
详细说说CNN工作原理

1 人工神经网络
1.1 神经元
神经网络由大量的神经元相互连接而成。每个神经元接受线性组合的输入后,最开始只是简单的线性加权,后来给每个神经元加上了非线性的激活函数,从而进行非线性变换后输出。每两个神经元之间的连接代表加权值,称之为权重(weight)。不同的权重和激活函数,则会导致神经网络不同的输出。 举个手写识别的例子,给定一个未知数字,让神经网络识别是什么数字。此时的神经网络的输入由一组被输入图像的像素所激活的输入神经元所定义。在通过非线性激活函数进行非线性变换后,神经元被激活然后被传递到其他神经元。重复这一过程,直到最后一个输出神经元被激活。从而识别当前数字是什么字。 神经网络的每个神经元如下
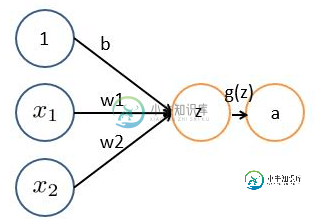
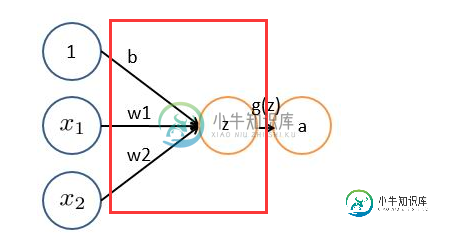
基本wx + b的形式,其中 x1、x2表示输入向量 w1、w2为权重,几个输入则意味着有几个权重,即每个输入都被赋予一个权重 b为偏置bias g(z) 为激活函数 a 为输出 如果只是上面这样一说,估计以前没接触过的十有八九又必定迷糊了。事实上,上述简单模型可以追溯到20世纪50/60年代的感知器,可以把感知器理解为一个根据不同因素、以及各个因素的重要性程度而做决策的模型。 举个例子,这周末北京有一草莓音乐节,那去不去呢?决定你是否去有二个因素,这二个因素可以对应二个输入,分别用x1、x2表示。此外,这二个因素对做决策的影响程度不一样,各自的影响程度用权重w1、w2表示。一般来说,音乐节的演唱嘉宾会非常影响你去不去,唱得好的前提下 即便没人陪同都可忍受,但如果唱得不好还不如你上台唱呢。所以,我们可以如下表示: x1:是否有喜欢的演唱嘉宾。x1 = 1 你喜欢这些嘉宾,x1 = 0 你不喜欢这些嘉宾。嘉宾因素的权重w1 = 7 x2:是否有人陪你同去。x2 = 1 有人陪你同去,x2 = 0 没人陪你同去。是否有人陪同的权重w2 = 3。 这样,咱们的决策模型便建立起来了:g(z) = g(w1x1 + w2x2 + b ),g表示激活函数,这里的b可以理解成 为更好达到目标而做调整的偏置项。 一开始为了简单,人们把激活函数定义成一个线性函数,即对于结果做一个线性变化,比如一个简单的线性激活函数是g(z) = z,输出都是输入的线性变换。后来实际应用中发现,线性激活函数太过局限,于是人们引入了非线性激活函数。
1.2 激活函数
常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者relu常见于卷积层。这里先简要介绍下最基础的sigmoid函数(btw,在本博客中SVM那篇文章开头有提过)。 sigmoid的函数表达式如下
其中z是一个线性组合,比如z可以等于:b + w1x1 + w2x2。通过代入很大的正数或很小的负数到g(z)函数中可知,其结果趋近于0或1。 因此,sigmoid函数g(z)的图形表示如下( 横轴表示定义域z,纵轴表示值域g(z) ):
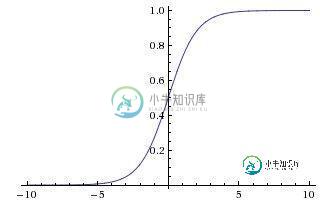
也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常小的负数时,则g(z)会趋近于0。 压缩至0到1有何用处呢?用处是这样一来便可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。 举个例子,如下图(图引自Stanford机器学习公开课)
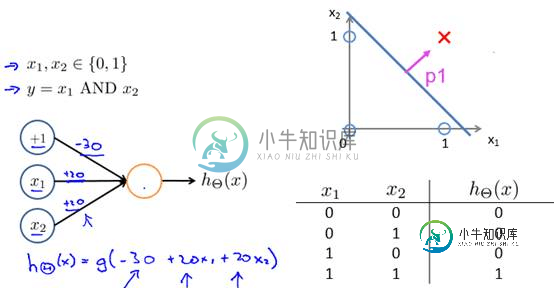
z = b + w1x1 + w2x2,其中b为偏置项 假定取-30,w1、w2都取为20
如果x1 = 0 x2 = 0,则z = -30,g(z) = 1/( 1 + e^-z )趋近于0。此外,从上图sigmoid函数的图形上也可以看出,当z=-30的时候,g(z)的值趋近于0 如果x1 = 0 x2 = 1,或x1 =1 x2 = 0,则z = b + w1x1 + w2x2 = -30 + 20 = -10,同样,g(z)的值趋近于0 如果x1 = 1 x2 = 1,则z = b + w1x1 + w2x2 = -30 + 201 + 201 = 10,此时,g(z)趋近于1。 换言之,只有和都取1的时候,g(z)→1,判定为正样本;或取0的时候,g(z)→0,判定为负样本,如此达到分类的目的。
1.3 神经网络 将下图的这种单个神经元

组织在一起,便形成了神经网络。下图便是一个三层神经网络结构

上图中最左边的原始输入信息称之为输入层,最右边的神经元称之为输出层(上图中输出层只有一个神经元),中间的叫隐藏层。 啥叫输入层、输出层、隐藏层呢? 输入层(Input layer),众多神经元(Neuron)接受大量非线形输入讯息。输入的讯息称为输入向量。 输出层(Output layer),讯息在神经元链接中传输、分析、权衡,形成输出结果。输出的讯息称为输出向量。 隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。如果有多个隐藏层,则意味着多个激活函数。 同时,每一层都可能由单个或多个神经元组成,每一层的输出将会作为下一层的输入数据。比如下图中间隐藏层来说,隐藏层的3个神经元a1、a2、a3皆各自接受来自多个不同权重的输入(因为有x1、x2、x3这三个输入,所以a1 a2 a3都会接受x1 x2 x3各自分别赋予的权重,即几个输入则几个权重),接着,a1、a2、a3又在自身各自不同权重的影响下 成为的输出层的输入,最终由输出层输出最终结果。
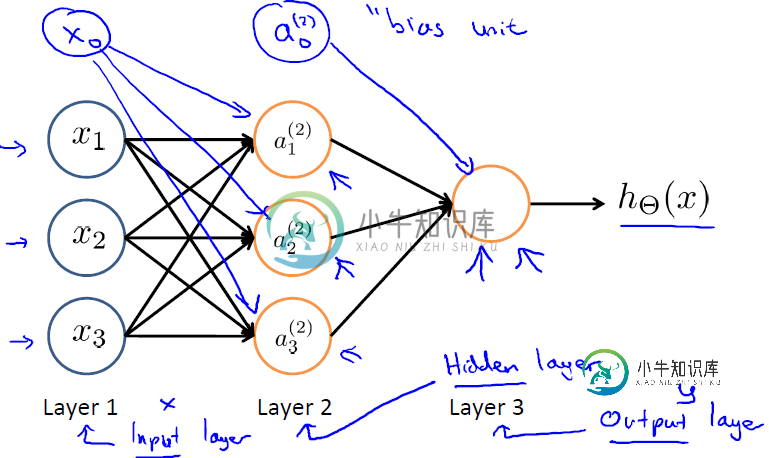
上图(图引自Stanford机器学习公开课)中 表示第j层第i个单元的激活函数/神经元 表示从第j层映射到第j+1层的控制函数的权重矩阵 此外,输入层和隐藏层都存在一个偏置(bias unit),所以上图中也增加了偏置项:x0、a0。针对上图,有如下公式
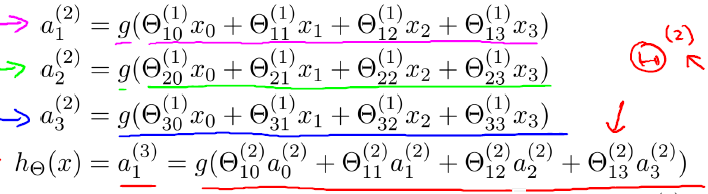
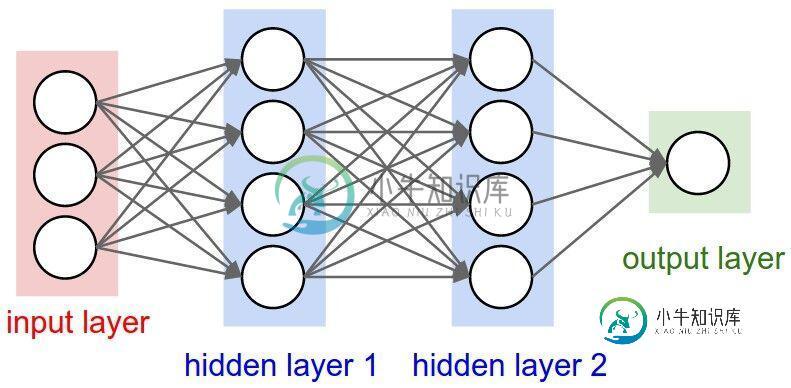
此外,上文中讲的都是一层隐藏层,但实际中也有多层隐藏层的,即输入层和输出层中间夹着数层隐藏层,层和层之间是全连接的结构,同一层的神经元之间没有连接。
2 卷积神经网络之层级结构
cs231n课程里给出了卷积神经网络各个层级结构,如下图
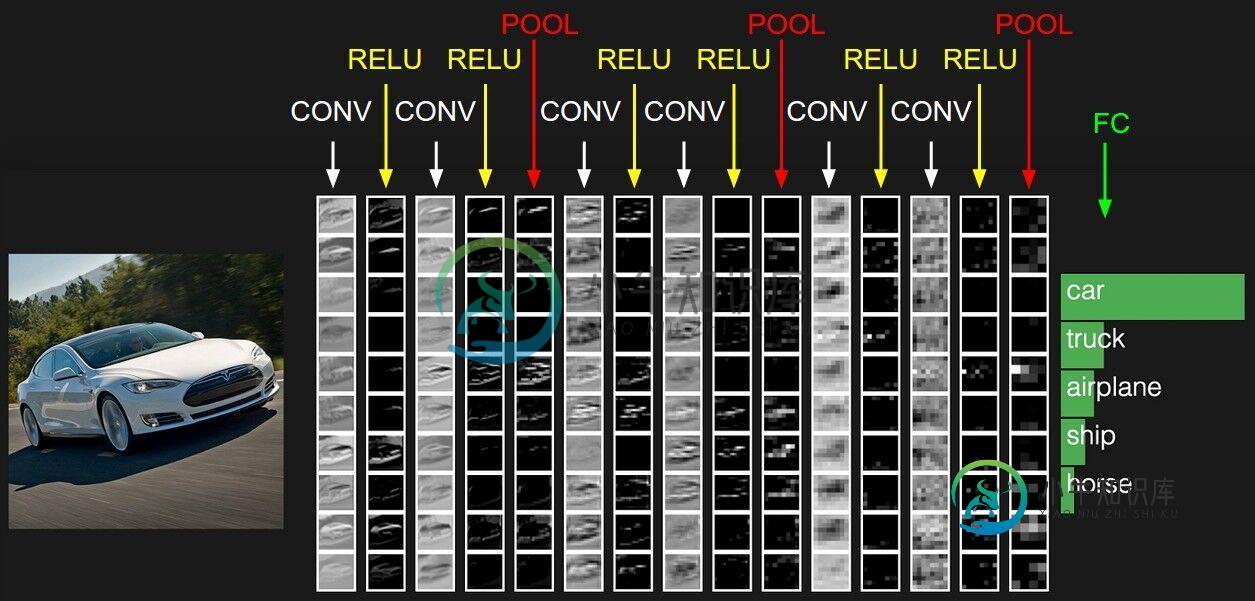
上图中CNN要做的事情是:给定一张图片,是车还是马未知,是什么车也未知,现在需要模型判断这张图片里具体是一个什么东西,总之输出一个结果:如果是车 那是什么车 所以 最左边是数据输入层,对数据做一些处理,比如去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA/白化等等。CNN只对训练集做“去均值”这一步。 中间是 CONV:卷积计算层,线性乘积 求和。 RELU:激励层,上文2.2节中有提到:ReLU是激活函数的一种。 POOL:池化层,简言之,即取区域平均或最大。 最右边是 FC:全连接层 这几个部分中,卷积计算层是CNN的核心,下文将重点阐述。
3 CNN之卷积计算层
3.1 CNN怎么进行识别
当我们给定一个"X"的图案,计算机怎么识别这个图案就是“X”呢?一个可能的办法就是计算机存储一张标准的“X”图案,然后把需要识别的未知图案跟标准"X"图案进行比对,如果二者一致,则判定未知图案即是一个"X"图案。 而且即便未知图案可能有一些平移或稍稍变形,依然能辨别出它是一个X图案。如此,CNN是把未知图案和标准X图案一个局部一个局部的对比,如下图所示 [图来自参考文案25]

而未知图案的局部和标准X图案的局部一个一个比对时的计算过程,便是卷积操作。卷积计算结果为1表示匹配,否则不匹配。 接下来,我们来了解下什么是卷积操作。
3.2 什么是卷积
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。 非严格意义上来讲,下图中红框框起来的部分便可以理解为一个滤波器,即带着一组固定权重的神经元。多个滤波器叠加便成了卷积层。
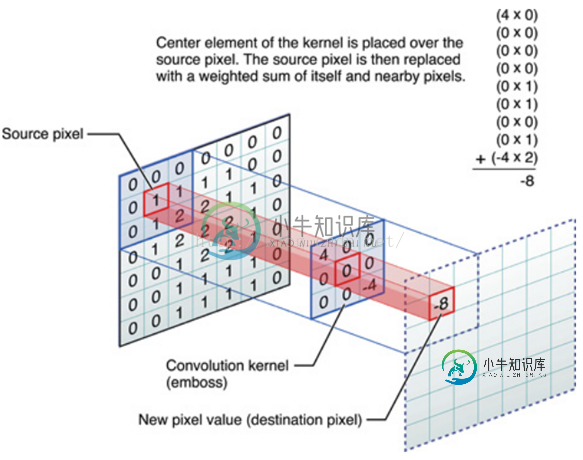
OK,举个具体的例子。比如下图中,图中左边部分是原始输入数据,图中中间部分是滤波器filter,图中右边是输出的新的二维数据。
分解下上图
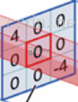
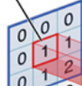
对应位置上是数字先相乘后相加
= 中间滤波器filter与数据窗口做内积,其具体计算过程则是:40 + 00 + 00 + 00 + 01 + 01 + 00 + 01 + -4*2 = -8 *
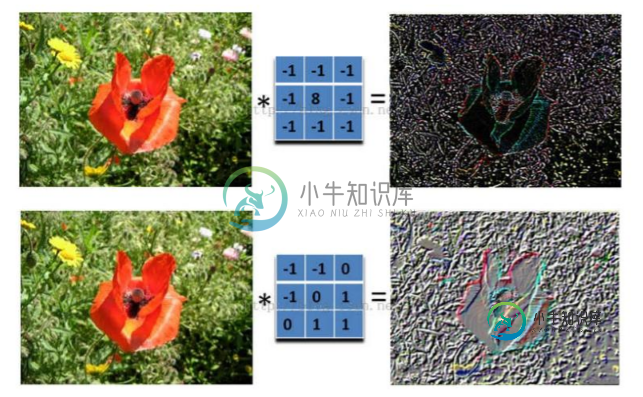
3.3 图像上的卷积
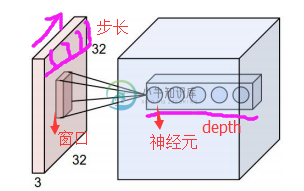
在下图对应的计算过程中,输入是一定区域大小(widthheight)的数据,和滤波器filter(带着一组固定权重的神经元)做内积后等到新的二维数据。 具体来说,左边是图像输入,中间部分就是滤波器filter(带着一组固定权重的神经元),不同的滤波器filter会得到不同的输出数据,比如颜色深浅、轮廓。相当于如果想提取图像的不同特征,则用不同的滤波器filter,提取想要的关于图像的特定信息:颜色深浅或轮廓。 如下图所示 3.4 GIF动态卷积图 在CNN中,滤波器filter(带着一组固定权重的神经元)对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据。这个过程中,有这么几个参数: a. 深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器个数。 b. 步长stride:决定滑动多少步可以到边缘。 c. 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。
-
3 详细说明 ffmpeg的每个转换过程像下图描述的程序 _______ ______________ | | | | | input | demuxer | encoded data | decoder | file | ---------> | packets | -----+ |__
-
本文向大家介绍说一下 session 的工作原理?相关面试题,主要包含被问及说一下 session 的工作原理?时的应答技巧和注意事项,需要的朋友参考一下 session 的工作原理是客户端登录完成之后,服务器会创建对应的 session,session 创建完之后,会把 session 的 id 发送给客户端,客户端再存储到浏览器中。这样客户端每次访问服务器时,都会带着 sessionid,服务
-
介绍 NAT技术让少数公有IP地址被使用私有地址的大量主机所共享。这一机制允许远多于IP地址空间所支持的主机共享网络。同时,由于NAT屏蔽了内部网络,也为局域网内的机器提供了安全保障。 NAT的基本实施过程包括使用一个预留给本地IP网络的私有地址成立组织的内部网络,同时分配给组织一个或多个公网IP地址,并在本地网络与公网之间安装一个或多个具有NAT功能的路由器。NAT路由器实现的功能包括将数据报中
-
本文向大家介绍搞定immutable.js详细说明,包括了搞定immutable.js详细说明的使用技巧和注意事项,需要的朋友参考一下 什么是Immutable Data Immutable Data是指一旦被创造后,就不可以被改变的数据。 通过使用Immutable Data,可以让我们更容易的去处理缓存、回退、数据变化检测等问题,简化我们的开发。 js中的Immutable Data 在jav
-
DataSet类详细说明 这个wiki条目集中于DataSet类的子类。此处未提到的ChartData的所有其他子类不提供任何具体的增强功能。 Line-, Bar-, Scatter- & CandleDataSet (下面提到的方法能被用在任何提到的DataSet类中) setHighLightColor(int color): 设置用来高亮显示的颜色。不要忘记使用getResources()
-
当客户端登录完成后,会在服务端产生一个session,此时服务端会将sessionid返回给客户端浏览器。客户端将sessionid储存在浏览器的cookie中,当用户再次登录时,会获得对应的sessionid,然后将sessionid发送到服务端请求登录,服务端在内存中找到对应的sessionid,完成登录,如果找不到,返回登录页面。