
Apache ORC 文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。
ORC(OptimizedRC File)存储源自于RC(RecordColumnar File)这种存储格式,RC是一种列式存储引擎,对schema演化(修改schema需要重新生成数据)支持较差,而ORC是对RC改进,但它仍对schema演化支持较差,主要是在压缩编码,查询性能方面做了优化。RC/ORC最初是在Hive中得到使用,最后发展势头不错,独立成一个单独的项目。Hive 1.x版本对事务和update操作的支持,便是基于ORC实现的(其他存储格式暂不支持)。ORC发展到今天,已经具备一些非常高级的feature,比如支持update操作,支持ACID,支持struct,array复杂类型。你可以使用复杂类型构建一个类似于parquet的嵌套式数据架构,但当层数非常多时,写起来非常麻烦和复杂,而parquet提供的schema表达方式更容易表示出多级嵌套的数据类型。
ORC原生是不支持嵌套数据格式的,而是通过对复杂数据类型特殊处理的方式实现嵌套格式的支持,例如对于如下的hive表:
CREATE TABLE `orcStructTable`( `name` string, `course` struct<course:string,score:int>, `score` map<string,int>, `work_locations` array<string>)
ORC格式会将其转换成如下的树状结构(ORC的schema结构):
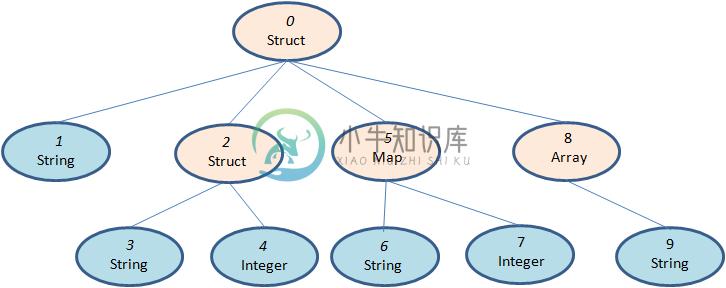
在ORC的结构中这个schema包含10个column,其中包含了复杂类型列和原始类型的列,前者包括LIST、STRUCT、MAP和UNION类型,后者包括BOOLEAN、整数、浮点数、字符串类型等,其中STRUCT的孩子节点包括它的成员变量,可能有多个孩子节点,MAP有两个孩子节点,分别为key和value,LIST包含一个孩子节点,类型为该LIST的成员类型,UNION一般不怎么用得到。每一个Schema树的根节点为一个Struct类型,所有的column按照树的中序遍历顺序编号。
ORC只需要存储schema树中叶子节点的值,而中间的非叶子节点只是做一层代理,它们只需要负责孩子节点值得读取,只有真正的叶子节点才会读取数据,然后交由父节点封装成对应的数据结构返回。
文件结构
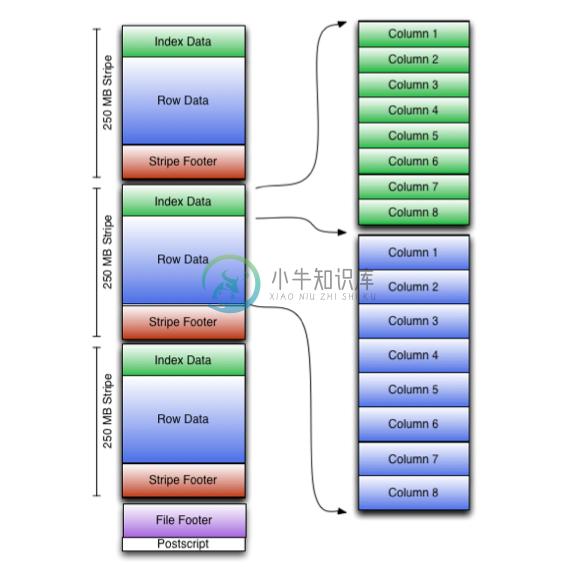
ORC 文件是以二进制方式存储的,所以是不可以直接读取,ORC文件也是自解析的,它包含许多的元数据,这些元数据都是同构ProtoBuffer进行序列化的。ORC的文件结构入图6,其中涉及到如下的概念:
ORC文件:保存在文件系统上的普通二进制文件,一个ORC文件中可以包含多个stripe,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。
文件级元数据:包括文件的描述信息PostScript、文件meta信息(包括整个文件的统计信息)、所有stripe的信息和文件schema信息。
stripe:一组行形成一个stripe,每次读取文件是以行组为单位的,一般为HDFS的块大小,保存了每一列的索引和数据。
stripe元数据:保存stripe的位置、每一个列的在该stripe的统计信息以及所有的stream类型和位置。
row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。
stream:一个stream表示文件中一段有效的数据,包括索引和数据两类。索引stream保存每一个row group的位置和统计信息,数据stream包括多种类型的数据,具体需要哪几种是由该列类型和编码方式决定。
在ORC文件中保存了三个层级的统计信息,分别为文件级别、stripe级别和row group级别的,他们都可以用来根据Search ARGuments(谓词下推条件)判断是否可以跳过某些数据,在统计信息中都包含成员数和是否有null值,并且对于不同类型的数据设置一些特定的统计信息。
更详细的介绍请看 http://blog.csdn.net/yu616568/article/details/51868447
-
Spark-submit 提交 报错 org.apache.spark.sql.execution.datasources.orc.OrcFileFormat could not be instant
错误场景 如下代码: spark.sql("select e.empno,e.ename,e.job,e.mgr,e.comm from emp e join dept d on e.deptno = d.deptno") .filter("comm is not null") .write.parquet("/demp"); spark-shell 可以跑的通,spa
-
参考:https://codecheese.wordpress.com/2017/06/13/reading-and-writing-orc-files-using-vectorized-row-batch-in-java/ 目标: orc 各种数据类型写入 orc 查询,带过滤条件,带投影 pom 依赖 <dependency> <groupId>org.apache.hadoop
-
http://cec.mpg.de/forum/ - New ORCA Release: ORCA 3.0.2 ! - ( See New Features of Version 3.0.2 ) - An ab initio, DFT and semiempirical SCF-MO package - The program ORCA is a modern electronic stru
-
1. 报错 FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. ORC split generation failed with exception: org.apache.orc.FileFormatException: Malformed ORC file file:
-
Hive迁移Spark报错org.apache.hadoop.hive.ql.io.orc.OrcStruct cannot be cast to org.apache.hadoop.io.Binar
Hive迁移后,读取报错:org.apache.hadoop.hive.ql.io.orc.OrcStruct cannot be cast to org.apache.hadoop.io.BinaryComparab 一、问题描述 Hive数据库经过迁移后,spark读取一个表,报错 Caused by: java.lang.ClassCastException: org.apache.hado
-
可为插入PS Vita的PS Vita专用存储卡进行格式化(初期化)。 已插入想格式化存储卡的状态下,轻触[格式化]>[格式化存储卡]。请遵循画面指示正确操作。 重要 进行此操作后,会自动删除存储卡内的所有数据。由于数据会永远消失,请注意别消除了重要的数据。数据一经消除即无法恢复。 格式化中请勿拔除存储卡或关闭PS Vita主机的电源。
-
我正在使用 db2 和 S 松鼠 SQL 我试图创建一个存储过程,其中包含一个简单的select语句。当我省略下面的select语句并运行代码时,过程就创建好了。这个过程也可以被删除和调用。 当我添加select语句时,我得到错误:DB2 SQL错误:SQLCODE=-102,SQLSTATE=42601,... 如果你去IBM iseries信息中心,它会说: SQL0104 SQLCODE-1
-
11:12:17,289信息[org.apache.Coyote.http11.http11protocol](MSC服务线程1-2)JBWeb003001:Coyote http/1.1正在初始化:http-/0.0.0.0:8080 11:12:17,297信息[org.apache.Coyote.http11.http11protocol](MSC服务线程1-2)JBWeb003000:Co
-
问题内容: 我想在Elasticsearch中添加一个日期时间字符串时遇到问题。 该文件如下: 该文档提出了一个错误 我知道我可以在Elasticsearch中使用日期格式,但是即使阅读网站上的文档,我也不知道如何使用。 和 错了。 如何在Elasticsearch中将datetime字符串转换为日期格式? 如何将datetime字符串直接存储到Elasticsearch中? 问题答案: 你快到了
-
Blackwidow本质上是基于rocksdb的封装,使本身只支持kv存储的rocksdb能够支持多种数据结构, 目前Blackwidow支持五种数据结构的存储:String结构(实际上就是存储key, value), Hash结构,List结构,Set结构和ZSet结构, 因为Rocksdb的存储方式只有kv一种, 所以上述五种数据结构最终都要落盘到Rocksdb的kv存储方式上,下面我们展示B
-
nemo本质上是对rocksdb的改造和封装,使其支持多数据结构的存储(rocksdb只支持kv存储)。总的来说,nemo支持五种数据结构类型的存储:KV键值对(为了区分,nemo的的键值对结构用大写的“KV”表示)、Hash结构、List结构、Set结构和ZSet结构。因为rocksdb的存储方式只有kv一种结构,所以以上所说的5种数据结构的存储最终都要落盘到rocksdb的kv存储方式上。 1
-
我使用的网格使用分页,因此它使用ListLoader/MemoryProxy来管理页面。但在这种情况下,商店在任何给定时间都只知道当前页面中的项目。我还使用了支持排序的GroupingView(remoteSort=false)。但它只根据商店中的内容进行排序,即当前页面。但是,如果一个组扩展到第二个页面,排序将不考虑另一个页面上的组条目,因此在这种情况下排序是不正确的。有人对如何解决这个问题有什
-
本文向大家介绍关于图片存储格式的整理(JPEG格式介绍),包括了关于图片存储格式的整理(JPEG格式介绍)的使用技巧和注意事项,需要的朋友参考一下 JPG jpg全名是JPEG 。JPEG 图片以 24 位颜色存储单个光栅图像。JPEG 是与平台无关的格式,支持最高级别的压缩,不过,这种压缩是有损耗的。渐近式 JPEG 文件支持交错。 jpg功能 可以提高或降低 JPEG文件压缩的级别。但是,