
NOTE - this repo is no longer maintained
We'll keep this up as a reference for anyone who may need it - please send any comments to dev@nstack.com going forward
Thanks!
NStack: Composable, typed streams and microservices for data analytics
Introduction

NStack is a compute platform that is ideal for data analytics because it makes integrating data, publishing code, and connecting it all together really simple.
You can turn disparate data-sources -- such as databases, 3rd-party APIs, or HTTP endpoints -- into streams of typed records.
You can publish local code as functions on your cloud provider. Streams can be composed and connected with these functions using NStack's scripting language, and NStack automates all underlying infrastructure so you can focus on data-science instead of operations.
NStack provides end-to-end software life-cycle management for the data science process, including sharing and reuse, reproducibility, versioning, and runtime isolation.
Getting Started
See the website for more information, or check out the full documentation.
Intro Screencast
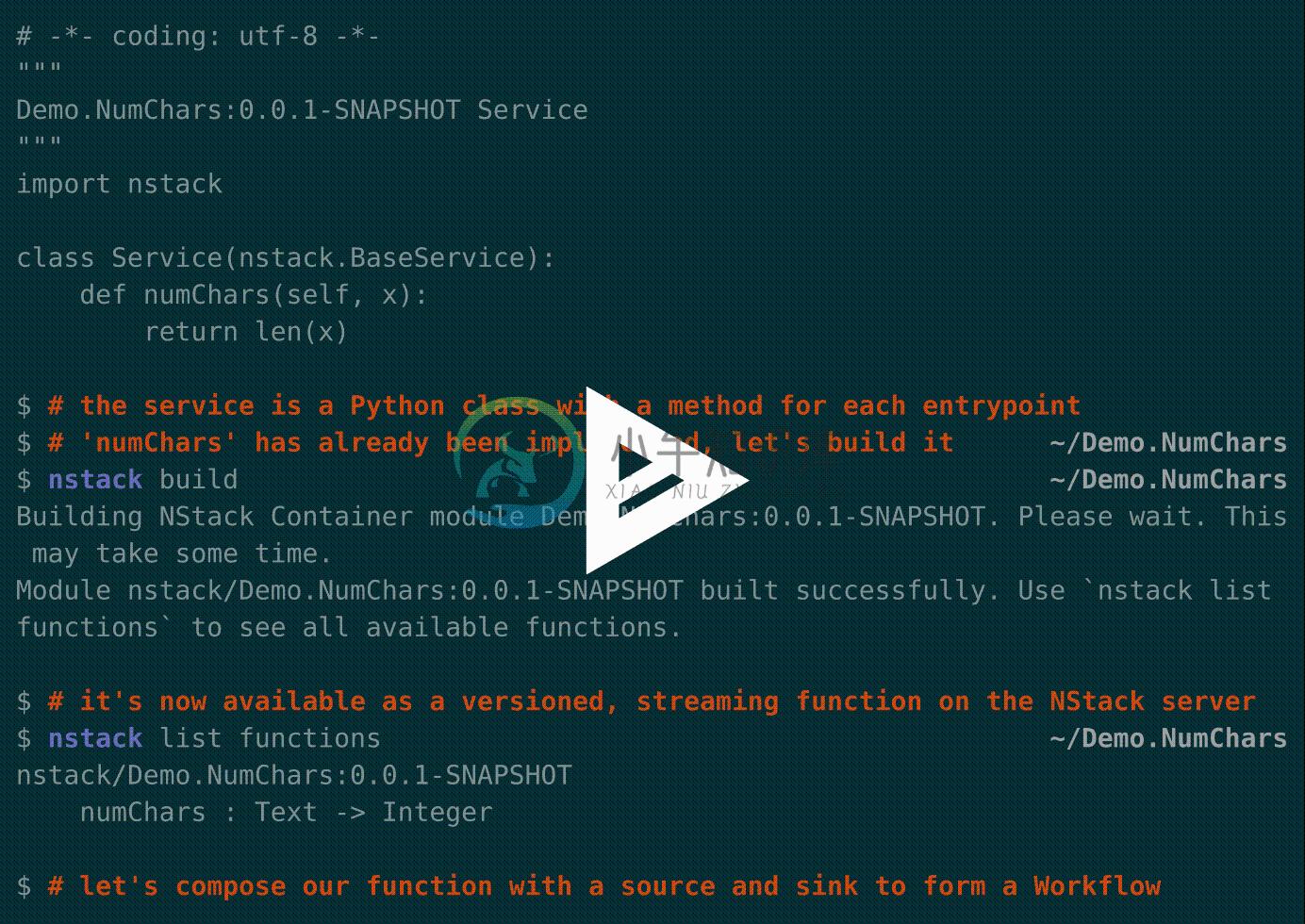
NStack is comprised of a CLI which runs on your machine, and a virtual machine which runs on the cloud.
CLI Installation
The NStack CLI is available as self-contained executable for Linux, Windows, and macOS - binaries can be downloaded on our releases page.Simply download nstack-cli-{linux64,win64,macOS} for your platform, uncompress, and run nstack from the Terminal/Command Prompt.
macOS
In addition to standalone download on the releases page, we have a homebrew package that can easily be installed as follows,
$ brew tap nstack/nstack
$ brew cask install nstack-cli
Linux
We also provide RPM and DEB packages on the releases page that will work with most common distros and can be installed via your system package manager.
RPM Install
# change {version} as needed
dnf install https://github.com/nstack/nstack/releases/v{version}/nstack-cli-{version}.x86_64.rpm
DEB Install
# change {version} as needed
wget https://github.com/nstack/nstack/releases/v{version}/nstack-cli_{version}.amd64.deb
dpkg -i nstack-cli_{version}.amd64.deb
apt-get install -f
Compiling from source
NStack is built using Haskell, to compile the CLI manually you will need the Stack build tool.Once this is installed, run the following commands from the git project root,
# stack setup only needed on first compile
stack setup
stack build nstack-cli
# install to user's local executable directory
stack install nstack-cli
Server Installation
PaaS
NStack offers a free-of-charge PaaS (Platform as a Service) for demo use, which means you can try NStack without installing the server. Note that the PaaS is intended as a sandbox and the environment is wiped daily at 0600 UTC.
You can register an account and immediately start using NStack using the following command:
nstack register <username> <email>
This will send you an email with your credentials and instructions on getting started.
Host your own NStack server
To install your own NStack server, we provide a self-contained appliance VM:
- an AMI for AWS EC2 (
ami-53a47245) - a
.rawdisk image for hosting on your virtual machine of choice
We also provide an RPM for installing directly on a Red Hat-like server. These are all available on the releases page.
Examples
Basic Example

We can express this within the NStack scripting language locally as follows (just think of it as Bash for microservices).
module Demo:0.1.0 {
import NStack.Transformers:0.1.4 as T
import Acme.Classifiers:0.3.0 as C
// our analytics workflow
def workflow = Sources.Postgresql<(Text, Int)>
| T.transform { strength = 5 }
| C.classify { model = "RandomForest" }
| Sinks.S3blob<Text>
}
We can then build, deploy, and start this workflow on an NStack Server from the NStack CLI on Linux, macOS, or Windows.
> nstack build
Building Demo:0.1.0
> nstack start Demo:0.1.0.workflow
Workflow started as process 3.
More Examples
See https://github.com/nstack/nstack-examples for a range of examples, which you can clone and use immediately, including
- demos - Basic examples that demonstrate creating methods and composing them together into workflows
- nstack - A selection of NStack utility modules, including methods for uploading to S3 and processing images
- iris - A Python-based classifier using
scikit-leaarnthat showcases building more complex modules with system dependencies and in-built data-sets - movies - A complex workflow composed from multiple individual services that processes movies data from the IMDB database, demonstrating composition, filtering, service configuration, and partial workflow reuse
License and Contributing
License
The NStack CLI is open-source and licensed under the BSD3 license.
The NStack Server is provided free-of-charge for personal, hobbyist, non-commercial, and evaluation use. It is currently closed-source, however we'd like to open more of it up over time.
Contributing
This repo is currently a mirror of our internal work, as development happens fairly rapidly.However we welcome and encourage both Issues and PRs (PRs will require a CLA - as described in CONTRIBUTING.md).
We're also looking into removing our mirror and working directly on this public repo if possible.
What do people use NStack for?
Productionising models
Productionise your models in the cloud without complex engineering, where they can be used in workflows and attached to data-sources. For instance, you can build a Random Forest classifier locally in Python, publish it to your cloud provider, and connect it to a streaming system, database, data-lake, or HTTP endpoint in under 10 minutes.
Data Integration
Transform disparate and disconnected data-sources -- such as 3rd-party APIs, legacy infrastructure, or databases -- into streams of typed, structured records, which can be composed together. For instance, you could set up a workflow in the cloud which pipes the Twitter Ads API into your data lake (and even do some modelling in Python in-transit) in under 5 minutes.
Features
- Typed Strongly-type your infrastructure and microservices to make them composable and secure
- Streaming Move your batch workloads and existing code to a streaming paradigm, without complex infrastructure
- Fast Really fast throughout by using the latest developments in the Linux kernel
- Serverless Modules are deployed as serverless, containerised, versioned, fully reproducible microservices
- Composable Compose infrastructure in a statically typed workflow language to automate operations
Concepts
Modules
A module is a piece of code that has been published to NStack -- for instance, a Python class. Modules are comprised of one or more functions -- in the same way a class of Python has one or more methods on it. Modules can have dependencies, like files or operating system packages -- for instance, your training data, or the scikit-learn package.
Functions
Functions are "serverless" functions which live on modules -- for instance, the predict method on your Python class. Functions on NStack are typed, which means you define what kind of data they can take as input, and the kind of data they output. For instance, you can say that your predict method only takes Text and returns Integer. This is important because it means they can be safely composed together and reused, with the NStack platform guaranteeing type safety.
Sources & Sinks
A source is something which emits a stream of data. A sink is something which can receive a stream of data. Examples sources and sinks are databases, files, message-queues, and HTTP endpoints. Like modules, you can define the input and output types for your sources and sinks.
Workflows
Modules, sources, and sinks can be combined -- or composed -- together to build workflows. This is accomplished using the NStack Workflow Language, a simple bash-like scripting language for connecting streams and functions together.
Processes
When a workflow is started and is running in the cloud, it becomes a process.
-
nstack Overview nstack is a Linux userspace TCP/IP stack. It was constructed to meet the following goals: Learn TCP/IP Learn Linux systems/network programming Learn Linux Socket API Current features:
-
np.stack 理解:axis参数指的是增加的维度 每次按对应维数取出来相应的数据并加括号组合起来: 如下例: a = np.array([[1,2,3,4], [5,6,7,8]]) b = np.array([[2,2,1,4], [3,5,7,8]]) c = np.array([[5,7,7,3], [6,6,2,8]]) arrays = np.asarray([a, b , c])