
 Collector
Collector

-
项目cacubd-server-collector的部署运行 1.配置测试环境的配置信息application-test.yml spring: rabbitmq: host: X.X.X.X port: 5672 username: admin password: ****** logging: file: logs/application_log
-
我的Ionic 5应用程序中有以下Firestore数据库结构。 书(集合) {bookID}(带有book字段的文档) 赞(子集合) {userID}(文档名称作为带有字段的用户ID) 集合中有文档,每个文档都有一个子集合。Like collection的文档名是喜欢这本书的用户ID。 我正在尝试进行查询以获取最新的,同时尝试从子集合中获取文档以检查我是否喜欢它。 我在这里做的是用每个图书ID调
-
问题内容: 我正在寻找详细描述python垃圾回收如何工作的文档。 我对在哪个步骤中完成操作很感兴趣。这三个集合中有哪些对象?在每个步骤中删除哪些对象?参考循环使用什么算法? 背景:我正在实施一些必须在短时间内完成的搜索。当垃圾收集器开始收集最旧的一代时,它比其他情况“慢很多”。它花费了比计划的更多时间。我正在寻找如何预测何时收集最老的一代以及需要多长时间。 很容易预测何时使用和收集最老的一代。也
-
我正在寻找一种通过文档id而不是字段进行查询的方法。 可能是这样的: 在这种情况下,searchInput是一个不完整的documentId。 我在Stackoverflow上看到了一个解决方案,但它不适用于Flatter:https://stackoverflow.com/a/52252264/8539070 要记住的另一件事是,我正在尝试显示集合中与id的某些部分匹配的所有文档的列表。 谢谢你
-
是否可以将在集群节点上运行的服务注册为观察者,以便在th集群中跨多个cosmos db帐户为文档集合更改提要? https://docs.microsoft.com/en-us/azure/cosmos-db/serverless-computing-database 如何通过changefeed处理器库触发服务APIendpoint?或者,如何将集群节点上运行的服务注册为观察者,以便跨集群中的多
-
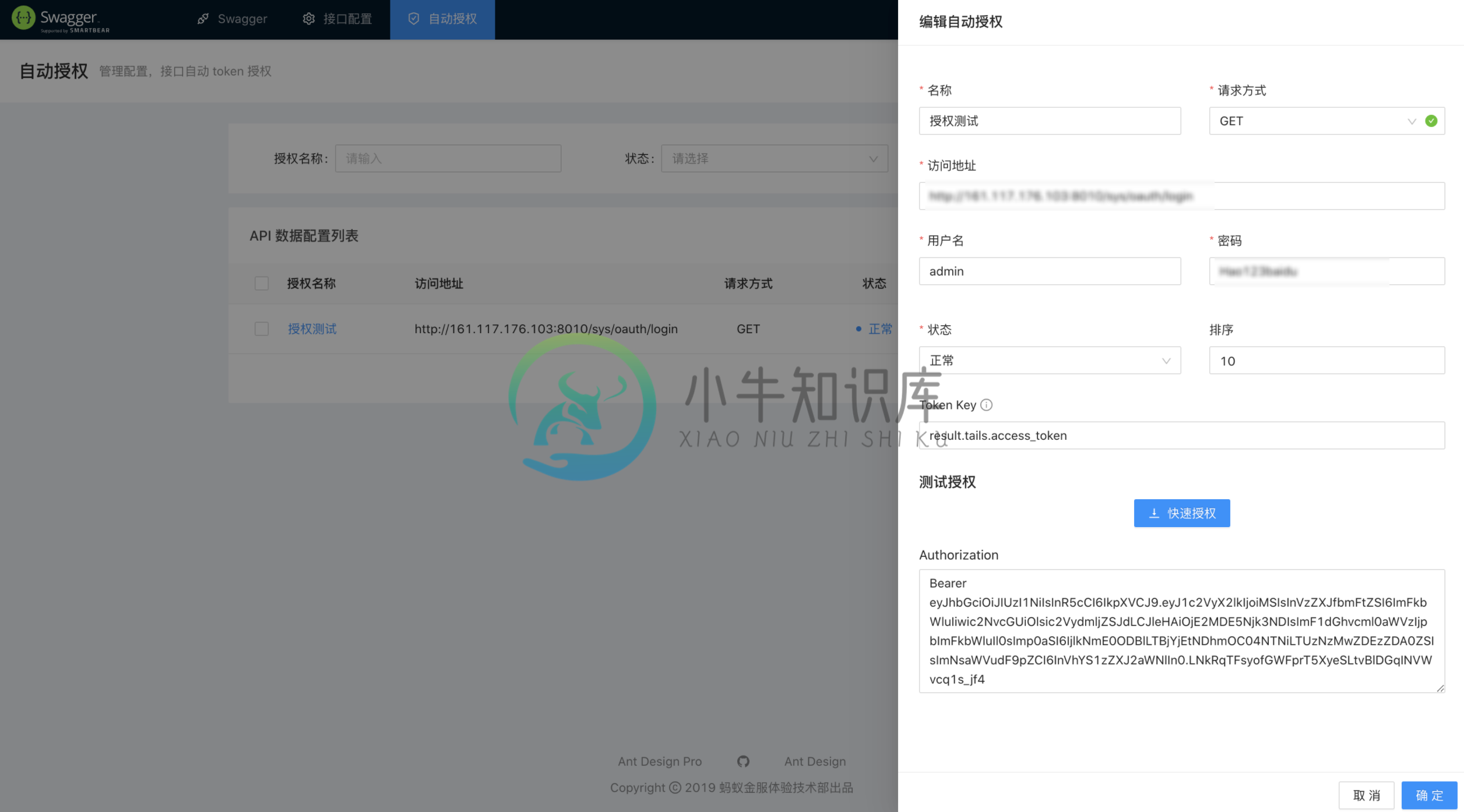
支持在项目中使用 Swagger 注解语法,运行命令,生成 Swagger 文件。 Swagger 是最流行的 API 开发工具,它遵循 OpenAPI Specification(OpenAPI 规范,也简称 OAS)。 Swagger 可以贯穿于整个 API 生态,如 API 的设计、编写 API 文档、测试和部署。 Swagger 是一种通用的,和编程语言无关的 API 描述规范。 imi-
-
更改历史 * 2018-02-13 邢足健 无过滤条件时,省略filters传参,修改下划线格式字段为驼峰 * 2018-03-06 邢足健 添加批量创建与批量删除接口 * 2018-03-19 管鹏波 基于filters增加或的查询 1.查询接口 * /tables 获取列表,接口名为表名的复数形式 @param pageNo 整数,如1
-
我在一个带注释的对象中有几个枚举,如: 其中枚举定义为: 使用Openapi3,我可以生成一个swagger文档。我的问题是,和,翻译方式不同,如: 我希望< code>Enum2与< code>Enum1一样被记录,因此具有实际的枚举值。有什么方法可以强制这样做,或者解释为什么会这样?两个枚举基本上与示例中的相同。
-
我使用了Swagger UI来显示我的REST Web服务,并将其托管在服务器上。 然而,这种招摇过市的服务只能在特定的服务器上访问。如果我想脱机工作,有人知道我如何使用Swagger UI创建静态PDF并使用它吗?此外,PDF很容易与无权访问服务器的人共享。 非常感谢!