
SeQuaLite是一个轻量级,java数据存取框架(整个jar包不到80k)。支持CRUD操作。支持对象懒加载,通过创建代理对象或空对象来代替,等有需要时再加载。支持级联保存与级联删除操作。SeQuaLite使用 prepared statement来执行查询,因此它更快,更安全。使用SeQuaLite能够避免SQL注入安全威胁。SeQuaLite能够创建和执行复杂的查询/DML,并支持分页。
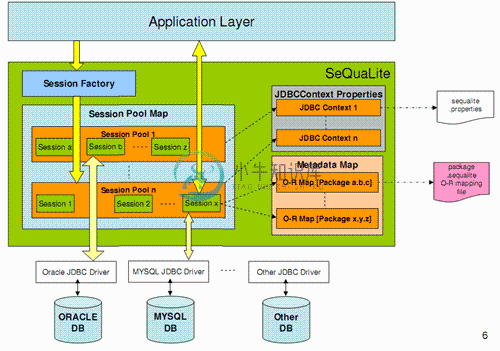
SeQuaLite 的结构框图:
SeQuaLite 全局配置示例:
sample.jdbc.driver=org.gjt.mm.mysql.Driver
sample.jdbc.url=jdbc:mysql://localhost:3306/test
sample.jdbc.user=root
sample.jdbc.password=admin
sample.jdbc.autocommit=true
sample.pool.maxsize=50
sample.pool.increment=5
sample.pool.monitor.interval=5000
Bean 的映射配置实例:
<class name="Customer" table-name="customer">
<field name="id" type="java.lang.Long" column-name="ID"/>
<field name="firstName" type="java.lang.String" column-name="FIRST_NAME"/>
<field name="lastName" type="java.lang.String" column-name="LAST_NAME"/>
<field name="createDate" type="java.util.Date" column-name="CREATE_DATE"/>
<field name="contactNumber" type="java.lang.String" column-name="CONTACT_NUMBER"/>
<primary-key column-name="ID" auto-increment="true">
<sequence-sql>SELECT LAST_INSERT_ID() </sequence-sql>
</primary-key>
<child name="address" type="Address" column-name="ID" child-column-name="CUSTOMER_ID" multiplicity="many" lazy-load="proxy" on-save-cascade="true" on-delete-cascade="true" index="0"/>
<sql name="default" type="find">
SELECT * FROM customer
</sql>
</class>
-
名称 方法 实现 Hibernate 优势 劣势 Mybaties Jpa get 1. Hibernate 1.1 单独使用 1.1.1 For Idea 新建项目:【File】——>【New】——>【Project】——>【Java】——>【Hibernate、JavaEE Persistence】 添加数据连接驱动 配置数据源 根据数据库表生成实体类:【Persistence】——>【名称】
-
我正在使用网络逻辑10.3。我正在尝试配置一个持久订阅,其中包含由 jdbc 存储(在 Oracle DB 中)支持的持久消息。我有一个主题,MDB 正在作为持久订阅者侦听该主题。在场景-1下:如果我发送消息,它会命中MDB。 在场景2中:我挂起了MDB,希望发送到主题的消息只要不被MDB(它是唯一注册的持久订阅者)使用,就会一直存在。但是当我向主题发送消息时,它短暂地出现在那里,然后就消失了(我
-
问题内容: 我有一个利用图(树状)自定义结构的应用程序。这些结构不是真正的树木,但几乎所有事物都连接在一起。数据量也很大(可以存在数百万个节点)。树节点的类型可以不同,以使其更有趣(继承)。我不想更改数据结构以容纳持久性存储。 我想保留这些数据而无需过多的工作。我已经选择了一些解决方案来解决此问题,但找不到任何完全适合我需要的东西。可能的选项:序列化,使用ORM的数据库(Hibernate?),使
-
数据落盘问题的由来 这本质上是数据持久化问题,对于有些应用依赖持久化数据,比如应用自身产生的日志需要持久化存储的情况,需要保证容器里的数据不丢失,在Pod挂掉后,其他应用依然可以访问到这些数据,因此我们需要将数据持久化存储起来。 数据落盘问题解决方案 下面以一个应用的日志收集为例,该日志需要持久化收集到ElasticSearch集群中,如果不考虑数据丢失的情形,可以直接使用前面提到的应用日志收集一
-
为了学习数据的持久化,写一个简单的地址薄合约.虽然这个例子因为各种原因作为生产环境的合约不太实用,但它是一个很好的合约用来学习EOSIO的数据持久化并且不会因为与eosio multi_index不相关的相关业务逻辑分心. Step 1:创建一个新的文件夹 进入之前的目录: cd /Users/zhong/coding/CLion/contracts 为我们的合约创建一个新的目录并进去: mkd
-
主要内容:一、数据持久化,二、持久化的形式,三、源码分析,四、总结一、数据持久化 redis做为一种内存型数据库,做持久化,个人感觉略有鸡肋的意思。似乎有一种,别人有,自己不有也不行的感觉。以目前Redis主流的应用方式,如果仔细分析,基本上都是在内存中即可完成,对持久化没要求或者说不大。再举一个反例,如果内存中有几百G甚至更多的数据,真要是整体当机,恢复的时间基本就是灾难。 目前基本应用仍然是以关系型数据库或者其它数据库(如Hadoop,Mysql等)为持久化