
BitSail 是字节跳动开源的基于分布式架构的高性能数据集成引擎,支持多种异构数据源间的数据同步,并提供离线、实时、全量、增量场景下的全域数据集成解决方案,目前服务于字节内部几乎所有业务线,包括抖音、今日头条等,每天同步数百万亿数据。
BitSail目前已被广泛使用,并支持数百万亿的大流量场景。同时在火山引擎云原生环境、客户私有云环境等多种场景下得到验证。
开发团队积累了很多经验,并做了多项优化,以完善数据集成的功能
- 全域数据集成解决方案, 覆盖离线、实时、增量场景
- 分布式以及云原生架构, 支持水平扩展
- 在准确性、稳定性、性能上,成熟度更好
- 丰富的基础功能,例如类型转换、脏数据处理、流控、数据湖集成、自动并发度推断等
- 完善的任务运行状态监控,例如流量、QPS、脏数据、延迟等
BitSail使用场景
- 异构数据源海量数据同步
- 流批一体数据处理能力
- 湖仓一体数据处理能力
- 高性能、高可靠的数据同步
- 分布式、云原生架构数据集成引擎
BitSail主要特点
- 简单易用,灵活配置
- 流批一体、湖仓一体架构,一套框架覆盖几乎所有数据同步场景
- 高性能、海量数据处理能力
- DDL自动同步
- 类型系统,不同数据源类型之间的转换
- 独立于引擎的读写接口,开发成本低
- 任务进度实时展示,正在开发中
- 任务状态实时监控
架构
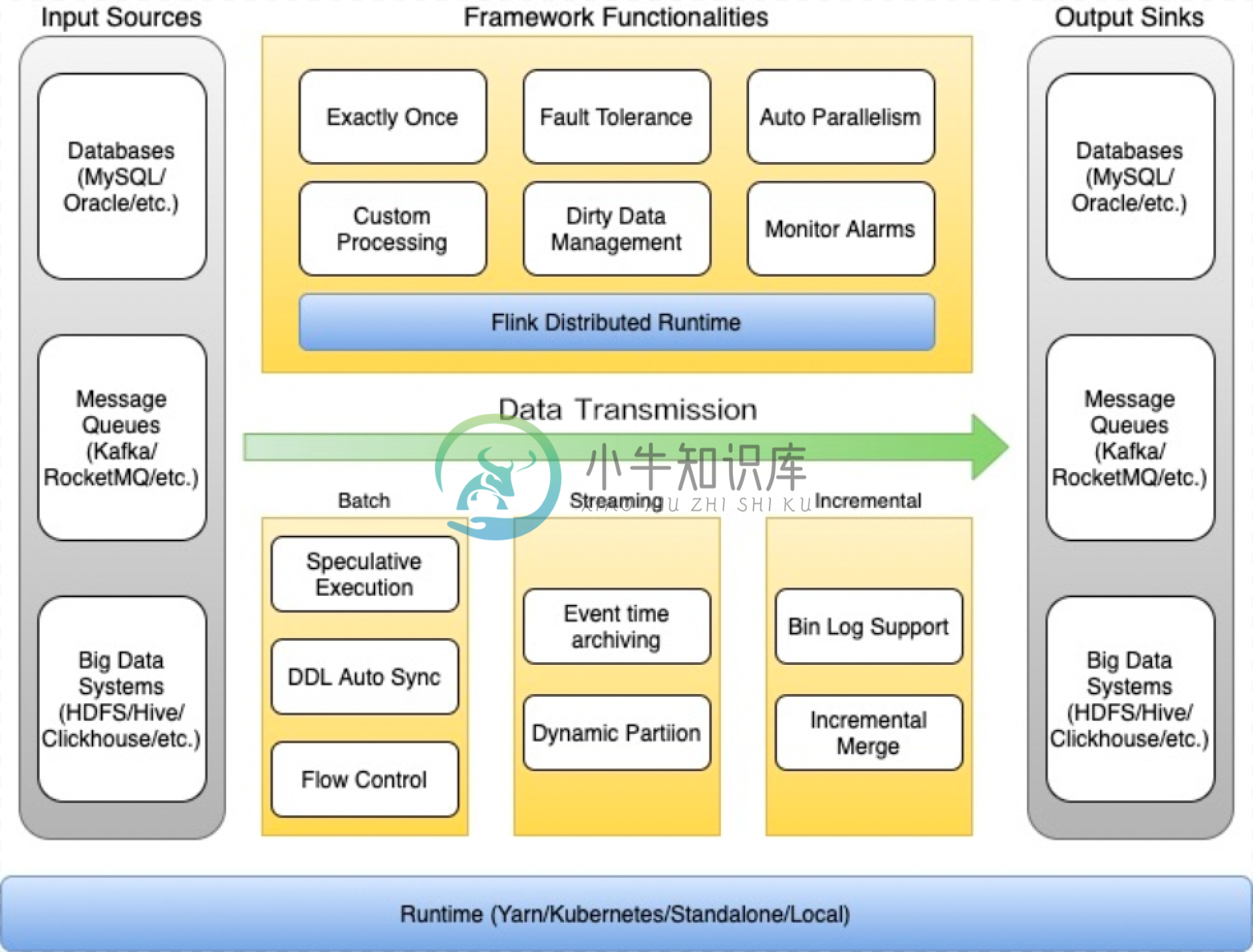
-
从Chromium的内容模块收集跟踪数据,以发现性能瓶颈和缓慢的操作 进程: 主进程 这个模块不具备web接口,需要我们在chrome浏览器中添加 chrome://tracing/ 来加载生成结果文件. 注意该模块应当在 ready事件之后使用. 1 const {contentTracing} = require('electron') 2 const options = { 3 categ
-
问题内容: 我需要一些想法来实现Java的(真正)高性能内存数据库/存储机制。在存储20,000+个Java对象的范围内,每5秒钟左右更新一次。 我愿意接受的一些选择: 纯JDBC /数据库组合 JDO JPA / ORM /数据库组合 对象数据库 其他存储机制 我最好的选择是什么?你有什么经验? 编辑:我还需要能够查询这些对象 问题答案: 您可以尝试使用Prevayler之类的工具(基本上是一个
-
问题内容: 我在公司中多次设计数据库。为了提高数据库的性能,我只寻找标准化和索引。 如果要求您提高数据库的性能,该数据库包含大约250个表以及一些具有数百万个记录的表,那么您将寻找什么不同的东西? 提前致谢。 问题答案: 优化逻辑设计 逻辑级别是关于查询和表本身的结构。首先尝试最大程度地发挥这一作用。目标是在逻辑级别上访问尽可能少的数据。 拥有最高效的SQL查询 设计支持应用程序需求的逻辑架构(例
-
问题内容: 我有一个巨大的数据集,其中包含数千行,每个行具有大约10个字段,大约2MB的数据。我需要在浏览器中显示它。最简单的方法(获取数据,将其放入,执行其工作)可以很好地工作,但是当它开始将节点插入DOM时,它会使浏览器冻结大约半分钟。我应该如何解决这个问题? 一种选择是将行逐行追加,并等待完成向DOM中插入一个块后再移至下一个。但是AFAIK ngRepeat在完成“重复”操作时不会返回报告
-
问题内容: 我有一个庞大的3D点数据集(约190万行)可供选择。我最常使用的语句类似于: 我有关于x,y和z以及otherParameter的索引。我也尝试将多部分索引添加到x,y,z,但这没有帮助。 关于如何使此查询更快的任何建议? 问题答案: 索引对于这种查询没有多大帮助。 您需要什么作为索引以及对其进行最小限度的平行六面体查询。 不幸的是,仅不支持对点的索引。但是,您可以在创建索引时,比方说