
-
方式一:共享文件存储迁移 尽管可以使用 repository-s3 插件直接将快照生成到 S3,但必须在每个节点上安装此插件,调整 opensearch.yml(如果使用的是 Elasticsearch 集群,则需要调整 elasticsearch.yml),重新启动每个节点,添加 AWS 凭证,最后拍摄快照。此插件是持续使用或迁移大型集群的绝佳选择。 要将共享文件系统用作快照存储库,请将其添加到
-
先交代下我们的使用场景。我们是把一张分库分表的逻辑表导入了 OpenSearch,建立了相关索引,供后台管理界面查询使用。最近在使用的过程中遇到了几个问题。记之。 查询的数据最多只有 5000 条 我们有一个数据导出功能,当导出的数据超过 5000 条时,导出的表格里就只有 5000 条。我们使用的是 search 接口分页查,看日志发现当 startHit 到 5000 左右就返回失败了。咨询了
-
问题描述:启动janusgraph连接elasticsearch报错 1360 [main] INFO org.janusgraph.diskstorage.Backend - Configuring index [search] 4351 [main] WARN org.janusgraph.diskstorage.es.rest.RestElasticSearchClient - Un
-
这两天使用skywalking,出现了报错,如下: 2020-08-03 14:53:38 2020-08-03 06:53:38,984 - org.apache.skywalking.oap.server.starter.OAPServerBootstrap -10421 [main] ERROR [] - Elasticsearch exception [type=validation_ex
-
警告 WARNING: Unable to locate/open X configuration file. Package xorg-server was not found in the pkg-config search path. Perhaps you should add the directory containing `xorg-server.pc' to the PKG_CO
-
完整报错 OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release. 错误分析 顶上的这段报错理论上不是报错, 就是一个 warning, 提醒你UseConcMarkSweepGC会
-
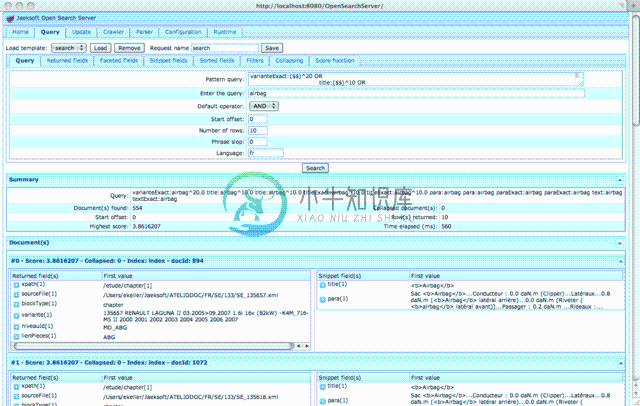
OpenSearchServer是一款基于Lucene的强大企业级搜索引擎软件。使用 Web 用户界面、爬网程序(Web、文件、数据库等)和 JSON Web 服务,您将能够在应用程序中快速轻松地集成高级全文搜索功能。OpenSearchServer在Linux/Unix/BSD/Windows上运行。
-
问题内容: 如何通过属性区分已发布的OSGI服务,这些服务实现了相同的接口? 问题答案: 假设您要基于属性的某些值来检索注册的服务,则需要使用 过滤器 (基于LDAP语法)。 例如: 您想在其中查找实现且属性值等于的服务。 这是获取参考的相关javadoc。 备注1: 上面的示例和javadoc引用了发行版4.2。如果您不限于J2SE 1.4运行时,建议您看一下Release 4.3 语法,您可以
-
服务查询是Dubbo OPS最基本的功能,目前支持服务,应用和IP三个维度的查询,并且服务和应用支持模糊查询和自动提示: 其中详情页展示了服务提供者,消费者等信息,元数据信息需要在Dubbo2.7及之后的版本才会展示:
-
我有一个由5个服务器组成的集群用于elasticsearch,所有服务器都具有相同的elasticsearch版本。 我需要将服务器2、3、4、5的所有数据移动到服务器1。 我怎么做? 以下内容:
-
问题内容: 我正在使用索引器将数据从我的SQL数据库同步到Azure搜索服务。我的SQL视图中有一个字段,其中包含XML数据。列包含字符串列表。集合(Edm.String)中我的Azure搜索服务索引中的对应字段。在检查一些文档时,我发现Indexer不会将Xml(SQL)更改为Collection(Azure Search)。关于如何从Xml数据创建Collection的方法,是否有任何解决方法
-
被面试官鉴定为胡言乱语 昨晚只睡了四个小时,今早又面了别的,中午没睡着,面试评价没有逻辑,讲不到重点 算了,无所谓,反正没hc 拷打项目半小时,不深入 做题,最长连续子数列,做完了要讲 然后问了下,cpp八股 进程线程 智能指针 等等,想不起来了 反问 总共一小时左右
-
我想我错过了一些关于如何在JavaMail中搜索的内容。 从文件夹下载空邮件 创建与结果匹配的新搜索词 使用搜索词筛选(yourFolder.search)结果 这是可行的。但是,为什么要这样做?如果我使用javamail连接到gmail之类的东西,搜索不会在服务器端执行,而且使用整个javax似乎没有任何优势。邮政搜索SearchTerm构建在提高效率或减少需要通过网络发送的数据量方面。。。 我
-
我的要求是,如果用户使用Lucene搜索搜索“页码”,搜索结果应注意将结果中的页码与列表顶部的精确页码匹配。 现在在我的例子中,我尝试使用SortField进行排序- 假设我搜索了术语'5',然后在搜索结果中,而不是在列表的顶部显示精确页码匹配,它显示搜索的术语'5',它存在于每个页面上。 有人能建议如何在列表顶部的Lucene搜索结果中包含页码吗。 我的代码-