
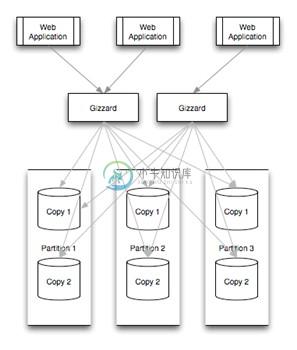
Twitter已经从以往的数据存储开发经验中提出一个名为Gizzard的Scala框架,让用户可以更方便地创建自定义容错、分布式数据库。Twitter给出了一个名为“Rowz”的示例,方便用户上手。Twitter还公布了Gizzard的完整代码。有了Gizzard,初创公司和小公司就可以更好更快地处理大量数据,从而利用更少的资源满足用户需求。
-
一面 11.1 分布式存储 阿里天池比赛,问了一些模块的优化 问存储项目 问TinyKV 项目 操作系统:cpu cache,false sharing,gdb C++:移动语义,std::map,rbtree和b+tree区别。 perf 观察程序性能 算法题:二叉树的路径和 二面 11.2 leader 面 开局先选方向:DB,分布式,操作系统,体系结构,计算机网络。选了分布式,狂问raft
-
之前的秋招面经:深信服 Go 开发面经(已 offer) bg:专升本+ACM银牌+三个项目(一个毕设的KV分离LSM-Tree,一个6824的分布式KV,一个OJ) 某小厂,存储方向技术积累还不错,避免定位就不写具体名字了。自己也一直比较憧憬做 infra 吧,不想写 CRUD 业务,所以就投了。面试内容都是事后回忆,可能有遗漏或记错的 一面 50min 自我介绍 项目实现细节、设计考量、优化(
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
一、介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成: NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,
-
null 假设我有100张唱片。缓存只能保存40条记录(最常用)和100条记录在磁盘文件(不在任何其他数据库中)。 所以,如果从这100条记录中请求任何东西,我就不必去实际的数据库(例如Sybase db)? 如果在100条记录中找到了密钥,但它不存在于内存缓存中(40条记录),则获取该密钥,放入内存缓存中,并使用驱逐策略将其他密钥交换到磁盘文件中(但在磁盘上,我总是有100条记录) 如果缓存和磁
-
问题内容: 我正在寻找Java分布式缓存解决方案。我们希望功能喜欢: 我们已经分析了Terracotta这样的框架,它似乎是缓存框架中我们想要的一切……但是,似乎需要一个中央缓存节点,这成为我们的单点故障。 除了推出我们自己的解决方案之外,还有其他想法吗? 问题答案: 我建议使用JBossCache或EhCache(使用分布式缓存侦听器)。我都用过,我都喜欢,它们都适合您的要求。