。在我到处看的地方,该模块具有与相同的功能。但是调用: 在我的脚本开始时,绝对没有任何作用。即使将值设置为12000,也
-
问题内容: 我认为我的LAMP应用程序中可能发生内存泄漏(内存用完,交换开始使用,等等)。如果我可以看到各个进程使用了多少内存,则可以帮助我解决问题。有没有办法让我在* nix中查看此信息? 问题答案: 获得正确的内存使用情况比人们想象的要棘手。我能找到的最好方法是: 其中“ PROCESS”是要检查的过程的名称,而“ TYPE”是以下之一: :常驻内存使用情况,该进程使用的所有内存,包括该进
-
问题内容: Python程序是否有办法确定当前正在使用多少内存?我已经看到了有关单个对象的内存使用情况的讨论,但是我需要的是该过程的总内存使用情况,以便可以确定何时需要开始丢弃缓存的数据。 问题答案: 这是适用于各种操作系统(包括Linux,Windows 7等)的有用解决方案: 在我当前使用psutil 5.6.3安装的python 2.7中,最后一行应为 相反(API发生了变化)。 注意:如果
-
Python内存由Python私有堆空间管理。所有Python对象和数据结构都位于私有堆中。程序员无权访问此私有堆,解释器负责处理此私有堆。 Python对象的Python堆空间分配由Python内存管理器完成。核心API提供了一些程序员编写代码的工具。 Python还有一个内置的垃圾收集器,它可以回收所有未使用的内存并释放内存并使其可用于堆空间。
-
问题内容: 我给自己做了一个小模块,碰巧经常使用它。每当我需要它时,只需将其复制到要使用的文件夹中即可。由于我很懒,所以我想安装它,以便可以从任何地方调用它,即使是交互式提示也是如此。因此,我读了一些有关在此处安装的信息,并得出结论,我需要将文件复制到/usr/local/lib/python2.7/site- packages。但是,这似乎没有任何作用。 有人知道我需要将模块复制到哪里才能在系统
-
我的问题是,如果我从java代码调用Shell脚本,脚本使用的内存,是从JVM堆空间分配,还是使用系统内存空间。