
注意力公式

参考回答:
Soft attention、global attention、动态attention
Hard attention
“半软半硬”的attention (local attention)
静态attention
强制前向attention
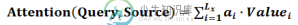
-
本文向大家介绍注意力机制相关面试题,主要包含被问及注意力机制时的应答技巧和注意事项,需要的朋友参考一下 encoder(x1,x2,x3…) → 语义编码c → decoder(y1,y2,y3…) 语音编码c对不同的x有不同的概率分布值(影响程度) 每个Ci可能对应着不同的源语句子单词的注意力分配概率分布 每个Ci可能对应着不同的源语句子单词的注意力分配概率分布
-
在“编码器—解码器(seq2seq)”一节里,解码器在各个时间步依赖相同的背景变量来获取输入序列信息。当编码器为循环神经网络时,背景变量来自它最终时间步的隐藏状态。 现在,让我们再次思考那一节提到的翻译例子:输入为英语序列“They”“are”“watching”“.”,输出为法语序列“Ils”“regardent”“.”。不难想到,解码器在生成输出序列中的每一个词时可能只需利用输入序列某一部分的
-
问题内容: 我目前正在使用从github 上的一次讨论中获得的这段代码,这是注意机制的代码: 这是正确的方法吗?我有点期待时间分布层的存在,因为关注机制分布在RNN的每个时间步中。我需要有人确认此实现(代码)是注意力机制的正确实现。谢谢。 问题答案: 如果您想在时间维度上关注,那么这段代码对我来说似乎是正确的: 您已经计算出shape的注意力向量: 我以前从未看过这段代码,所以我不能说这段代码是否
-
问题内容: 我知道Java中的(2 * i ==(i ^(i-1)+ 1)会让我发现数字是否为2的幂,但是有人可以解释为什么这样做有效吗? 问题答案: 2 * i ==(i ^(i-1))+ 1 基本上,如果为2的幂,则其位模式将为单个。如果从中减去1,则该位的所有低位将变为,并且该2的幂将变为0。然后对这些位进行“ 1”运算,从而产生全1的位模式。您将其加1,得到下一个2的幂。 记住异或表: 例
-
译者:mengfu188 校对者:Zhiyu-Chen 作者: Sean Robertson 在这个项目中,我们将教一个把把法语翻译成英语的神经网络。 [KEY: > input, = target, < output] > il est en train de peindre un tableau . = he is painting a picture . < he is painting
-
第五章 注意事项 对进程有了深入理解后,我们编写实际应用可能遇到这些坑,这里总结一下。