
Kyuubi 是一个高性能的通用 JDBC 和 SQL 执行引擎,建立在 Apache Spark 之上。通过 Kyuubi,用户能够像处理普通数据一样处理大数据,目标是成为数据仓库和数据湖的“开箱即用”工具。
Kyuubi 通过 Thrift JDBC/ODBC 接口为终端用户提供了一个纯 SQL 网关,以使用预编程和可扩展的 Spark SQL 引擎来操作大规模数据。这种“开箱即用”的模型最大限度地减少了终端用户在客户端使用 Spark 的障碍和成本。在服务器端,Kyuubi 服务器和引擎的多租户架构为管理员提供了一种实现计算资源隔离、数据安全、高可用、高客户端并发等途径。

Kyuubi 系统的基本技术架构如下图所示:
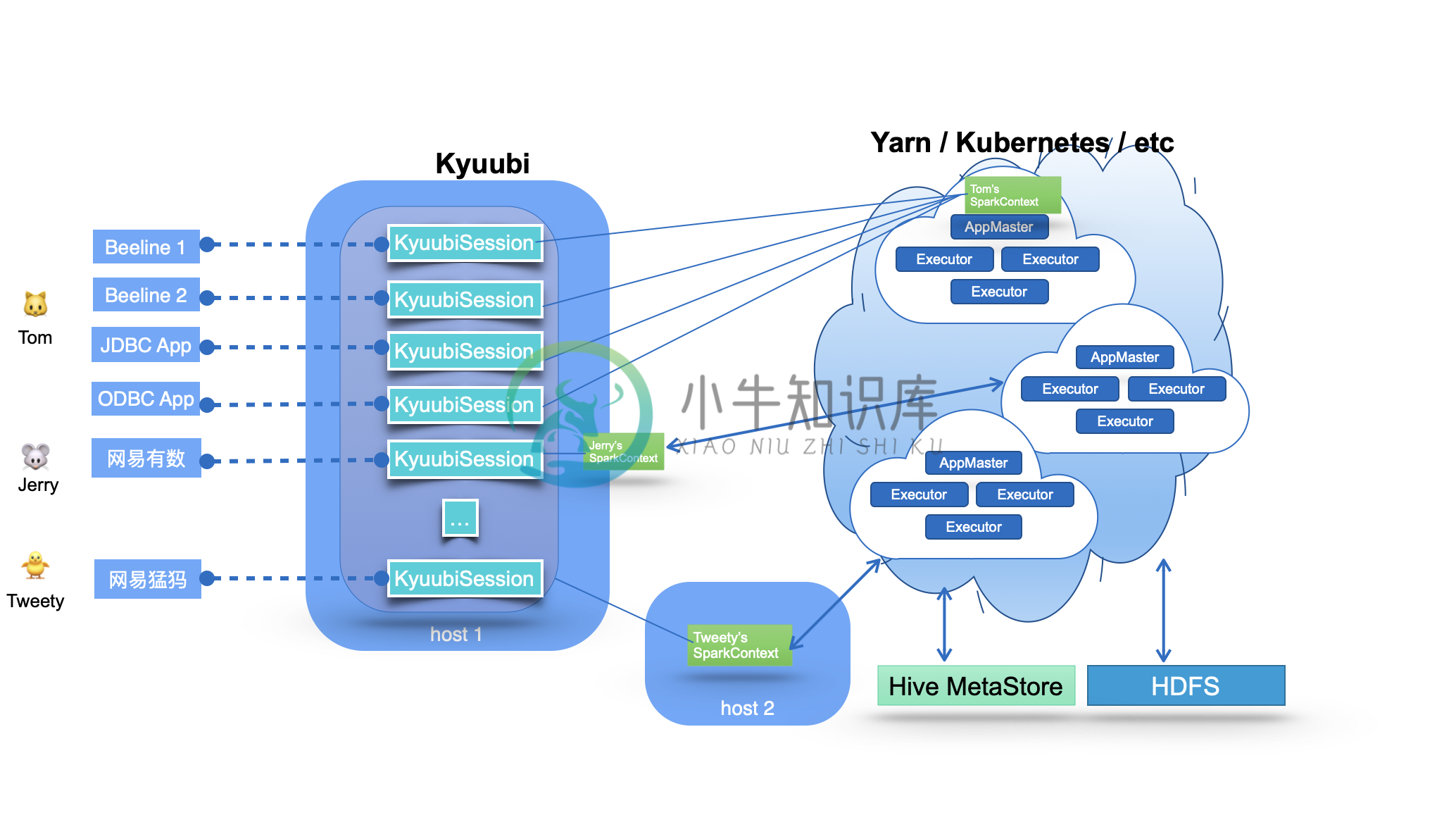
-
简介 Kyuubi是一个统一的多租户JDBC接口,用于大规模数据处理和分析,建立在Apache Spark之 上。它扩展了Spark Thrift Server在企业应用中的场景,其中最重要的是多租户支持。 一.核心 1.1 整体架构
-
1 安装kyuubi 当前最新版本:1.6.1 wget http://mirrors.ustc.edu.cn/apache/kyuubi/kyuubi-1.6.1-incubating/apache-kyuubi-1.6.1-incubating-bin.tgz 解压缩到指定目录: tar -zxvf apache-kyuubi-1.6.1-incubating-bin.tgz -C ~/s
-
问题内容: 我需要对CSV文件(以逗号分隔的文本文件)应用SQL查询。我的SQL是通过其他工具预定义的,无法更改。它可能在FROM部分中包含嵌入式选择和表别名。 对于我的任务,我发现了两个提供JDBC驱动程序 的开源 库(这是项目要求): CsvJdbc XlSQL JBoss Teiid 创建一个Apache Derby DB,将所有CSV加载为表格并执行查询。 这些是我遇到的问题: 它不接受S
-
下面给出一个例子来演示一下如何使用JDBC来执行各种SQL语句,其中包括DDL语句(建立数据库和数据表)、INSERT语句和SELECT语句。 1.程序分析说明 本程序首先创建一个mydb数据库(如果存在就不创建),然后创建一个用于保存图书信息的表t_books(如果存在,删除后再创建),最后向表中插入两条记录,并查询和显示其中的第2条记录。 2.代码编写 本程序使用了Statement接口的ex
-
是否有人知道如何提高配置单元JDBC连接的性能。 详细问题: 当我从配置单元CLI查询配置单元时,我在7秒内得到响应,但从配置单元JDBC连接,我在14秒后得到响应。我想知道是否有任何方法(配置更改)可以通过JDBC连接来提高查询的性能。 提前道谢。
-
我正在使用Java (JDBC)创建一个命令行实用程序来执行SQL语句。脚本被定义为一个文本文件,有许多查询。每个查询由查询分隔符(";"分隔).输出被路由到stdout。 由于JDBC可以批量执行语句,只有当它们不返回ResultSet时,我才需要另一种方法。 截至目前,我将读取带有查询的脚本文件,按分隔符拆分它们,并分析每个查询,无论是“SELECT”查询,还是“INSERT”,“更新”,“删
-
问题内容: 目前,我正在将JavaWeb应用程序从JDBC切换到Hibernate,在当前使用JDBC的实现中,我将应用程序初始化时将静态数据加载到静态变量中,因此我不需要每次需要一些静态数据时都直接访问数据库,现在切换到hibernate状态,据我研究,hibernate状态将加载的数据保存在缓存中,因此我想摆脱这些静态变量。 我对hibernate非常陌生,因此不确定从当前方法切换到hiber
-
我无法通过计算引擎连接到数据库。 到目前为止我所做的事情: 设置我的计算引擎 将我的计算引擎连接到我的云SQL 在我的计算引擎上安装并运行Cloud Proxy 在我的libs文件夹中包含JDBC Jar文件 创建了JDBC连接字符串 "jdbc: mysql:///? cloud dSqlInstance= -实现文件树(目录:“libs”,包括:[“*.jar”) -实现“com”。谷歌。云s
-
我做了一些调查,以了解字符串是如何工作的。intern()方法是用java实现的。 我在Open JDK 6中查看了Intern pool的C实现,在那里我看到了一个简单的哈希集。对我来说,这意味着当有人试图实习一个字符串时,接下来的步骤应该完成: 查找与给定字符串关联的哈希代码 很多人都这么说str1。intern()=str2。intern()将比str1快。等于(str2)。 但我不明白为什
-
我有一个情况需要处理,我有我的liquibase按照推荐的最佳实践进行结构化。更改日志xml的结构如下所示 在我们的应用程序组中,我们运行updateSQL来生成统一的sql文件,并通过我们的DBA组执行更改。 如何在Liquibase ChangeLog中包含这些常见的重复语句。