
插值缺失值2d python

我有一个二维数组(或矩阵,如果愿意的话),其中一些缺失值表示为 NaN。缺失值通常沿着一个轴位于一条带中,例如:
1 2 3 NaN 5
2 3 4 Nan 6
3 4 Nan Nan 7
4 5 Nan Nan 8
5 6 7 8 9
我想NaN用一些合理的数字代替。
我研究了delaunay三角剖分,但是发现的文档很少。
我尝试使用astropy‘convolve’,因为它支持2d数组的使用,并且非常简单。问题在于,卷积不是插值,而是将所有值都移向平均值(可以通过使用窄核来缓解)。
这个问题应该是该帖子的自然二维扩展。有没有一种方法可以插值NaN二维数组中的/缺失值?
问题答案:
是的,您可以使用scipy.interpolate.griddata和屏蔽数组,还可以选择使用参数的插值类型,method通常'cubic'可以很好地完成工作:
import numpy as np
from scipy import interpolate
#Let's create some random data
array = np.random.random_integers(0,10,(10,10)).astype(float)
#values grater then 7 goes to np.nan
array[array>7] = np.nan
看起来像这样plt.imshow(array,interpolation='nearest') :
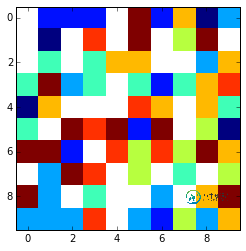
x = np.arange(0, array.shape[1])
y = np.arange(0, array.shape[0])
#mask invalid values
array = np.ma.masked_invalid(array)
xx, yy = np.meshgrid(x, y)
#get only the valid values
x1 = xx[~array.mask]
y1 = yy[~array.mask]
newarr = array[~array.mask]
GD1 = interpolate.griddata((x1, y1), newarr.ravel(),
(xx, yy),
method='cubic')
这是最终结果:
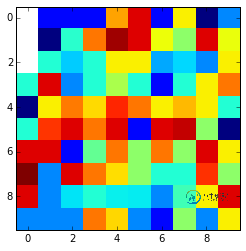
请注意,如果nan值在边缘且被nan值包围,则无法对thay进行插值并将其保留nan。您可以使用fill_value参数进行更改。
这取决于您的数据类型,您必须执行一些测试。例如,您可以故意对一些好的数据进行蒙版,尝试使用具有蒙版值的数组尝试不同种类的插值,例如三次,线性等,并计算插值与您之前蒙版的原始值之间的差,然后查看方法返回您的细微差别。
您可以使用如下形式:
reference = array[3:6,3:6].copy()
array[3:6,3:6] = np.nan
method = ['linear', 'nearest', 'cubic']
for i in method:
GD1 = interpolate.griddata((x1, y1), newarr.ravel(),
(xx, yy),
method=i)
meandifference = np.mean(np.abs(reference - GD1[3:6,3:6]))
print ' %s interpolation difference: %s' %(i,meandifference )
这给出了这样的内容:
linear interpolation difference: 4.88888888889
nearest interpolation difference: 4.11111111111
cubic interpolation difference: 5.99400137377
当然,这是针对随机数的,因此结果可能会有很大差异是正常的。因此,最好的办法是对数据集的“故意遮盖的”部分进行测试,然后看看会发生什么。
-
问题内容: 我有一个表,带有2个重要列DocEntry,WebId 样本数据就像 现在我们可以在这里注意到,在WebId列中缺少S004。我们如何通过查询找到这些缺失的数字。 进一步说明: 如果网站ID之间缺少任何数字,则Web ID应按升序排列,例如S001,S002,S003,S004,S005。我没有任何单独的表格来输入可能的条目,因为这是不切实际的。我必须逐月查找丢失的数字,以每个月的开始
-
问题内容: 我有一个熊猫数据框,其中包含每月数据,我想为其计算12个月的移动平均值。但是缺少一月每个月的数据(NaN),所以我正在使用 但这只是给我所有的NaN值。 有没有一种简单的方法可以忽略NaN值?我了解实际上,这将成为11个月的移动平均值。 数据框还有其他包含一月数据的变量,所以我不想只扔掉一月的列并进行11个月的移动平均。 问题答案: 有几种方法可以解决此问题,最好的方法取决于一月份的数
-
主要内容:为什么会存在缺失值?,什么是稀疏数据?,缺失值处理,检查缺失值,缺失数据计算,清理并填充缺失值,删除缺失值在一些数据分析业务中,数据缺失是我们经常遇见的问题,缺失值会导致数据质量的下降,从而影响模型预测的准确性,这对于机器学习和数据挖掘影响尤为严重。因此妥善的处理缺失值能够使模型预测更为准确和有效。 为什么会存在缺失值? 前面章节的示例中,我们遇到过很多 NaN 值,关于缺失值您可能会有很多疑问,数据为什么会丢失数据呢,又是从什么时候丢失的呢?通过下面场景,您会得到答案。 其实在很多时
-
问题内容: 这应该很简单,但是我发现的最接近的内容是这篇文章: pandas:填充组中的缺失值,但我仍然无法解决我的问题。 假设我有以下数据框 我想在每个“名称”组中用平均值填写,即 我不确定要去哪里: 问题答案: 一种方法是使用:
-
本文向大家介绍决策树处理缺失值?相关面试题,主要包含被问及决策树处理缺失值?时的应答技巧和注意事项,需要的朋友参考一下 缺失值问题可以从三个方面来考虑 在选择分裂属性的时候,训练样本存在缺失值,如何处理?(计算分裂损失减少值时,忽略特征缺失的样本,最终计算的值乘以比例(实际参与计算的样本数除以总的样本数)) 假如你使用ID3算法,那么选择分类属性时,就要计算所有属性的熵增(信息增益,Gain)。假
-
本文向大家介绍如何处理缺失值数据?相关面试题,主要包含被问及如何处理缺失值数据?时的应答技巧和注意事项,需要的朋友参考一下 数据中可能会有缺失值,处理的方法有两种,一种是删除整行或者整列的数据,另一种则是使用其他值去填充这些缺失值。在Pandas库,有两种很有用的函数用于处理缺失值:isnull()和dropna()函数能帮助我们找到数据中的缺失值并且删除它们。如果你想用其他值去填充这些缺失值,则
-
我正在研究一个使用LSTM的时间序列预测问题。输入包含几个特性,因此我使用多元LSTM。问题是缺少一些值,例如: 与插值缺失值不同,这可能会在结果中引入偏差,因为有时在同一特征上有许多连续的时间戳缺失值,我想知道是否有方法让LSTM使用缺失值进行学习,例如,使用遮罩层或类似的东西?有人能给我解释一下什么是处理这个问题的最佳方法吗?我正在使用Tensorflow和Keras。
-
问题内容: 问题是如何用熊猫数据框中类别列的最频繁级别填充NaN? 在R randomForest软件包中,有 na.roughfix选项: 在熊猫中使用数字变量,我可以用以下内容填充NaN值: 问题答案: 您可以使用一栏中最频繁的值来填充NaN。 如果要用自己的最常用值填充每一列,则可以使用 更新 2018-25-10⬇ 从熊猫开始,包括用于Series和Dataframe的方法。您可以使用它来