
Blog4j是一个用Java实现的, 简洁的, 高效的个人独立博客.
没有使用臃肿的SSH流, 但自己构建了一个简洁高效的替代者--Run框架, 使博客运行达到最高性能, 最低耗能!
特点:
- 文章分类基于标签形式, 便于管理, 查找.
- 用markdown写作, 不再关心杂乱的HTML标签, 专心写作!
- 缓存页面
- 高性能, 低耗能
- 主题支持
- 文章置顶
- 页面支持
- 第三方评论
- 相关文章
运行环境:
- 可运行在Cloud Foundry
- SAE
- 普通Servlet容器, 如tomcat, jetty...
使用MySQL做为基础数据存储.
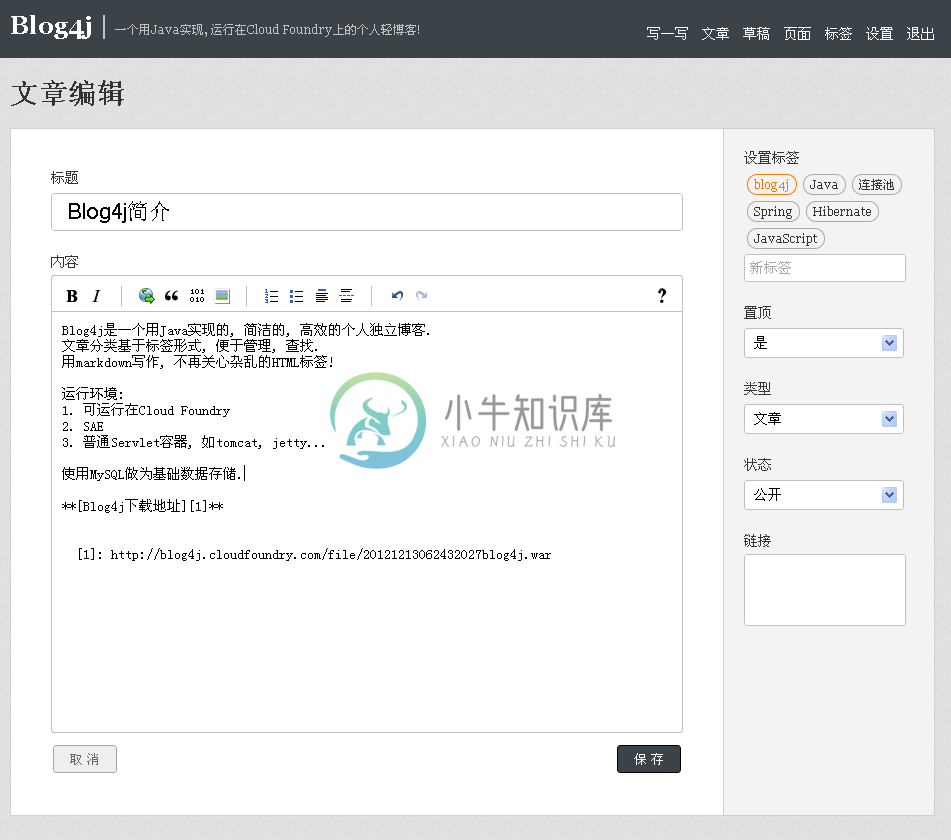
文章编辑界面-截图
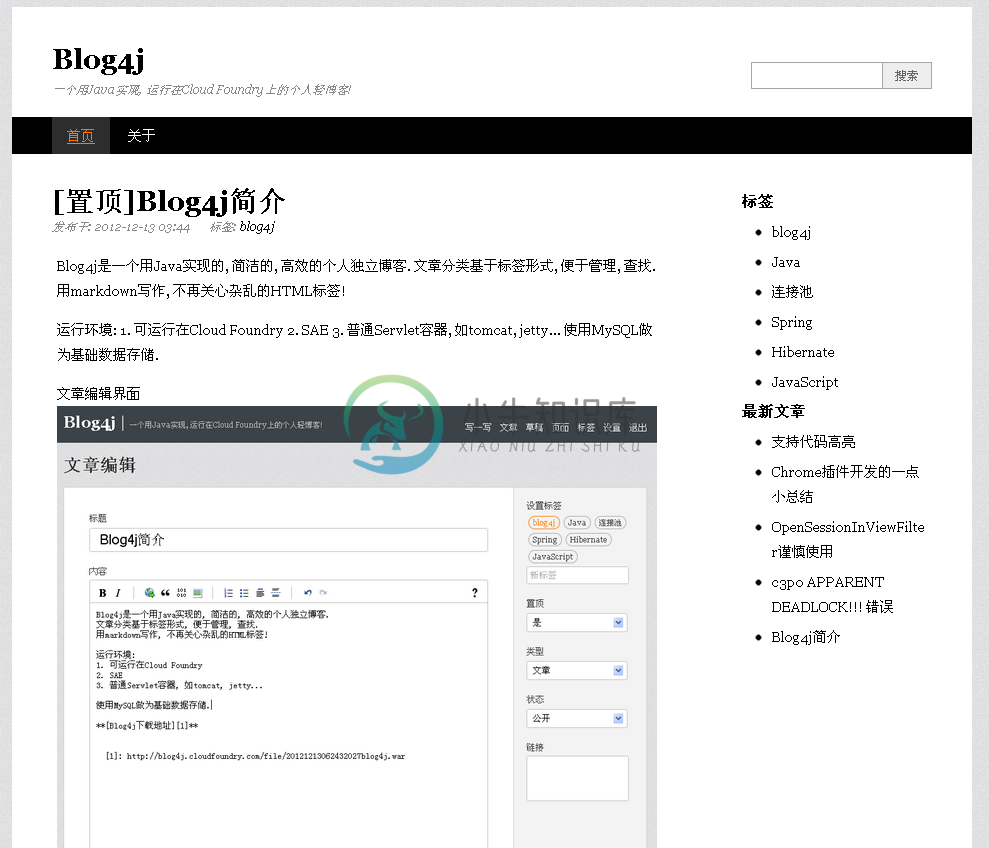
默认主题-截图
-
Slf4j与log4j及log4j2的关系及使用方法 slf4j slf4j仅仅是一个为Java程序提供日志输出的统一接口,并不是一个具体的日志实现方案,就比如JDBC一样,只是一种规则而已,所以单独的slf4j是不能工作的,必须搭配其他具体的日志实现方案,比如log4j或者log4j2,要在系统中使用slf4j,我们需要引入的核心包为:slf4j-api-1.6.4.jar。 如果不想每次都
-
刚刚接触到java log日志的同学可能会被各种日志框架吓到,包括各种日志框架之间的jar总是发生冲突,另很多小伙伴头疼不已。那我们本篇的内容就是将各种java 日志框架发展过程,以及他们之间的关系,以及如何选型来介绍给大家。 一、五花八门的日志工具包 1.1. 日志框架 JDK java.util.logging 包:java.util.logging 是 jdk1.4 发布的 java 日志包
-
我正在考虑创建一个独立的Kafka生产者,它作为守护进程运行,通过套接字接收消息,并将其可靠地发送给Kafka。 但是,我决不能是第一个想到这个想法的人。这样做的目的是避免使用PHP或Node编写Kafka生成器,而只是通过套接字将消息从这些语言传递到独立的守护进程,这些语言负责传递,而主应用程序则一直在做自己的事情。 此守护进程应负责在发生中断时进行重试传递,并充当服务器上运行的所有程序的传递点
-
咸蛋博客是wordpress,tumblr,pinterest三合一的开源博客 特点: 1:基于wordpress3.3.2,可以使用wordpress已有的所有插件,模块,继承了wordpress所有的优点 2:可以把现有博客数据快速导入咸蛋博客,把自己的博客快速变成流行的轻博客 3:6种文章形式,日志,图片,音乐,视频,引言,链接,一个完整的轻博客系统。 4:默认使用瀑布流式布局,拥有自己的p
-
我想将多个数据库的更改聚合到一个数据库中,所以我想在每个数据库旁边运行一个Debezium连接器和一个Kafka服务器/代理,并使用Kafka接收器连接器从所有这些Kafka中消费写入一个数据库。 问题是,我是否可以使用单个 Kafka 接收器连接器实例同时使用来自多个独立(不是集群)的 Kafka 代理。
-
创建验证 任何时候,都可以直接使用think\Validate类而不需要定义验证器类进行独立的验证操作,例如: $validate = Validate::make([ 'name' => 'require|max:25', 'email' => 'email' ]); $data = [ 'name' => 'thinkphp', 'email' => 't
-
我的任务是比较一些当前时期的日志和旧的日志。例如——本周日志和前一周日志。但是当我创建这样的第二个轴时 我有一个空的部分,因为我所有的xAx都是“时间”类型的,并且点的时间不一样(这是绝对正常的行为)。我有这种情况 但是我需要制作独立的轴,例如:顶部轴开始于30sep,结束于3oct底部轴开始于7oxt,结束于10oct,它们的长度都相同 我试着创造这样的斧头 但是如果没有“ticks”属性,我会
-
工人出现在图片上。为了运行我的代码,我使用了以下命令:
-
开发者可以在脱离Spring容器的情况下利用RepositoryFactory来使用Spring Data repository(比如在CDI环境下),但仍然需要将某些Spring的依赖包加到classpath中。 Example 14. Standalone usage of repository factory(独立使用) RepositoryFactorySupport factory =
-
问题内容: 我试图从另一个python脚本访问我的Django(v1.10)应用程序数据库,但遇到了一些麻烦。 这是我的文件和文件夹结构: 根据Django的文档,我看起来像这样: 但它会生成运行时错误: 我应该注意,我的INSTALLED_APPS列表包含了它的最后一个元素。 相反,如果我尝试通过这样的配置: 我得到: 如果我进行编辑和添加,LOGGING_CONFIG=None则会遇到另一个有