
TPU-MLIR 是一个专注于 AI 芯片的 TPU 编译器开源工程,提供了一套完整的工具链,可以将不同框架下预训练过的深度学习模型,转化为可以在 TPU 上运行的二进制文件 bmodel,从而实现更高效的推理。
MLIR (Multi-Level Intermediate Representation) 是一种用来构建可重用和可扩展编译基础设施的新方法,由 LLVM 原作者 Chris Lattner 在 Google 工作时期开发,MLIR 目的是做一个通用、可复用的编译器框架,解决软件碎片化,改进异构硬件的编译,显著减少构建特定领域编译器的成本。
整体架构
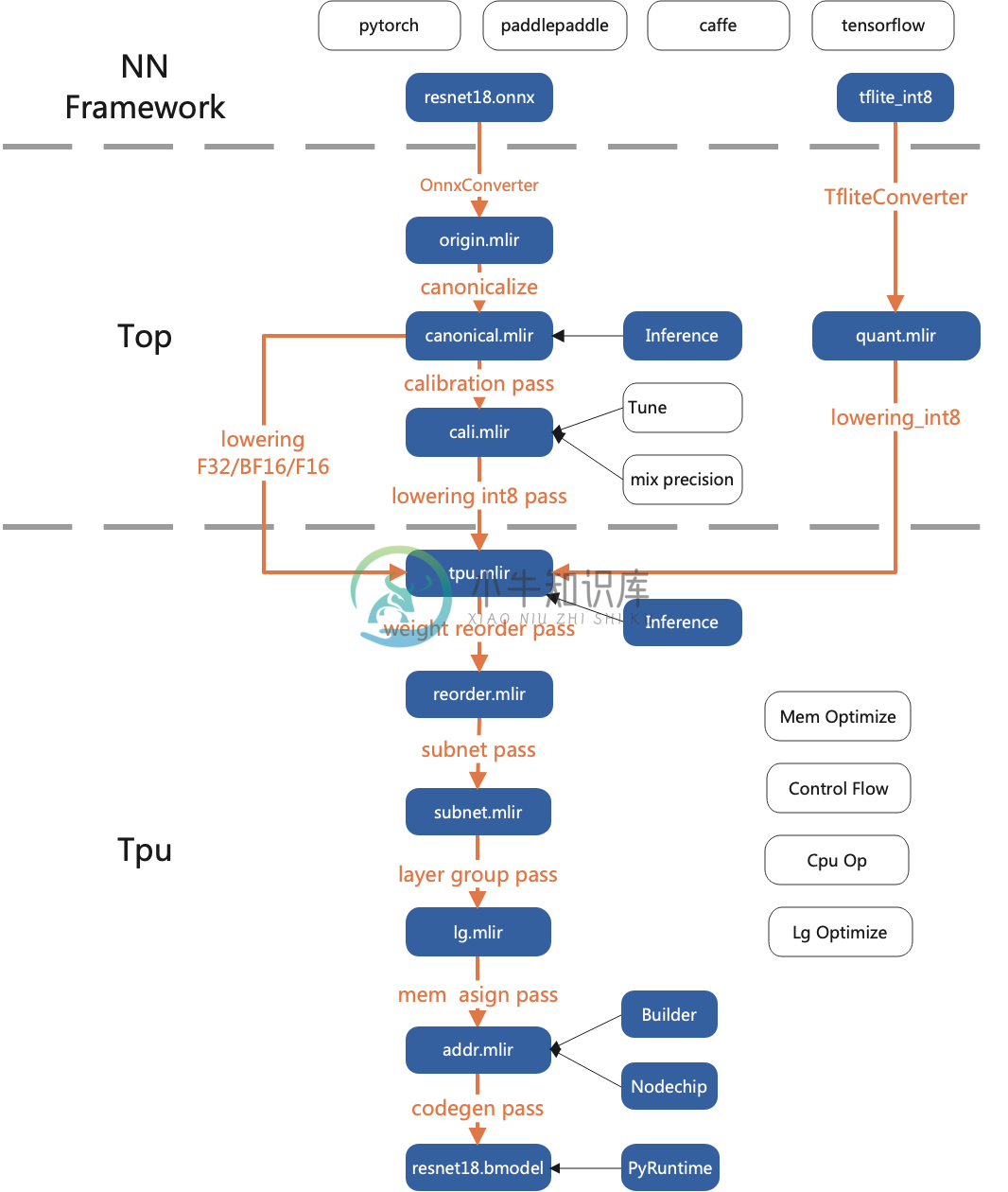
特性
TPU-MLIR 相对其他编译工具,有以下几个优势:
- 简单:通过阅读开发手册与工程中已包含的样例,用户可以了解模型转化流程与原理,快速上手。并且,TPU-MLIR基于当前主流的编译器工具库MLIR进行设计,用户也可以通过它来学习MLIR的应用。
- 便捷:该工程已经提供了一套完备的工具链,用户可以直接通过现有接口快速地完成模型的转化工作,不用自己适配不同的网络。
- 通用:目前 TPU-MLIR 已经支持 TFLite 以及 onnx 格式,这两种格式的模型可以直接转化为 TPU 可用的 bmodel。如果不是这两种格式呢?实际上 onnx 提供了一套转换工具,可以将现在市面上主流深度学习框架编写的模型转为 onnx 格式,然后就能继续转为 bmodel 了。
- 精度与效率并存:模型转换的过程中有时会产生精度损失,TPU-MLIR 支持 INT8 对称和非对称量化,在大幅提高性能的同时又结合原始开发企业的 Calibration 与 Tune 等技术保证了模型的高精度。不仅如此,TPU- MLIR 中还运用了大量图优化和算子切分优化技术,以保证模型的高效运行。
-
我使用maven命令来清理、构建整个项目、创建war并部署到服务器。我不能使用Intellij来做这件事,因为我只有社区版。它在与intellij相同的目录中构建项目。 为了加快速度,我编写了一个脚本,可以在本地“target”目录中找到比服务器中更新的已编译文件,并进行复制。虽然一切正常,但问题是Intellij并没有将使用maven编译的类视为应该跳过并重新构建整个项目的类。 目前它的工作原理
-
词法分析器 语法分析器 语义分析及中间代码生成 代码优化 代码生成
-
编译器 编译器将用一种语言编写的代码转换为另一种语言,而无需更改程序的含义。还期望编译器应该使目标代码高效且在时间和空间方面得到优化。 编译器设计原理提供了翻译和优化过程的深入视图。编译器设计涵盖了基本的转换机制以及错误检测与恢复。它包括词法,语法和语义分析作为前端,以及代码生成和优化作为后端。 为什么要学习编译器设计? 计算机是软件和硬件的平衡组合。硬件只是机械设备的一部分,其功能由兼容的软件控
-
准备工作 Ubuntu 16.04 $ apt-get install build-essential subversion libncurses5-dev zlib1g-dev gawk gcc-multilib flex git-core gettext libssl-dev unzip texinfo device-tree-compiler dosfstools libusb-1.0-0-
-
在你制作安装程序时创建了你的脚本后所要做的第二件事就是编译你的脚本。MakeNSIS.exe 就是 NSIS 编译器。它会载入你的脚本,解析并创建你的安装程序。 要编译你需要在你的 .nsi 文件上点右键并选择“Compile NSIS Script”或“Compile NSIS Script (Choose Compressor)”。这样将会使用 MakeNSISw 来引导并调用 MakeNSI