
Hive怎样创建数据库和查询数据库信息?

HIVE介绍
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
今天给大家介绍Hive怎样创建数据库和查询数据库信息:
创建数据库
Hive中创建数据库的语法格式如下。
CREATE (DATARASE [SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value, .…)];
上述语法的具体讲解如下。
·CREATE(DATABASE|SCHEMA):表示创建数据库的语句,其中 DATABASE和SCHEMA含义相同,可以切换使用。
·IFNOTEXISTS:可选,用于判断创建的数据库是否已经存在,若不存在则创建数据库,反之不创建数据库。
·database_name:表示创建的数据库名称。
·COMMENTdatabase_com ment:可选.表示数据库的相关描述。
·LOCATION hdfs_path:可选,用于指定数据库在HDFS上的存储位置,默认存储位置取决于Hive 配置文件hive-site.xml中参数hive.metastore.warehouse.dir指定的存储位置。
·WITH DBPROPERTIES(property_name=property_value,...):可选,用于设置数据库属性,其中property_name表示属性名称,该名称可以自定义;property_value表示属性值,该值可以自定义。
接下来,在Hive客户端工具Beeline中创建数据库itcast,并指定数据库文件存放在HDFS的/hive_db/create_db八录中,具体命令如下。
CREATE DATABASE IF NOT EXISTS itcAst
COMMENT *This is itcast database"
出版社
LOCATION '/hive_db/create_db/'
NITH DBPROPERTIES ("creator"-"itcast", "date"-"2020-08-08"):
上述命令中,添加了数据库描述和数据库属性,其中数据库描述为This is itcast database;数据库属性为creator和date,这两个属性对应的值分别是itcast和2020-08-08。
查询数据库
Hive中查询数据库的语法格式如下所示。
SHOW (DATABASES[SCHEMAS) [LIKE 'identifier_with_wildcards'];
上述语法的具体讲解如下。
·SHOW(DATABASESISCHEMAS):表示查询数据库的语句,其中DATABASE和SCHEMA含义相同,可以切换使用。
·LIKE identifier_with_wildcards':可选,LIKE子句用于模糊查询,identifier_with_wildcards 用于指定查询条件。
接下来,查询Hive中所有数据库,具体命令如下。
SHOW DATABASES;
如果要查询Hive中数据库名称的首字母是i的数据库,具体命令如下。
SHOW DATABASES LIKE "i *";
上述命令在Hive客户端工具Beeline的执行效果如图所示。
查看数据库信息
Hive中查看数据库信息的语法格式如下所示。
上述语法的具体讲解如下。
·DESCRIBE|DESC(DATABASES|SCHEMAS):表示查询数据库信息的语句,其中DESCRIBE和DESC含义相同,可以切换使用。
·EXTENDED:可选,在查询数据库的信息中显示属性。
·db_name:用于指定查询的数据库名称。
接下来,查看Hive中数据库itcast的信息,具体命令如下。
DESC DATABASE EXTENDED itcast;
上述命令在Hive客户端工具Beeline的执行效果如图所示。
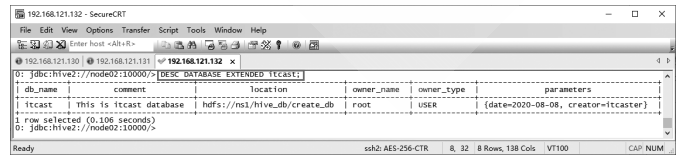
上图中数据库itcast中的信息包含6个字段。其中,db_name表示数据库名称,comment表示数据库描述,location表示数据库在HDFS上的存储位置.owner_name表示数据库所有者名称,owner_type表示数据库所有者类型,parameters表示数据库属性。
-
本文向大家介绍hive 创建数据库,包括了hive 创建数据库的使用技巧和注意事项,需要的朋友参考一下 示例 在特定位置创建数据库。如果我们不为数据库指定任何位置,则其在仓库目录中创建。
-
但是首先,我们要去为数据库创建model类。你还记得我们之前所见的map委托的方式?我们要把这些属性直接映射到数据库中,反过来也一样。 我们先来看下CityForecast类: class CityForecast(val map: MutableMap<String, Any?>, val dailyForecast: List<DayFor
-
SqliteOpenHelper只是一个工具,是SQL世界和OOP之间的一个通道。我们要新建几个类来请求已经保存在数据库中的数据,和保存新的数据。被定义的类会使用ForecastDbHelper和DataMapper来转换数据库中的数据到domain models。我仍旧使用默认值的方式来实现简单的依赖注入: class ForecastDb( val forecastDbHelper:
-
这是获得SQL结果集的一个非常常见的方法,因为一对多的关系······对于一个相当简单的结构执行冗余查询似乎是不必要的(而且可能是低效的)。是否有一种已建立的简单的方法将其解析为java对象?也就是说,我不想迭代ResultSet类并为每一行创建和设置一个新对象,而是要迭代集合并为每一个父行创建一个新对象,为每一个子行创建一个新对象。 例如,一种方法是按父主键对查询进行排序,然后仅当父id更改时才
-
Hive 是一个数据仓库基础工具在 Hadoop 中用来处理结构化数据。它架构在 Hadoop 之上,总归为大数据,并使得查询和分析方便。并提供简单的sql查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。
-
创建数据库之后,如何执行DDL语句来创建表?
-
主要内容:创建非限制性数据库,创建限制性数据库命令用于在实例中创建数据库。所有数据库都是使用默认存储组创建的,该存储组是在创建实例时创建的。 在DB2中,所有数据库表都存储在中,后者使用各自的存储组。 创建非限制性数据库 命令用于创建非限制性数据库。 语法: 示例 假设要创建一个名称为“XYZ”的数据库 安装后,切换到用户才有权创建新数据库。根据安装的版本,可能会更改该用户名。 但DB2默认使用作为管理员用户。 查看目录,将看到一个新用户(最
-
主要内容:使用Fauxton创建数据库,CouchDB使用cURL工具创建数据库在CouchDB中,数据库是存储文档的最外层结构。 CouchDB提供cURL实用程序来创建数据库。 您也可以使用的CouchDB Web界面。 使用Fauxton创建数据库 在网络浏览器中打开以下链接: 应该会看到类似下面的一个页面: 点击红色圆圈中的“Create Database”选项卡,创建一个名为“”的数据库。 它将显示一条消息,表示数据库已成功创建。可以在概览(Overview)选项卡