
PolarDB-X 是一款面向超高并发、海量存储、复杂查询场景设计的云原生分布式数据库系统。其采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,具备企业级、云原生、高可用、高度兼容 MySQL 系统及生态等特点。
PolarDB-X 最初为解决阿里巴巴天猫“双十一”核心交易系统数据库扩展性瓶颈而生,之后伴随阿里云一路成长,是一款经过多种核心业务场景验证的、成熟稳定的数据库系统。 PolarDB-X 的核心特性如下:
- 水平扩展
PolarDB-X 采用 Shared-nothing 架构进行设计,支持多种 Hash 和 Range 数据拆分算法,通过隐式主键拆分和数据分片动态调度,实现系统的透明水平扩展。
- 分布式事务
PolarDB-X 采用 MVCC + TSO 方案及 2PC 协议实现分布式事务。事务满足 ACID 特性,支持 RC/RR 隔离级别,并通过一阶段提交、只读事务、异步提交等优化实现事务的高性能。
- 混合负载
PolarDB-X 通过原生 MPP 能力实现对分析型查询的支持,通过 CPU quota 约束、内存池化、存储资源分离等实现了 OLTP 与 OLAP 流量的强隔离。
- 企业级
PolarDB-X 为企业场景设计了诸多内核能力,例如 SQL 限流、SQL Advisor、TDE、三权分立、Flashback Query 等。
- 云原生
PolarDB-X 在阿里云上有多年的云原生实践,支持通过 K8S Operator 管理集群资源,支持公有云、混合云、专有云等多种形态进行部署,并支持国产化操作系统和芯片。
- 高可用
通过多数派 Paxos 协议实现数据强一致,支持两地三中心、三地五副本等多种容灾方式,同时通过 Table Group、Geo-locality 等提高系统可用性。
- 兼容 MySQL 系统及生态
PolarDB-X 的目标是完全兼容 MySQL ,目前兼容的内容包括 MySQL 协议、MySQL 大部分语法、Collation、事务隔离级别、Binlog 等。
架构:
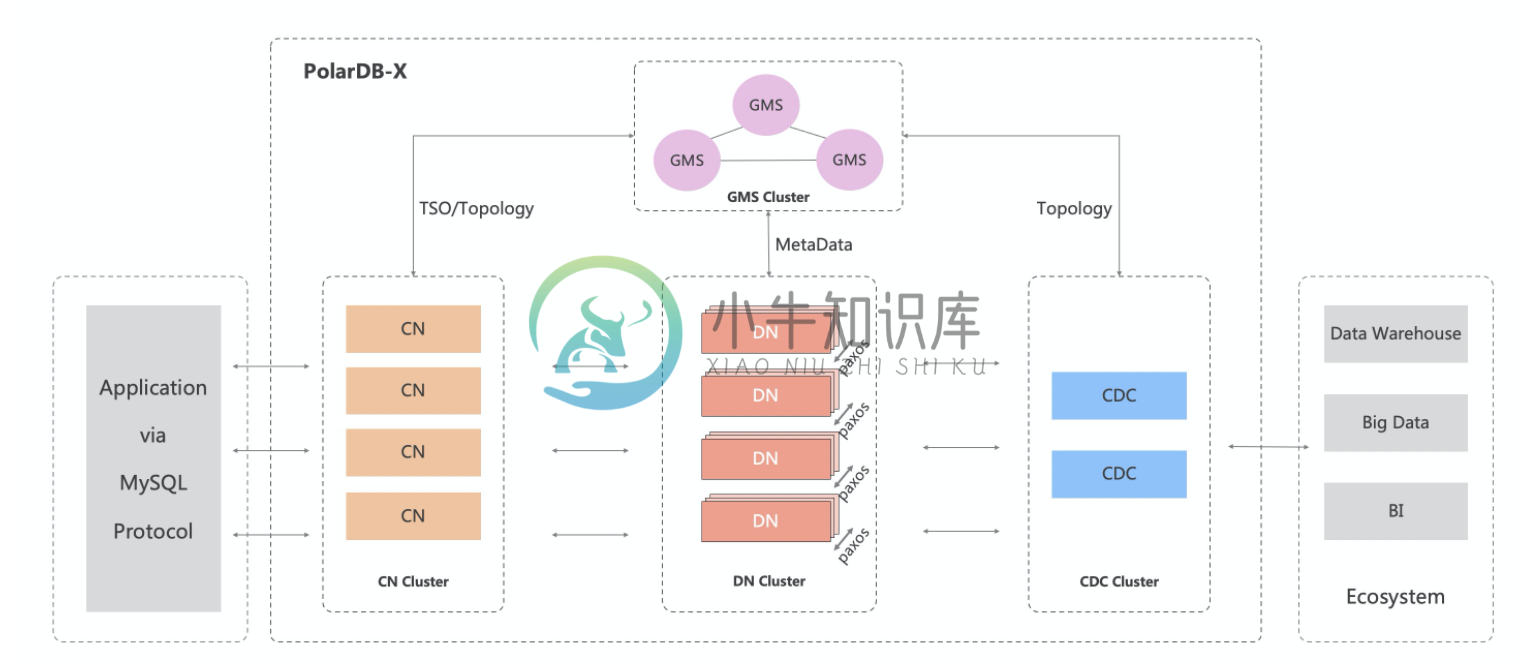
PolarDB-X 采用 Shared-nothing 与存储分离计算架构进行设计,系统由4个核心组件组成。
- 计算节点(CN, Compute Node)
计算节点是系统的入口,采用无状态设计,包括 SQL 解析器、优化器、执行器等模块。负责数据分布式路由、计算及动态调度,负责分布式事务 2PC 协调、全局二级索引维护等,同时提供 SQL 限流、三权分立等企业级特性。
- 存储节点(DN, Data Node)
存储节点负责数据的持久化,基于多数派 Paxos 协议提供数据高可靠、强一致保障,同时通过 MVCC 维护分布式事务可见性。
- 元数据服务(GMS, Global Meta Service)
元数据服务负责维护全局强一致的 Table/Schema, Statistics 等系统 Meta 信息,维护账号、权限等安全信息,同时提供全局授时服务(即 TSO)。
- 日志节点(CDC, Change Data Capture)
日志节点提供完全兼容 MySQL Binlog 格式和协议的增量订阅能力,提供兼容 MySQL Replication 协议的主从复制能力。
PolarDB-X 提供通过 K8S Operator 方式管理以上4个组件,同时计算节点与存储节点之间可通过私有协议进行 RPC 通信,这些组件对应的仓库如下。
| 组件名称 | 仓库地址 |
|---|---|
| 计算节点(CN, Compute Node) | galaxysql |
| 元数据服务(GMS, Global Meta Service) | galaxyengine |
| 存储节点(DN, Data Node) | galaxyengine |
| 日志节点(CDC, Change Data Capture) | galaxycdc |
| 私有协议 | galaxyglue |
| K8S Operator | galaxykube |
GalaxySQL 是 PolarDB-X 的计算节点(CN, Compute Node)。
-
拆分函数概述 PolarDB-X是一个支持既分库又分表的数据库服务。本文将介绍PolarDB-X拆分函数的相关信息。 拆分方式 在PolarDB-X中,一张逻辑表的拆分函数(分片数目+算法)与拆分键(&拆分键的MySQL数据类型)共同定义。如果分库和分表是相同的拆分方式,那么PolarDB-X就可以根据拆分键的值定位到唯一的物理分库和唯一的物理分表;当一张逻辑表的分库拆分方式与分表拆分方式不一致时
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
一、事务 概念 ACID AUTOCOMMIT 二、并发一致性问题 丢失修改 读脏数据 不可重复读 幻影读 三、封锁 封锁粒度 封锁类型 封锁协议 MySQL 隐式与显示锁定 四、隔离级别 未提交读(READ UNCOMMITTED) 提交读(READ COMMITTED) 可重复读(REPEATABLE READ) 可串行化(SERIALIZABLE) 五、多版本并发控制 基本思想 版本号 Un
-
每当我读到有关NoSQL分布式数据库的内容时,他们都会提到CAP定理,这意味着在分区系统中,您可以具有完全一致性,完全可用性或两者兼而有之,但不能完全两者兼而有之。 我不太清楚他们在谈论什么类型的一致性: 是数据新鲜度的一致性,其中一些客户端可能会获得比其他客户端更旧的数据吗? 或者是一致性,即事务可能仅部分完成,这可能会使数据处于不一致的状态? 第二种解释对我来说听起来很危险,不能真正接受。第一
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
本文向大家介绍NoSQL数据库的分布式算法详解,包括了NoSQL数据库的分布式算法详解的使用技巧和注意事项,需要的朋友参考一下 今天,我们将研究一些分布式策略,比如故障检测中的复制,这些策略用黑体字标出,被分为三段: 数据一致性。NoSQL需要在分布式系统的一致性,容错性和性能,低延迟及高可用之间作出权衡,一般来说,数据一致性是一个必选项,所以这一节主要是关于 数据复制 和 数据恢复 。 数据放置
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写