
Quickwit 是一个用于日志管理和分析的开源、云原生、分布式搜索引擎。Quickwit 用 Rust 编写,从头开始设计,可在大型数据集上提供成本效益和高可扩展性,是 Elasticsearch 的现代且可靠的替代方案。
Quickwit 特别适合处理大型、不可变数据集和相对较低的平均 QPS。它的好处在多租户或多索引设置中最为明显。
Quickwit 的常见用例包括:
- 搜索和分析日志,从少量数据到 TB。
- 为 ClickHouse 等 OLAP 数据库添加全文搜索功能。
- 通过在同一存储上添加 Quickwit 索引文件来搜索位于云存储上的备份。
Quickwit 主要功能的非详尽列表:
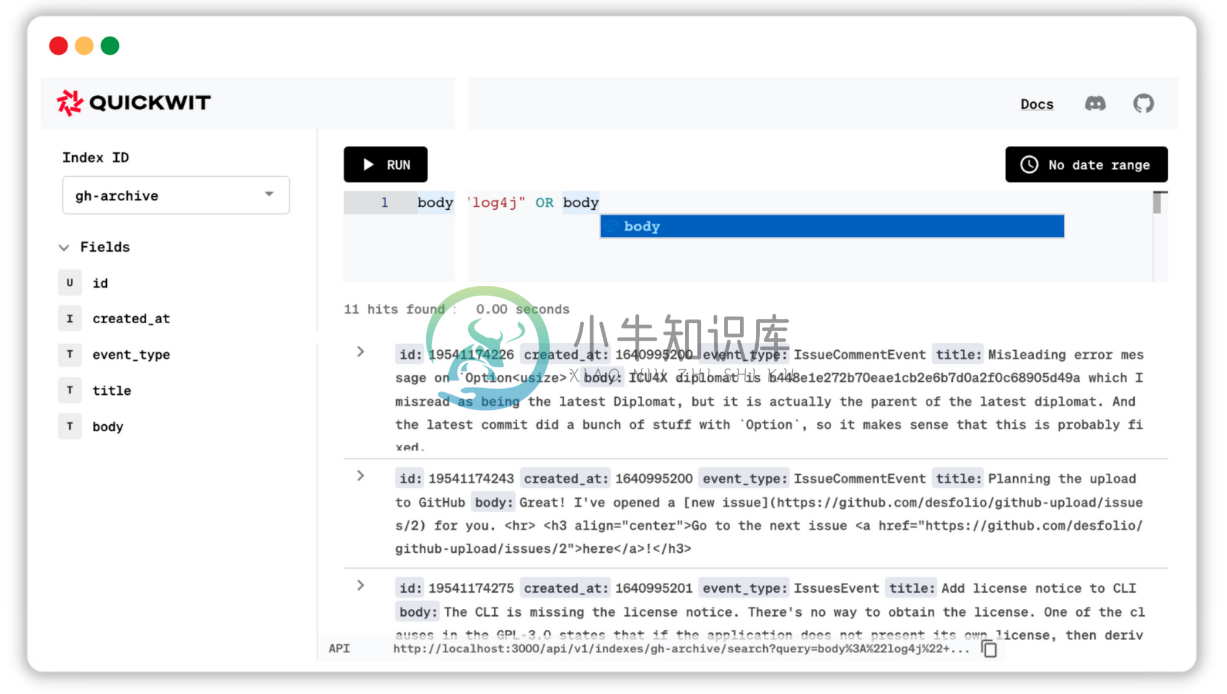
- 可扩展的分布式搜索:在 Amazon S3 上托管任意数量的索引,并使用少量无状态搜索实例池在不到一秒的时间内回答搜索查询。
- 流索引:从你最喜欢的分布式事件流服务中提取 TB 数据。截至今天,Quickwit 原生支持 Apache Kafka。下一个版本将支持更多平台。
- 不会丢失数据的容错架构: Quickwit 实现了对索引的一次性处理,并将你的数据安全地存储在高度可靠的对象存储服务上,例如 Amazon S3。
- 云原生,易于操作:得益于真正的计算和存储解耦,搜索实例是无状态的,在几秒钟内添加或删除搜索节点。
- 云/分布式存储上的亚秒级全文搜索: Quickwit Search 重新设计了索引和索引数据结构,在 Amazon S3 上打开时间不到 60ms 。
- 基于时间的分片:启用时,Quickwit 按时间分片数据。借助标签功能,你可以使用第二维对数据进行分片。基于时间的查询仅访问与查询时间范围匹配的拆分(索引的数据片段),从而显着提高性能。
- Painless 多租户搜索:为每个租户创建索引,而不会影响查询性能。或者将租户分组到一个索引中,并使用标记为你的租户查询修剪不相关的拆分,以显着提高性能。
特性:
- 索引数据持久保存在对象存储中
- 摄取带有或不带有严格模式的 JSON 文档
- 摄取和聚合 API Elasticsearch 兼容
- 轻量级嵌入式用户界面
- 在一小部分资源上运行:用 Rust 编写,由强大的 tantivy 提供支持
- 开箱即用,具有合理的默认值
- 针对多租户进行了优化。无需管理费用即可添加和扩展租户
- 分布式搜索
- 云原生:Kubernetes 就绪
- 在几秒钟内添加和删除节点
- 解耦计算和存储
- Sleep like a log:你所有的索引数据都安全地存储在对象存储中(AWS S3...)
- 以准确无误的语义你的文档
- Kafka 原生摄取
- 在 ClickHouse 中显着解锁全文搜索的搜索流 API
-
在Web一章中,我们提到MySQL很脆弱。数据库系统本身要保证实时和强一致性,所以其功能设计上都是为了满足这种一致性需求。比如write ahead log的设计,基于B+树实现的索引和数据组织,以及基于MVCC实现的事务等等。 关系型数据库一般被用于实现OLTP系统,所谓OLTP,援引wikipedia: 在线交易处理(OLTP, Online transaction processing)是指
-
为提高可伸缩性,Sphnix提供了分布式检索能力。分布式检索可以改善查询延迟问题(即缩短查询时间)和提高多服务器、多CPU或多核环境下的吞吐率(即每秒可以完成的查询数)。这对于大量数据(即十亿级的记录数和TB级的文本量)上的搜索应用来说是很关键的。 其关键思想是对数据进行水平分区(HP,Horizontally partition),然后并行处理。 分区不能自动完成,您需要 在不同服务器上设置Sp
-
搜索引擎分为两部分: 时间筛选 和 搜索引擎 (详情) 1.时间筛选 便捷按钮有今日、昨日、前日、上周 X、近七天,并且能自定义选择时间段来得出想要的结果报表 2.搜索引擎 (时间段详情) 选择日期,查看来自对应时间段内,各个搜索引擎的访问量比例
-
我有大量相同类型的实体,每个实体都有大量属性,并且我只有以下两种选择来存储它们: 将每个项存储在索引中并执行多索引搜索 将所有enties存储在单个索引中,并且只搜索1个索引。 一般而言,我想要一个时间复杂度之间的比较搜索“N”实体与“M”特征在上述每一种情况!
-
Spider 抓取系统的基本框架 互联网信息爆发式增长,如何有效的获取并利用这些信息是搜索引擎工作中的首要环节。数据抓取系统作为整个搜索系统中的上游,主要负责互联网信息的搜集、保存、更新环节,它像蜘蛛一样在网络间爬来爬去,因此通常会被叫做 “spider”。例如我们常用的几家通用搜索引擎蜘蛛被称为:Baiduspdier、Googlebot、Sogou Web Spider 等。 Spider 抓
-
我们已经使用Drools引擎几年了,但是我们的数据已经增长了,我们需要找到一个新的分布式解决方案来处理大量数据。我们有复杂的规则,可以查看几天的数据,这就是为什么Drools非常适合我们,因为我们的内存中只有数据。 你对类似于流口水但分布式/可扩展的东西有什么建议吗? 我确实对这件事进行了研究,但我找不到任何符合我们要求的东西。 谢谢