
百度网盘高速下载 Chrome 插件
这是一款获取百度网盘下载直链的开源 Chrome 插件,获取到直链后你可以使用迅雷下载以达到不限速的目的。
如果该插件不好使,请直接使用百度网盘不限速下载器试试!
安装
- 下载 zip 包解压
- 在 Chrome 地址栏输入
chrome://extensions以打开扩展程序管理页面 - 顶部勾选“开发者模式”,再点击“加载已解压的扩展程序...”,路径为刚才的解压目录
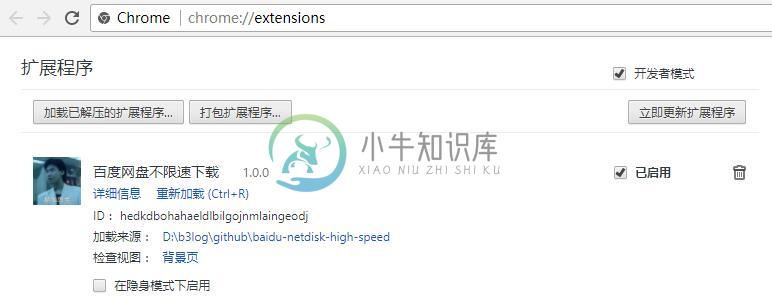
使用
- 在百度网盘下载的页面照常点击“下载”按钮
- 提取成功的话会自动新开一个页签显示直链地址
- 使用迅雷打开该直链地址即可实现高速下载
技术实现
原理
插件
- 通过调试器获取请求的响应数据,提取直链
- 阻止自动下载
反馈
鸣谢
- 百度云大文件下载破解,chrome插件
- 正在使用插件的你
-
本文向大家介绍Linux 下载百度网盘大文件的方法,包括了Linux 下载百度网盘大文件的方法的使用技巧和注意事项,需要的朋友参考一下 Linux 下没有百度网盘客户端,用浏览器下载速度慢得急死人 鼠标移到链接处, 右键, 然后复制链接 接着在终端里输入 axel 是下载程序名, -n 后面数字是线程数,多少自己决定, -o 后面下载到本机上 保持的文件名, 最后面 英文引号里面放下载链接 使用这
-
1. 自我介绍 2. 介绍项目 3. langchain是如何进行节点编排的 4. langchian的原理(面试官以为只有python可以实现,我科普了一下) 5. 实现自动缓存机制(lru)是怎么做的 6. websocket心跳和重连机制的原理,工作流程 7. 如果断网了还有必要启动重连机制吗? 8. 为什么用localForage替换localStorage 9. 还有一些项目点忘记了(网
-
我正在使用 从 Azure 存储 Blob 下载文件 (~100MB)。 我的问题是实际下载文件需要相当长的时间(大约10分钟)。我之前使用的fetch()比这个还要慢(大约15-20分钟)。关于如何加快下载速度,你们有什么建议吗?我的网速不是问题,因为直接下载文件或使用Azure Storage Explorer(1.12.0,AzCopy 10.3.3)不到两分钟。 我还尝试使用azure s
-
添加百度统计组件,用于统计页面数据。 标题 内容 类型 通用 支持布局 N/S 所需脚本 https://c.mipcdn.com/static/v2/mip-stats-baidu/mip-stats-baidu.js 说明 MIP 百度统计组件基于百度统计 API,请参照 API 将参数配置在 MIP 页。目前事件追踪支持 click, mouseup, load,其它事件暂不支持。 示例 M
-
引入百度商桥功能。 标题 内容 类型 通用 支持布局 N/S 所需脚本 https://c.mipcdn.com/static/v2/mip-bridge-baidu/mip-bridge-baidu.js 说明 引入百度商桥功能,可以通过以下两种方式之一: 通过参数 site-id 直接引入商桥 通过百度统计 token 引入商桥 示例 通过参数 site-id 直接引入商桥 <mip-brid
-
百度搜索引擎,采集百度搜索结果。 GitHub: https://github.com/jae-jae/QueryList-Rule-Baidu 安装 composer require jaeger/querylist-rule-baidu API Baidu baidu($pageNumber = 10):获取百度搜索引擎 class Baidu: Baidu search($keyword):