
ItSucks 是一个 java web spider(web 机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
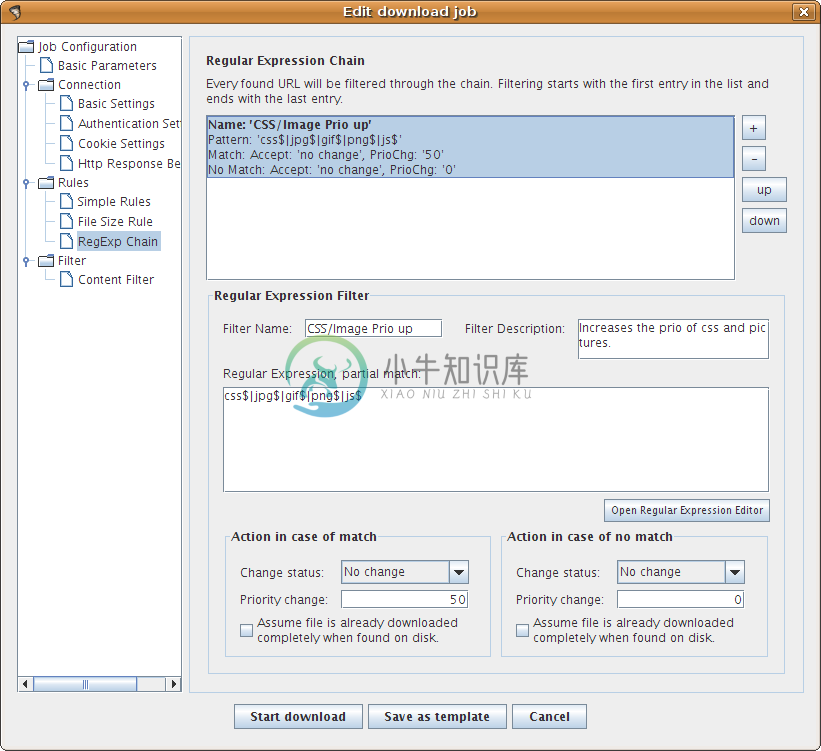
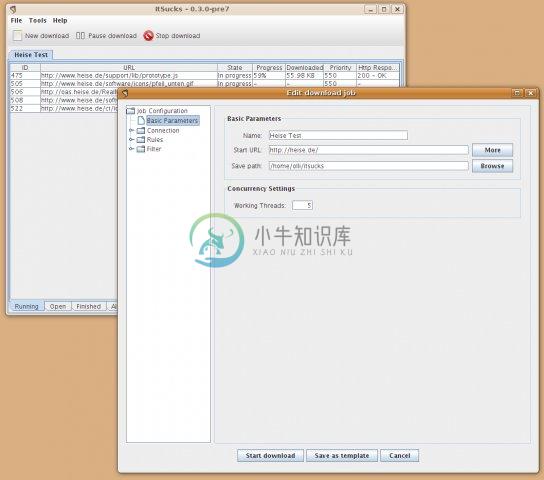
-
全球金融萧条,原以为不玩股票的我可以置身事外,原来不可以的。 今天公司的高层集体过来GZ的研发中心开会,天真的我还以为是领导们的月报会议,听着听着才发现原来是公司的裁员宣言。 虽然这次裁员危机没有波及到我,但是我的上司离开了我,很多我尊敬喜欢的同事离开了我; 很伤心真的很伤心,仿佛回到了大学毕业分离时候。虽然知道大家各有前程,但仍然伤感,因为你的未来可能已经没有了我的足迹。 伤心之余,不禁感叹,原
-
When you have a job that pays you enough to cover your basic needs, your bills and even some more to spend, the assumption is that you’d be happy, or, even better, fulfilled. And it seems unthinkable
-
原文地址: http://www.artima.com/weblogs/viewpost.jsp?thread=71730 By Dave Astels September 27, 2004 ======================================================== Summary If you are like most, and possibly even
-
A very good friend of mine is in the midst of an avalanche of work. He has a lot of open contracts, and has been abandoned by a fellow developer that was helping him with his workload. So, wi
-
折腾了一下午空压机,失败,作罢!作为一个搞IT的,虽然不会去关注怎么修主板,但起码还是会持续关注自己感兴趣的那一面的,比如iptables,Netfilter等,对于空气压缩机,Python,气缸,C++对象模型之类的,不是我的菜啊! 在论坛看到有人吐嘈,简短的一句话: ipfwadm.. ipchains.. iptables.. nftables... progress suck
-
主要内容:认识爬虫,爬虫分类,爬虫应用,爬虫是一把双刃剑,为什么用Python做爬虫,编写爬虫的流程网络爬虫又称网络蜘蛛、网络机器人,它是一种按照一定的规则自动浏览、检索网页信息的程序或者脚本。网络爬虫能够自动请求网页,并将所需要的数据抓取下来。通过对抓取的数据进行处理,从而提取出有价值的信息。 认识爬虫 我们所熟悉的一系列搜索引擎都是大型的网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都拥有自己的爬虫程序,比如 360 浏览器的爬虫称作 360Spider,搜狗的爬虫叫做
-
案例:爬取百度新闻首页的新闻标题信息 url地址:http://news.baidu.com/ 具体实现步骤: 导入urlib库和re正则 使用urllib.request.Request()创建request请求对象 使用urllib.request.urlopen执行信息爬取,并返回Response对象 使用read()读取信息,使用decode()执行解码 使用re正则解析结果 遍历输出结果
-
5.1 网络爬虫概述: 网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 网络爬虫按照系统结构和实现技术,大致可分为一下集中类型: 通用网络爬虫:就是尽可能大的网络覆盖率,如 搜索引擎(百度、雅虎和谷歌等…)。 聚焦网络爬虫:有目标性,选择性地访问万维网来爬取信息。 增量式网络爬虫:只爬取新产生的或者已经更新的页面信息。特点:耗费
-
图片来源于网络 1. 爬虫的定义 网络爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。—— 百度百科定义 详细定义参照 慕课网注解: 爬虫其实是一种自动化信息采集程序或脚本,可以方便的帮助大家获得自己想要的特定信息。比如说,像百度,谷歌等搜索引擎
-
问题内容: 如何过滤来自网络抓取工具等的点击。不是人类的点击。 我使用maxmind.com从IP请求城市。.如果我必须支付所有点击数(包括网络抓取工具,机器人等)的话,这并不便宜。 问题答案: 有两种检测机器人的一般方法,我将它们称为“礼貌/被动”和“激进”。基本上,您必须使您的网站出现心理障碍。 有礼貌 这些是礼貌地告诉抓取工具他们不应该抓取您的网站并限制抓取频率的方法。可以通过robots.
-
本文向大家介绍利用C#实现网络爬虫,包括了利用C#实现网络爬虫的使用技巧和注意事项,需要的朋友参考一下 网络爬虫在信息检索与处理中有很大的作用,是收集网络信息的重要工具。 接下来就介绍一下爬虫的简单实现。 爬虫的工作流程如下 爬虫自指定的URL地址开始下载网络资源,直到该地址和所有子地址的指定资源都下载完毕为止。 下面开始逐步分析爬虫的实现。 1. 待下载集合与已下载集合 为了保存需要下载的URL