
带有光标的Google App Engine数据存储区查询不会迭代所有项

在我的应用程序中,我有一个带有过滤器的数据存储区查询,例如:
datastore.NewQuery("sometype").Filter("SomeField<", 10)
我正在使用游标迭代结果的批次(例如在不同的任务中)。如果SomeField在迭代时更改的值,则光标将不再在Google App
Engine上工作(在devappserver上正常工作)。
我在这里有一个测试项目:https :
//github.com/fredr/appenginetest
在我的测试中,我运行/db了将db设置为10个项目并将其值设置为0的情况,然后运行/run/2它将对值是小于2(每5个批次),并将每个项目的值更新为2。
我的本地devappserver上的结果(所有项目均已更新):
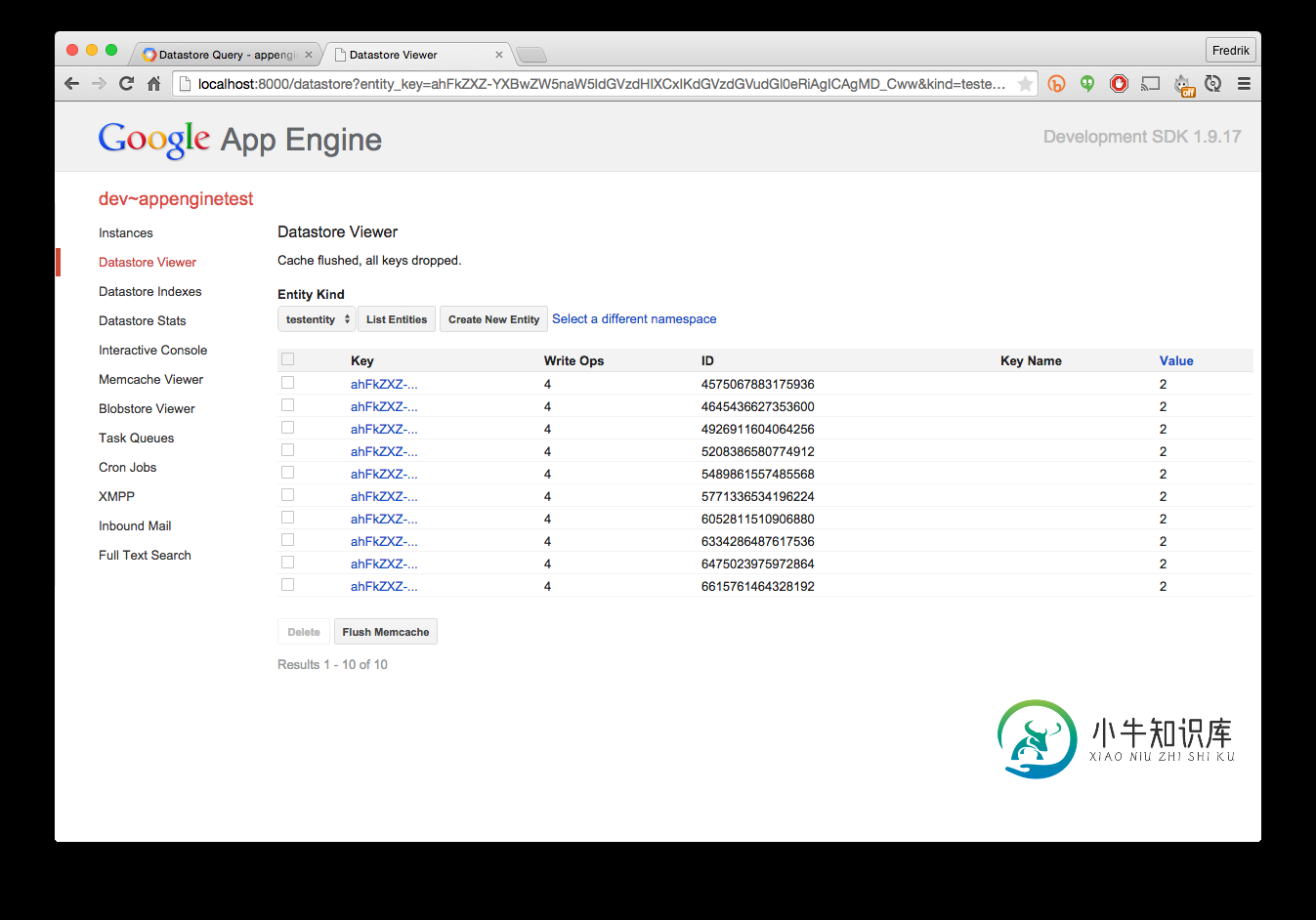
appengine上的结果(仅更新了五个项目): 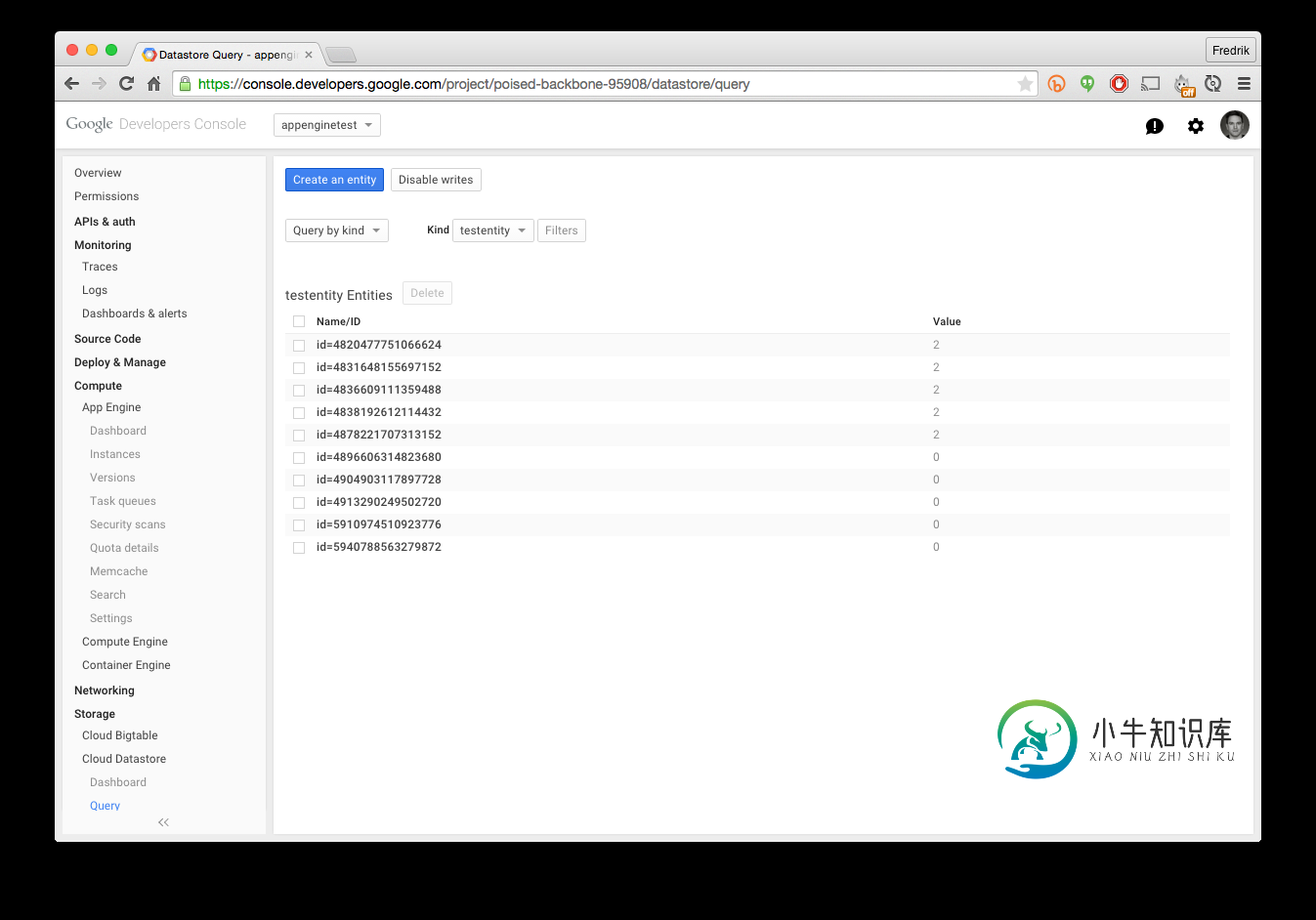
难道我做错了什么?这是一个错误吗?还是这是预期的结果?在文档中指出:
对于在多个值的属性上使用不等式过滤器或排序顺序的查询,游标有时无法正常工作。
问题答案:
问题是游标的性质和实现。游标包含最后处理的实体(已编码)的键,因此,如果在执行查询之前将游标设置为查询,则数据存储区将跳转到由游标中编码的键所指定的实体,并从那一点。
让我们来看看你的情况
您的查询过滤器为Value<2。您遍历查询结果的实体,然后将Value属性更改(并保存)为2。
注意Value=2不满足过滤条件Value<2。
在下一次迭代(下一批)中,将显示一个光标,您可以正确应用该光标。因此,数据存储区执行查询时,它会跳到上一次迭代中处理的最后一个实体,并希望列出此之后的实体。但是光标指向的实体可能已经
不满足 过滤条件;因为其新值的索引条目2很可能已经被更新(非确定性行为-
请参阅最终一致性,以获取更多详细信息,因为此处没有使用可以保证结果高度一致的Ancestor查询;延迟会增加概率这个的)。time.Sleep()
因此,数据存储区看到最后处理的实体不满足过滤条件,并且不会再次搜索所有实体,但是报告说没有更多的实体与过滤条件匹配,因此不会再更新任何实体(也不会报告错误)。
建议:请勿同时使用游标,过滤器或对要更新的同一属性进行排序。
顺便说说:
您引用的Appengine文档中的部分:
对于在多个值的属性上使用不等式过滤器或排序顺序的查询,游标有时无法正常工作。
这不是你的想法。这意味着:游标可能无法在 具有多个值 的属性 上 正常工作 ,并且 该属性要么包含在不等式过滤器中, 要么
用于对结果进行排序。
顺便说一句#2
在屏幕快照中,您正在使用SDK 1.9.17。最新的SDK版本是1.9.21。您应该对其进行更新,并始终使用最新的可用版本。
实现目标的替代方法
1)不要使用游标
如果记录很多,将无法一步一步更新所有实体,而假设您更新了300个实体。如果您重复查询,则已更新的实体将不在再次执行同一查询的结果中,因为已更新的实体Value=2不满足过滤条件Value<2。只需重做查询+更新,直到查询没有结果。由于更改是幂等的,因此如果实体的索引条目的更新被延迟并且不会被查询多次返回,则不会造成任何损害。最好延迟下一个查询的执行,以最大程度地减少这种情况的发生(例如,在重做查询之间等待几秒钟)。
优点: 简单。您已经有了解决方案,只需要排除光标处理部分即可。
缺点:
某些实体可能会多次更新(因此更改必须是幂等的)。同样,对实体执行的更改必须是将实体从下一个查询中排除的内容。
2)使用任务队列
您可以首先执行仅键查询,然后将更新推迟到使用任务。您可以创建一个任务,假设每个任务传递100个密钥,这些任务可以按密钥加载实体并进行更新。这样可以确保每个实体仅更新一次。由于涉及任务队列,此解决方案的延迟会稍大一些,但这在大多数情况下不是问题。
优点:
没有重复的更新(因此更改可能是非幂等的)。即使要执行的更改不会将实体从下一个查询中排除(更通用),该方法仍然有效。
缺点: 更高的复杂性。更大的延迟/延迟。
3)使用Map-Reduce
您可以使用map-reduce框架/实用程序对许多实体进行大规模并行处理。不知道它是否已经在Go中实现。
优点: 并行执行,甚至可以处理数百万或数十亿个实体。如果实体数量较大,则速度要快得多。加上2)使用任务队列中列出的专家。
缺点: 更高的复杂性。可能在Go中尚不可用。
-
为了简单起见,假设我想使用Azure REST API从特定存储库中的所有秘密中使用秘密名称和秘密值构建一个字典。 谢谢你。
-
有没有一种方法可以使用H2O迭代大于集群累积内存大小的数据?我有一个大数据集,我需要批量迭代并输入Tensorflow进行梯度下降。在给定的时间,我只需要在内存中加载一批(或少数)。有没有一种方法可以设置H2O来执行这种迭代,而无需将整个数据集加载到内存中? 这是一个相关的问题,一年多前就已经回答了,但没有解决我的问题:在h2o中加载大于内存大小的数据
-
问题内容: 在阅读了Internet中的文档和帖子后,我仍然无法 使用jMeter中的Cookie Manager 解决问题。我在响应标头中获得了sid ID,但未将其 存储在cookie管理器中。以下是我的测试计划和 connect.sid响应的屏幕 您能帮忙弄清楚出什么问题吗? 问题答案: 为了由JMeter(以及Web浏览器)进行处理,您的Cookie必须符合某些政策,即域和路径不应与当前U
-
我使用的是,需要提供不同字段的搜索特性。在搜索前输入字段是可选的。我有5个字段,即、、、和。 这里我只需要按用户查询给定的值,其他字段应该忽略。ex, 所以这里我们要考虑输入和查询的值。在这种情况下,Spring data有本文中提到的限制(不可伸缩,所有可能的查询都应该编写)我使用,但问题仍然存在,因为字段应该被忽略,几乎所有可能的查询都需要开发。在这个。如果搜索字段为怎么办?? 用可选字段实现
-
问题内容: 我正在尝试对数据存储区中的一组实体执行过滤器查询,但是我要使用相等运算符查询的实体字段的类型为[] byte,我不知道appengine数据存储区是否可以执行这个比较 这是我的实体: 这是我的查询逻辑 它可以构建但不会返回任何结果,即使经过10秒钟以编程方式重试后也是如此,因此我认为这不是数据存储与我存储在其中的视图数据之间最终一致性的问题。 我的主要问题是:appengine数据存储