
Lilina 是一个简单,基于文本文件(不需要使用数据库)的新闻聚合器。支持RSS与Atom Feed。具有Feed自动发现,RSS输出等功能。
Lilina 是一款开源的feed聚合程序,用PHP写成,使用了 HTML Purifier 和 SimplePie 两个PHP库。Lilina 支持 RSS 和 ATOM 格式的 feed,并且支持从 OPML 中导入 feed。
-
摘自sparkweaver lilina is a simple but powerful news aggregator written in PHP. No database is needed, RSS/ATOM parsing is done by the excelent MagpieRSS library (it is included, no additional installat
-
添加了一个自己的 Lilina: http://www.dbanotes.net/lilina/index.php,联机的 RSS Reader! 主要订阅和Oracle与安全有关的几个 blog。在性能问题解决之后再添加新的吧。性能是个问题,参考了 Kreny 的关于加快 Lilina 显示速度的一些设置,现在好了很多。 车东可能是比较早使用 Lilina 的。我安装使用的是 lilina 的
-
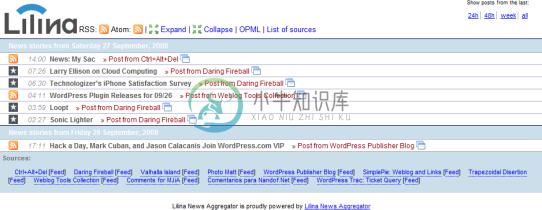
昨天配置了Lilina,把Feed Reader 移到了浏览器中。今天用了一下,还有好多不太完美的地方,动手调整了一下。先调整了favicon 图标,个别站点的图标比较大,但 index.php 页面对图标的大小没有控制这样格式不太整齐。在代码中加入 width 和 height 属性,值都为 16 。调整了item 的默认颜色,原来的暗红色太刺眼。 个别站点的RSS 抓取到的内容总会跑到最前面,
-
很久没有更新的 Lilina 升级了(看到首页有点变化。还以为是被黑掉了)。 新版本直接从 0.7 跳到了 0.9 rc1。改进特点如下: * Changed <? to <?php and <?= to <?php echo * Changed physical styles to logical styles * Added browser sniffing and content type
-
Lilina 是一个很好用的web news aggregator.现在有了新的空间,终于可以对这个小工具调整一下了.目前 Lilina 已经到了 0.7 版本.明显感觉在性能上也有了很大的提升.目前只是对 Lilina 进行了一下简单的定制. 同时决定把新的 Lilina 命名为 Oracle Security News Aggregator 更有针对性一些. Pete Finnigan’s O
-
lilina默认首页上显示的是一天的内容,更改index.php的: $TIMERANGE = ( $_REQUEST['hours'] ? $_REQUEST['hours']*3600 : 3600*24 ) ; 改成 $TIMERANGE = ( $_REQUEST['hours'] ? $_REQUEST['hours']*3600 : 3600*168 ) ; 这样就能显示一星期(24*
-
出处: http://www.eygle.com/blog 链接: http://www.eygle.com/archives/2005/11/gregarius_and_lilina.html 在Fenng的Blog上看到Gregarius的介绍,基于Gregarius,Fenng搭建了Openrss站点。 初步体验了一下,感觉的确不错,此前使用的Lilina虽然做了一些升级调整,并且参考了很多
-
之前我一直以为WordPress的atom输出是不包含全文的,因为用Lilina订阅总是只显示几十个字的摘要。后来看了一下atom的源代码,发现是包含的全文内容的,为什么Lilina没有输出呢。 原因在于atom的输出有summary和content这2个字段。而Lilina缺省只输出了summary。MagpieRSS也是支持输出content的:用atom_content代替summary即可
-
何东也安装了一个Lilina:Info-Aggr for Hedong,他觉得太慢。 如何加速呢:Lilina的RSS更新是一种动态触发的缓存更新机制,当每次有用户访问请求的时候,lilina检查cache目录中相应RSS的缓存,如果没有缓存或者缓存过期了,就立刻去服务器上取。而慢一般就慢在这个RSS的同步上了,比如:每天早上第一次访问,所有的RSS都需要更新,而订阅的RSS又非常多的情况下速度就
-
Lilina的简单预缓存加速 作者:车东 发表于:2005-04-13 19:04 最后更新于:2006-01-08 23:01 版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本声明。 http://www.chedong.com/blog/archives/000742.html 何东也安装了一个Lilina:Info-Aggr for Hedong,他觉得太慢。
-
今天看了一下Zhiqiang::He的lilina预缓存补丁一文,感觉它的“用 嵌套了index.php,这样每次访问cache文件时,都会调用index.php,index.php会判断cache文件是否过期,过期了则后台重建;如无过期则显示cache文件的创建时间,这样非常方便。”想法很有意思。虽然这样做和chedong的方法比得到的页面结果会旧一点,但是很多虚拟主机不能运行crontab更别
-
在线测试lilina,发现来自博客中国的feed乱码. 具体原因暂时不明. 由于bokee汇聚了大量牛人的blog.尤其是在图书馆情报学领域 这个问题一定要解决.
-
Django数据库抽象API描述了使用Django查询来增删查改单个对象的方法。然而,你有时候会想要获取从一组对象导出的值或者是聚合一组对象。这份指南描述了通过Django查询来生成和返回聚合值的方法。 整篇指南我们都将引用以下模型。这些模型用来记录多个网上书店的库存。 from django.db import models class Author(models.Model): na
-
我正在尝试设置一个搜索查询,该查询应通过多级嵌套字段复合聚合集合,并从该集合中提供一些子聚合指标。我能够按预期使用其存储桶获取复合聚合,但所有存储桶的子聚合指标都带有。我不确定我是否未能正确指出子聚合应考虑哪些字段,或者它是否应放置在查询的不同部分中。 我的收藏看起来类似于以下内容: 贝娄,你可以找到我已经尝试了。尽管所有文档都有一个设置的点击值,但所有存储桶都带有点击总数。 到目前为止,我的回应
-
在聚合中,两个实体之间的关系被视为单个实体。 在聚合中,与其对应实体的关系被聚合到更高级别的实体中。 例如:中心(Center)实体提供课程(Course)实体充当关系中的单个实体,该实体与另一个实体访问者处于关系中。 在现实世界中,如果访问者访问教练中心,那么他将永远不会询问有关课程或只是关于中心,而是他会询问有关两者的询问。
-
框架集合由搜索查询选择的所有数据。框架中包含许多构建块,有助于构建复杂的数据描述或摘要。聚合的基本结构如下所示 - 有以下不同类型的聚合,每个都有自己的目的 - 指标聚合 这些聚合有助于从聚合文档的字段值计算矩阵,并且某些值可以从脚本生成。 数字矩阵或者是平均聚合的单值,或者是像一样的多值。 平均聚合 此聚合用于获取聚合文档中存在的任何数字字段的平均值。 例如, 请求正文 响应 如果该值不存在于一
-
主要内容:聚合,继承和聚合的关系在实际的开发过程中,我们所接触的项目一般都由多个模块组成。在构建项目时,如果每次都按模块一个一个地进行构建会十分得麻烦,Maven 的聚合功能很好的解决了这个问题。 聚合 使用 Maven 聚合功能对项目进行构建时,需要在该项目中额外创建一个的聚合模块,然后通过这个模块构建整个项目的所有模块。聚合模块仅仅是帮助聚合其他模块的工具,其本身并无任何实质内容,因此聚合模块中只有一个 POM 文件,不像其
-
如果你需要从一个模型中获取一些聚合值,你可以使用Model.aggregate()。下面通过一个例子来展示: Person.aggregate({ surname: "Doe" }).min("age").max("age").get(function (err, min, max) { console.log("The youngest Doe guy has %d years, whi
-
Leaflet.markercluster 是一个提供动态的标识聚类功能的 Leaflet 插件库。 引入插件 Leaflet.markercluster 包括两种方式: 下载 Leaflet.markercluster 1.进入 github 下载 Leaflet.markercluster,下载地址为: https://github.com/Leaflet/Leaflet.markerclus
-
第一个名为的文档包含以下文档(不包括): 第二个集合名为,具有以下文档: 上的 预期的结果是: 如何使用聚合查询来实现这一点?