
51妹子图手机端,涵盖不同风格、不同类型的优质高清的美女图片,客户端对图片进行了压缩缓存处理,省流量更流畅,无需登录即可免费浏览各种类型的高清妹子图片,炫丽的瀑布流效果,让妹子尽收你眼底,赶快来发现只属于你的专属美女吧。
功能模块比较简单,调用百度图片api地址,解析展示在手机端,支持图片缩放,集成了社会化分享组件和万普广告平台sdk,软件为业余制作,可能不是很完美,现在开放源代码,供新手和有需要的人学习,共同进步。
软件特色:
1、图片自适应手机屏幕、有缓存、可缩放
2、有自定义参数可在线配置(需要万普广告后台支持)是否开启广告
3、集成了社会化分享组件、可快速分享(新浪微博、QQ等)
4、开源免费可自由发布
来几张截图
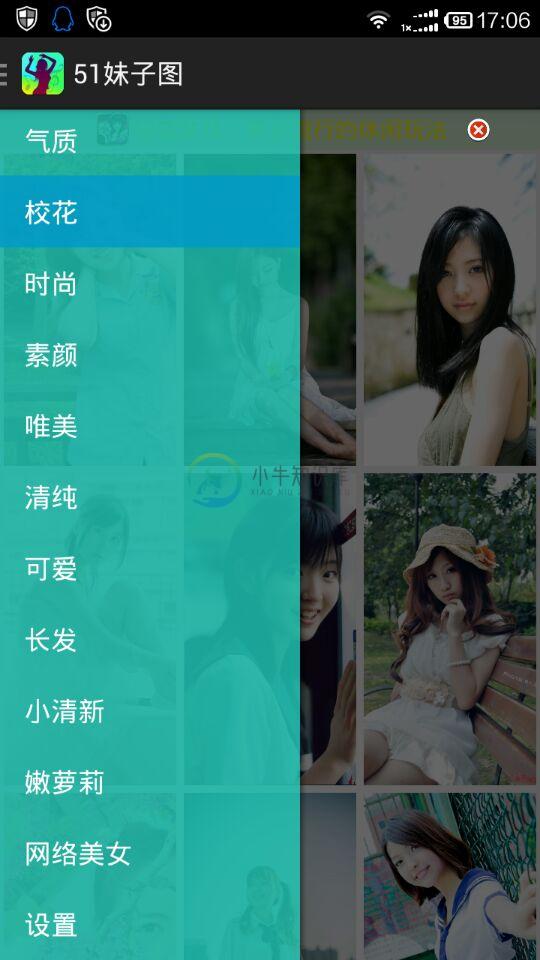

-
本文转自 https://blog.csdn.net/baidu_35085676/article/details/68958267 文中的代码,我自己跑了一遍,主要的解析的方式用的是 BeautifulSoup 但是代码跑起来可能会出现一些问题 TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。个人觉得应该是网
-
爬取图片有一个要注意的点是要对jpg那条链接在解析一次然后.write写入文件。 import requests import re '''深入的源代码才能发现契机~''' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' 'AppleWebKit/537.36 (KHTML, li
-
知识点:多线程/BeautifulSoup/正则表达式/hashlib/base64/requests 参考: python爬虫之反爬虫情况下的煎蛋网图片爬取初步探索 煎蛋网的反扒用了个障眼法..首页读出的img地址是类似这样的. </span><p><img src="//img.jandan.net/img/blank.gif" onload="jandan_load_img(this)" /
-
1 # -*- coding:utf-8 -*- 2 """ 3 下载煎蛋妹子到本地,通过selenium、正则表达式、phantomjs、Beautifulsoup实现 4 """ 5 6 import re 7 import os 8 9 from selenium import webdriver 10 from selenium.webdriver.support.wa
-
因为不熟悉的缘故,总觉得写的不好,一种异步代码与同步代码参杂着的感觉,希望能够得到指点。 import os import re import aiofiles import aiohttp import asyncio from lxml import etree # 发请求获取html文本 async def fetch(session, url): async with ses
-
这次是只用字符串查找的方式来找网页中图片链接的 1 #!/usr/bin/python 2 #coding:utf-8 3 import urllib.request 4 import os 5 import time 6 import random 7 8 def url_open(url): 9 # header = {} 10 # header['
-
看球泡妹子 \operatorname{看球泡妹子} 看球泡妹子 题目链接: luogu P2113 \operatorname{luogu\ P2113} luogu P2113 题目背景 2014 年巴西世界杯开幕了,现在满城皆是世界杯,商家们利用它大赚一笔,小明和小红也借此机会增进感情。 题目 本届世界杯共有 n n n 支球队, m m m 场比赛。男球迷小明喜欢看比赛,女球迷小红
-
1 # python3 2 # jiandan meizi tu 3 import urllib 4 import urllib.request as req 5 import os 6 import time 7 import random 8 9 10 def url_open(url): 11 req1 = urllib.request.Request(url,
-
最近开始学Python,人们学一门语言潜移默化的第一个命令往往那个就是 hello world! 这里也差不多,用python写了个小爬虫,爬妹子图的"照片".感觉效率好慢,应该是代码的问题, 在此献丑了!!! 需要安装两个好用的库,分别是 requests 和 Beautifulsoup,安装十分简单回头补上! 嗯~就这样 代码在 Python 2.7.8 以及 Python 3.4.1 下都
-
from threading import Thread import urllib.request import bs4 import urllib.error from queue import Queue headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like
-
51-android 可解决 linux 上 android 手机无法正常识别的问题。 在 linux 上开发 android 软件,如果 android 手机连接上了电脑,但是在终端输入 adb devices 却没有显示手机设备,那么你需要这个工具。 系统要求 Ubuntu、Fedora 或其他 Linux 系统。
-
本文向大家介绍Python使用Scrapy爬取妹子图,包括了Python使用Scrapy爬取妹子图的使用技巧和注意事项,需要的朋友参考一下 Python Scrapy爬虫,听说妹子图挺火,我整站爬取了,上周一共搞了大概8000多张图片。和大家分享一下。 核心爬虫代码 项目地址:https://github.com/ZhangBohan/fun_crawler 以上所述就是本文的全部内容了,希望大家
-
这是 OSCHINA 官方开发的 Android 客户端软件,采用原生 API 开发,非 HTML 模式。 采用 GPL 授权协议,鼓励你在这基础上进行修改和完善,并与大家分享你的版本。 下载官方版本:http://www.oschina.net/app
-
这是根据开源中国社区上Android客户端的开源代码修改而来的,把原版的客户端修改为Design风格。 去掉了每次启动时出现的画面,改为首次安装时显示。主页改为ViewPager+Fragment。 将部分按钮放进的操作栏中。修改发帖时,回复时的输入框。替换掉原版中的大部分图标。 增加浏览器页面跳转至APP功能。 这是打包好的APk。
-
okhttp底层实现? android四大组件? 为什么service进行耗时操作?不可以直接放线程里面吗? 子线程和主线程的通信方式? 子线程可以用Handler吗? 可以直接new一个吗? Looper为什么不会让主线程卡死? ANR遇到过吗? 线程池遇到过? mqtt的底层协议?如何做到长连接?通信的过程? tcp中某个包丢了会发生什么? tcp和udp的区别? mvp和mvc的区别? ht
-
问题内容: 我是android开发的新手,并希望使用Thrift客户端创建一个应用,该客户端在我的网络上使用Thrift服务器。我已经获得了Thrift定义文件和Thrift编译器生成的Java代码。 我该如何开始?如何将旧版库添加到我的项目中?我需要自己编译吗?如果是,我应该如何做到这一点以使其与Android兼容? 我可以直接使用类似于此功能的自动生成的功能吗 对我的服务进行异步调用,以便我遵