
Mocking Bird 是一个实时语音克隆项目,可在 5 秒内克隆声音并生成任意语音内容。
特性
- 支持普通话并使用多种中文数据集进行测试:aidatatang_200zh, magicdata, aishell3, biaobei, MozillaCommonVoice, data_aishell 等
- 适用于 Pytorch,已在 1.9.0 版本(最新于 2021 年 8 月)中测试,GPU Tesla T4 和 GTX 2060
- 可在 Windows 操作系统和 linux 操作系统中运行(苹果系统M1版也有社区成功运行案例)
- 仅需下载或新训练合成器(synthesizer)就有良好效果,复用预训练的编码器/声码器,或实时的HiFi-GAN作为vocoder
- 可将训练结果保存在服务器端,供远程调用
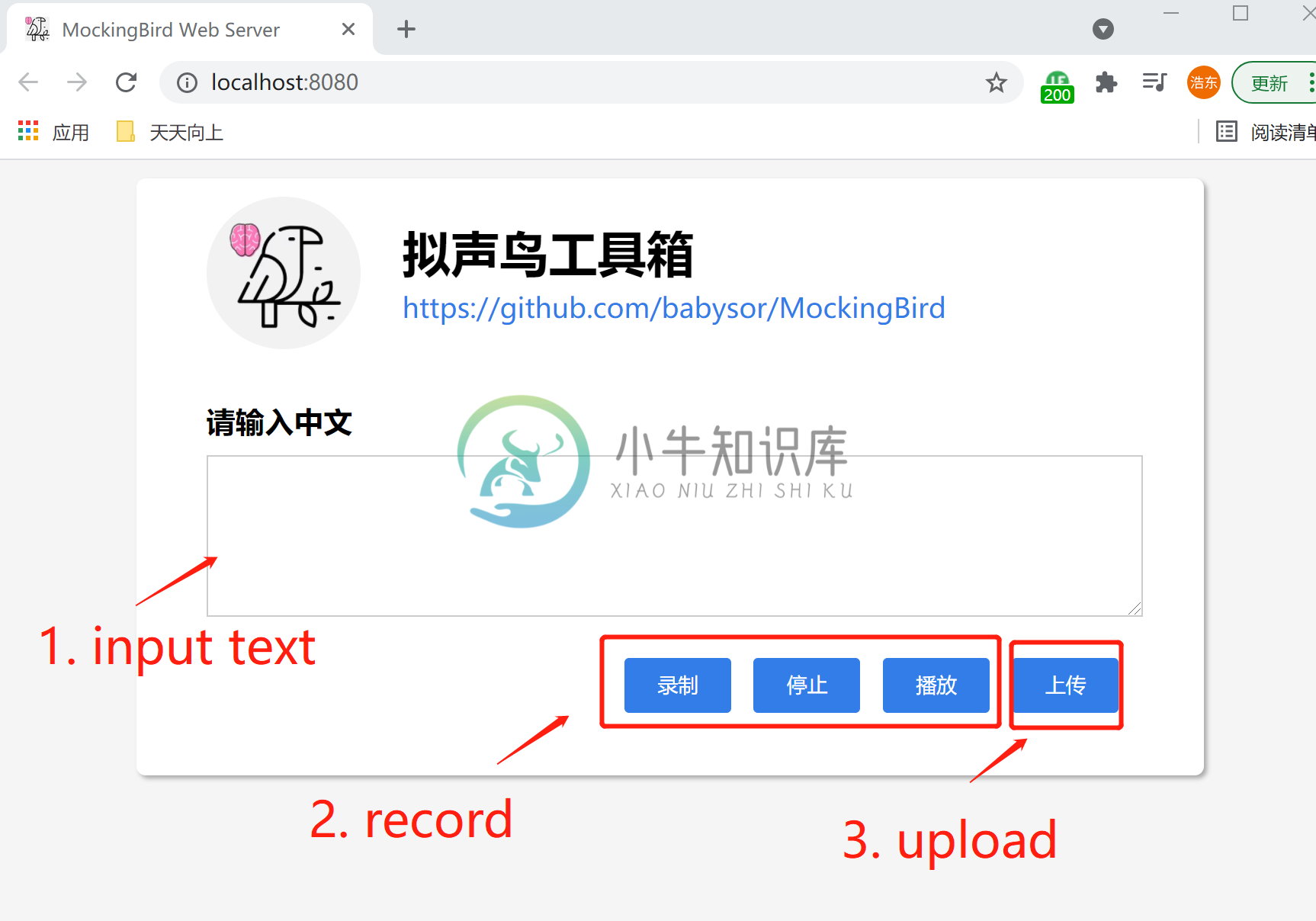
-
Mockingbird 是一个基于 Web 的在线原型设计平台,方便用于软件和网页的界面原型设计。
-
我正在开发一个用于实时翻译的Python应用程序。我需要实时识别语音:当用户说话时,它会自动将这段音频发送到谷歌语音API并返回文本。因此,我希望在说话时立即显示已识别的文本。 我发现了流式语音识别,但似乎我仍然需要先录制完整的语音,然后将其发送到服务器。此外,没有关于如何在Python中使用它的示例 是否可以使用Google Speech API执行此操作?
-
需求:语音转文字(边录边转) 前端负责 传递实时音频 后端负责 将音频准换为文本 请教: 前端采用什么方式实现语音的实时采集并通过webSocket向后端实时不间断发送 采用过js-audio-recorder方式实现过录音、但是获取到音频流后 recorder.getWAVBlob()方法会默认执行recorder.stop()录音停止、导致中断;
-
我正在使用Android API的语音识别。 我成功地遵循了以下教程:http://code4reference.com/2012/07/tutorial-android-voice-refactionation/#comment-335
-
我已经实现了云语音API流识别服务。我能够通过FLAC文件并获得输出,但它不能连续识别,也不能发出放着还在说话。一旦我的录音完成,那么只有我从云API得到响应。请建议我如何从谷歌语音API获得连续识别。请帮助我
-
js或者vue实现实时录音功能、如何实现、只录电脑系统声音、或者只录麦克风声音、用户可以自行选择录音的方式 有那些插件或者其他实现方案吗。 请求大佬指教 无
-
A.我正在努力实现的目标。 允许在网络浏览器内进行实时语音识别的网络应用程序(像这样)。 B.我目前正在考虑使用的技术来实现A。 JavaScript 节点。js WebRTC 微软语音API或Pocketsphinx。js或其他东西(不能使用Web语音API) C.非常基本的工作流程 Web浏览器建立到节点服务器的连接(服务器充当信令服务器,还提供静态文件) D.问题 将节点。js是否适合实现C
-
我正在努力寻找使用谷歌云语音API进行实时连续语音识别的例子。我的要求是使用麦克风,检测语音,并在用户说话时进行转录。 我知道他们的RESTAPI没有这种支持,所以我研究了grpc示例,包括他们提供的示例。但它们似乎都是用户可以上传音频并检测语音的例子。 我在Java,谷歌grpc也支持java。有人遇到一个很好的例子,展示了如何通过麦克风持续进行这种识别吗?