
BN的作用?

介绍BN,首先介绍深度学习过程实际上是学习数据的分布,而通过每一层卷积后,由于前一层的参数是每步迭代都会发生更新,因此后面层的数据的分布都会发生变化,那么网络又要花费精力去学习新的数据分布,从而使得学习速度很慢,因此就想将每一层的数据都通过归一化到同一分布上来加快学习,但是如果每一层改变其分布,那么就破坏了学习到的特征的分布,因此就引入了变换重构
于是文献使出了一招惊天地泣鬼神的招式:变换重构,引入了可学习参数γ、β,这就是算法关键之处:
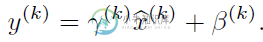
每一个神经元xk都会有一对这样的参数γ、β。这样其实当:
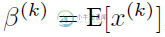
是可以恢复出原始的某一层所学到的特征的。因此我们引入了这个可学习重构参数γ、β,让我们的网络可以学习恢复出原始网络所要学习的特征分布。
可以解决梯度消失和梯度爆炸
-
本文向大家介绍BN层相关面试题,主要包含被问及BN层时的应答技巧和注意事项,需要的朋友参考一下 BN原理就是训练时候学习batch样本的均值和标准差,逐batch进行滑动更新,然后根据他们做归一化,结果乘以gamma再加上beta等于输出,gamma和beta就是BN层的待学习参数,等到推断的时候,固定住gamma和beta以及train时候得到的均值和标准差,得到计算结果即可
-
本文向大家介绍BN机制,公式(前向和反向),BN怎么训练,以及作用?相关面试题,主要包含被问及BN机制,公式(前向和反向),BN怎么训练,以及作用?时的应答技巧和注意事项,需要的朋友参考一下 BN不是凭空拍脑袋拍出来的好点子,它是有启发来源的:之前的研究表明如果在图像处理中对输入图像进行白化 所谓白化,就是对输入数据分布变换到0均值,单位方差的正态分布 (Whiten)操作的话,那么神经网络会较快
-
本文向大家介绍BN的参数有哪些?相关面试题,主要包含被问及BN的参数有哪些?时的应答技巧和注意事项,需要的朋友参考一下
-
本文向大家介绍BN层的作用,为什么要在后面加伽马和贝塔,不加可以吗相关面试题,主要包含被问及BN层的作用,为什么要在后面加伽马和贝塔,不加可以吗时的应答技巧和注意事项,需要的朋友参考一下 参考回答: BN层的作用是把一个batch内的所有数据,从不规范的分布拉到正态分布。这样做的好处是使得数据能够分布在激活函数的敏感区域,敏感区域即为梯度较大的区域,因此在反向传播的时候能够较快反馈误差传播。
-
web3.utils.isBN()方法用来检查给定的参数是否是一个BN.js实例对象。 调用: web3.utils.isBN(bn) 参数: bn - Object: 要检查的对象 返回值 Boolean:如果参数为BN对象则返回true,否则返回false 实例代码: var number = new BN(10); web3.utils.isBN(number); > true
-
本文向大家介绍BatchNormalization的作用相关面试题,主要包含被问及BatchNormalization的作用时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 神经网络在训练的时候随着网络层数的加深,激活函数的输入值的整体分布逐渐往激活函数的取值区间上下限靠近,从而导致在反向传播时低层的神经网络的梯度消失。而BatchNormalization的作用是通过规范化的手段,将越来越