
pkuseg-python:一个高准确度的中文分词工具包
pkuseg-python 简单易用,支持多领域分词,在不同领域的数据上都大幅提高了分词的准确率。
主要亮点
pkuseg 是由北京大学语言计算与机器学习研究组研制推出的一套全新的中文分词工具包。pkuseg 具有如下几个特点:
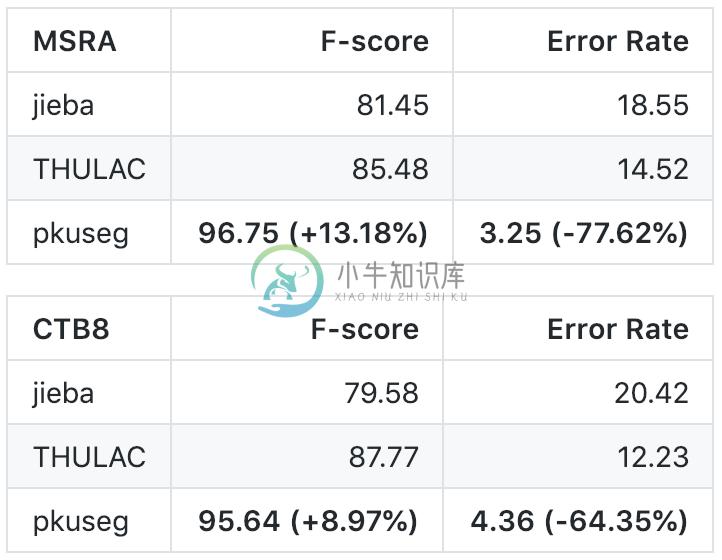
高分词准确率。相比于其他的分词工具包,我们的工具包在不同领域的数据上都大幅提高了分词的准确度。根据我们的测试结果,pkuseg 分别在示例数据集( MSRA 和 CTB8 )上降低了 79.33% 和 63.67% 的分词错误率。
多领域分词。我们训练了多种不同领域的分词模型。根据待分词的领域特点,用户可以自由地选择不同的模型。
支持用户自训练模型。支持用户使用全新的标注数据进行训练。
编译和安装
通过 pip 下载(自带模型文件)
pip install pkuseg 之后通过import pkuseg来引用
从 github 下载(需要下载模型文件,见预训练模型)
将pkuseg文件放到目录下,通过import pkuseg使用 模型需要下载或自己训练。
各类分词工具包的性能对比
我们选择 THULAC、结巴分词等国内代表分词工具包与 pkuseg 做性能比较。我们选择 Linux 作为测试环境,在新闻数据 (MSRA) 和混合型文本 (CTB8) 数据上对不同工具包进行了准确率测试。我们使用了第二届国际汉语分词评测比赛提供的分词评价脚本。评测结果如下:
代码示例
示例1
代码示例1 使用默认模型及默认词典分词
import pkuseg
seg = pkuseg.pkuseg() #以默认配置加载模型
text = seg.cut('我爱北京天安门') #进行分词
print(text)
示例2
代码示例2 设置用户自定义词典
import pkuseg
lexicon = ['北京大学', '北京天安门'] #希望分词时用户词典中的词固定不分开
seg = pkuseg.pkuseg(user_dict=lexicon) #加载模型,给定用户词典
text = seg.cut('我爱北京天安门') #进行分词
print(text)
示例3
代码示例3
import pkuseg
seg = pkuseg.pkuseg(model_name='./ctb8') #假设用户已经下载好了ctb8的模型并放在了'./ctb8'目录下,通过设置model_name加载该模型
text = seg.cut('我爱北京天安门') #进行分词
print(text)
示例4
代码示例4
import pkuseg
pkuseg.test('input.txt', 'output.txt', nthread=20) #对input.txt的文件分词输出到output.txt中,使用默认模型和词典,开20个进程
示例5
代码示例5
import pkuseg
pkuseg.train('msr_training.utf8', 'msr_test_gold.utf8', './models', nthread=20) #训练文件为'msr_training.utf8',测试文件为'msr_test_gold.utf8',模型存到'./models'目录下,开20个进程训练模型-
一,pkuseg的基本概念和亮点 1,什么是pkuseg pkuseg 是由北京大学语言计算与机器学习研究组研制推出的一套全新的中文分词工具包。 pkuseg 在github中的网址如下: https://github.com/lancopku/pkuseg-python 2,主要亮点 多领域分词。不同于以往的通用中文分词工具,此工具包同时致力于为不同领域的数据提供个性化的预训练模型。根据待分词文
-
原创致Great ChallengeHub #深度学习课程 8 #学习利器 5 编辑文章 1 简介 pkuseg-python简单易用,支持多领域分词,在不同领域的数据上都大幅提高了分词的准确率。 pkuseg是由北京大学语言计算与机器学习研究组研制推出的一套全新的中文分词工具包。pkuseg具有如下几个特点: 高分词准确率。相比于其他的分词工具包,我们的工具包在不同领域的数据上都
-
今天无意间搜寻到一个开源的项目,是北大开源的python版本的分词工具,忍不住就来试用一下,下面就是具体的实践,总体很简单,直接是拿的官方的几个接口来体验一下,主要是掌握多一个的分词工具,之前分词主要是依赖于结巴分词,这里相当于多了一个选择,据说准确率很不错,今天只是简单使用一下。 #!usr/bin/env python #encoding:utf-8 ''' __Author__:
-
pkuseg:一个多领域中文分词工具包 [(English Version)](/lancopku/pkuseg- python/blob/master/readme/readme_english.md) pkuseg简单易用,支持细分领域分词,有效提升了分词准确度。 目录 主要亮点 编译和安装 各类分词工具包的性能对比 使用方式 相关论文 作者 常见问题及解答 主要亮点 pkuseg具有如下几个
-
本部分内容部分来自:https://github.com/lancopku/PKUSeg-python 1.前言 最近看到一些博文介绍了北大的一个开源的中文分词工具包pkuseg。其中说到,它在多个分词数据集上都有非常高的分词准确率,我们所知道的,也经常使用的结巴分词误差率高达 18.55% 和 20.42,而北大的 pkuseg 只有 3.25% 与 4.32%。当然还有其他的分词工具,如:清华
-
使用pkuseg对文本文件进行分词时踩坑, 官方示例如下: import pkuseg # 对input.txt的文件分词输出到output.txt中 # 开20个进程 pkuseg.test('input.txt', 'output.txt', nthread=20) 报错如下: Traceback (most recent call last): File "<string>", lin
-
Genius Genius是一个开源的python中文分词组件,采用 CRF(Conditional Random Field)条件随机场算法。 Feature 支持python2.x、python3.x以及pypy2.x。 支持简单的pinyin分词 支持用户自定义break 支持用户自定义合并词典 支持词性标注 Source Install 安装git: 1) ubuntu or debian
-
本文向大家介绍支持汉转拼和拼音分词的PHP中文工具类ChineseUtil,包括了支持汉转拼和拼音分词的PHP中文工具类ChineseUtil的使用技巧和注意事项,需要的朋友参考一下 PHP 中文工具类,支持汉字转拼音、拼音分词、简繁互转。 PHP Chinese Tool class, support Chinese pinyin, pinyin participle, simplified a
-
介绍 现阶段,应用于搜索引擎和自然语言处理的中文分词库五花八门,使用方式各不统一,虽然有适配于Lucene和Elasticsearch的插件,但是我们想在多个库之间选择更换时,依旧有学习时间。 Hutool针对常见中文分词库做了统一接口封装,既定义一套规范,隔离各个库的差异,做到一段代码,随意更换。 Hutool现在封装的引擎有: Ansj HanLP IKAnalyzer Jcseg Jieba
-
我们的分页采用的组件化实现方式,就是把一个分页菜单拆分成多个组件,比如 总页数 , 上一页, 等。 //定制分页组件 define( 'PAGE_TOTAL_NUM', 1<<0 ); //总页数 define( 'PAGE_PREV', 1<<1 ); //上一页 define( 'PAGE_DOT', 1<< 2); //省略号 define( 'PAGE_L
-
本文向大家介绍PHPAnalysis中文分词类详解,包括了PHPAnalysis中文分词类详解的使用技巧和注意事项,需要的朋友参考一下 PHPAnalysis是目前广泛使用的中文分词类,使用反向匹配模式分词,因此兼容编码更广泛,现将其变量与常用函数详解如下: 一、比较重要的成员变量 $resultType = 1 生成的分词结果数据类型(1 为全部, 2为 词典词汇及单个中日韩简
-
中文分词是怎么走到今天的 话说上个世纪,中文自动分词还处于初级阶段,每句话都要到汉语词表中查找,有没有这个词?有没有这个词?所以研究集中在:怎么查找最快、最全、最准、最狠......,所以就出现了正向最大匹配法、逆向最大匹配法、双向扫描法、助词遍历法......,用新世纪比较流行的一个词来形容就是:你太low了! 中文自动分词最难的两个问题:1)歧义消除;2)未登陆词识别。说句公道话,没有上个世纪