
go-stash 是一个高效的从 Kafka 获取,根据配置的规则进行处理,然后发送到 ElasticSearch 集群的工具。
go-stash 有大概 logstash 5 倍的吞吐性能,并且部署简单,一个可执行文件即可。

安装
cd stash && go build stash.go
Quick Start
- 可执行文件方式
./stash -f etc/config.yaml
- docker 方式,确保配置文件路径正确
docker run -d -v `pwd`/etc:/app/etc kevinwan/go-stash
config.yaml示例如下:
Clusters: - Input: Kafka: Name: go-stash Log: Mode: file Brokers: - "172.16.48.41:9092" - "172.16.48.42:9092" - "172.16.48.43:9092" Topic: ngapplog Group: stash Conns: 3 Consumers: 10 Processors: 60 MinBytes: 1048576 MaxBytes: 10485760 Offset: first Filters: - Action: drop Conditions: - Key: status Value: 503 Type: contains - Key: type Value: "app" Type: match Op: and - Action: remove_field Fields: - message - source - beat - fields - input_type - offset - "@version" - _score - _type - clientip - http_host - request_time Output: ElasticSearch: Hosts: - "http://172.16.188.73:9200" - "http://172.16.188.74:9200" - "http://172.16.188.75:9200" Index: "go-stash-{{yyyy.MM.dd}}" MaxChunkBytes: 5242880 GracePeriod: 10s Compress: false TimeZone: UTC
ES性能写入测试
测试环境
- stash服务器:3台 4核 8G
- es服务器: 15台 16核 64G
关键配置
- Input: Conns: 3 Consumers: 10 Processors: 60 MinBytes: 1048576 MaxBytes: 10485760 Filters: - Action: remove_field Fields: - message - source - beat - fields - input_type - offset - request_time Output: Index: "nginx_pro-{{yyyy.MM.d}}" Compress: false MaxChunkBytes: 5242880 TimeZone: UTC
写入速度平均在15W/S以上
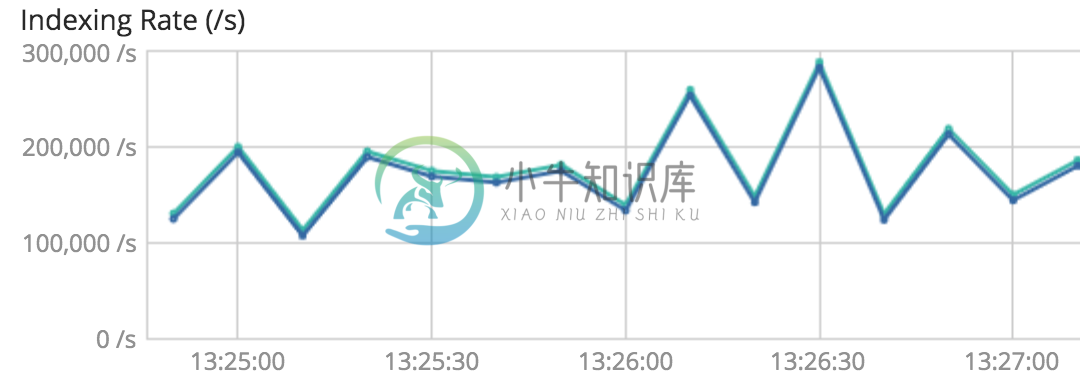
-
git stash命令:保存现场、恢复现场 功能:将git 工作区中的数据暂存起来,保存现场,以及后续的恢复现场,类似于函数调用的保存现场、恢复现场 使用场景:正在开发一个代码,编写到一半,需要将代码恢复到某个版本修复某个bug上,但已经编写的工作又想保留 用法 git stash # 保存当前现场。 git stash list # 查看当前stash缓存的内容 ## 编辑其他内容,编辑完毕
-
本文翻译自:Difference between git stash pop and git stash apply I've been using git stash pop for quite some time. 我一直在使用git stash pop一段时间了。 I recently found out about the git stash apply command. 我最近发现了gi
-
标题Go操作ElasticSearch常用接口 刚学了es,记录一下常用的接口,包括基础增删改查 index 类似sql中的 库 type 类似sql中的 表 id 类似sql中的主 键 代码如下: package main import ( "context" "encoding/json" "fmt" "github.com/olivere/elastic" log "github
-
一开始没有什么工具,慢慢的有了一些工具(轮子),工具的复制目标就是 java 或者流行的开源工具了。 总的目标就是快速的搭建项目,完成任务了。
-
问题内容: 我目前有一个电子表格类型程序,该程序将其数据保存在HashMaps的ArrayList中。当我告诉您这还不理想时,您无疑会感到震惊。开销似乎使用的内存比数据本身多5倍。 这个问题询问有效的馆藏库,答案是使用Google馆藏。 我的跟进是“ 哪一部分? ” 。我一直在阅读文档,但感觉不像是哪种类最适合。(我也向其他图书馆或建议开放)。 因此,我正在寻找可以使我以最小的内存开销存储密集电子
-
问题内容: 是否可以使用Golang以类似的方式工作,例如函数重载或C#中的可选参数?还是另一种方式? 问题答案: 直接支持函数重载和可选参数。您可以解决它们,建立自己的参数结构。我的意思是这样(未经测试,可能无法使用…)编辑:现在已测试…
-
问题内容: 出于各种原因,在编写 Java应用程序时 ,调用会被皱眉,所以如何通知调用过程并非一切都按计划进行? 编辑: 1是任何非零退出代码的。 问题答案: 当“应用程序”实际上是较大的Java应用程序(服务器)的子应用程序(例如servlet,applet)时,对的使用会被拒绝:在这种情况下,它可能会停止JVM并因此停止所有其他子应用程序。在这种情况下,抛出适当的异常(最好由应用程序框架/服务
-
问题内容: 我知道这个话题已经解决了上千次。但是我找不到解决办法。 我正在尝试计算列表(df2.list2)的列中出现列表(df1.list1的每一行)的频率。所有列表仅包含唯一值。List1包含约300.000行,list2包含30.000行。 我有一个有效的代码,但是它的运行速度非常慢(因为我使用的是迭代程序)。我也尝试过itertuples(),但它给了我一个错误(“要解压缩的值太多(预期2
-
允许我填充包含复选框和单选按钮的HTML表单的替代方法。 我已经设法使用eclipse中的HtmlUnit库将数据发送到html表单并检索页面(我已经发布了下面的Java代码)。 然而,当我将这些代码复制到我的Android项目中时,我发现Android不支持HtmlUnit库。 对于Android来说,HtmlUnit还有其他替代方案吗?另一种方法应该能够将文本、复选框、单选按钮填写到Html表
-
本文向大家介绍盘点提高 Python 代码效率的方法,包括了盘点提高 Python 代码效率的方法的使用技巧和注意事项,需要的朋友参考一下 第一招:蛇打七寸:定位瓶颈 首先,第一步是定位瓶颈。举个简单的栗子,一个函数可以从1秒优化到到0.9秒,另一个函数可以从1分钟优化到30秒,如果要花的代价相同,而且时间限制只能搞定一个,搞哪个?根据短板原理,当然选第二个啦。 一个有经验的程序员在这里一定会迟疑