
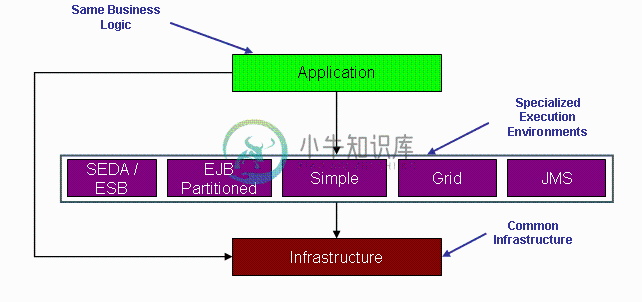
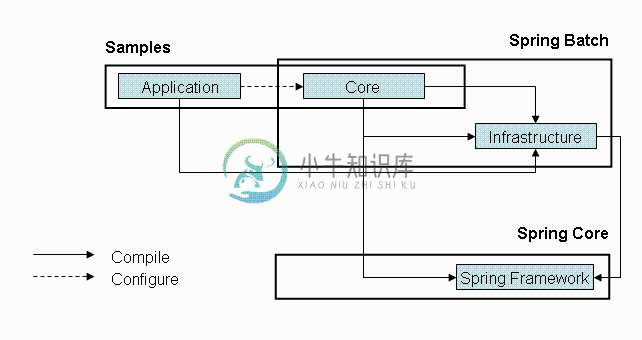
SpringBatch,作为一个 Spring 组件,提供了通过使用 Spring 的 依赖注入(dependency injection) 来处理批处理的条件。下图是 Spring Batch 的体系结构
-
主要内容:面向读者,前提条件,问题反馈Spring Batch是一个轻量级框架,用于在开发企业应用程序中批处理应用程序。 本教程解释了Spring Batch的基本概念,并展示了如何在实际环境中使用它。 面向读者 本教程对于那些需要处理大量涉及诸如事务管理,作业处理统计,资源管理等重复操作的记录的专业人员来说尤其有用。Spring Batch是处理大容量的非常有效的框架 批量作业。 前提条件 Spring Batch建立在Spring
-
我试图使用两个数据源,一个用于Spring批处理的元数据表,另一个是我的应用程序数据库,用于读取/处理/写入。
-
我正在编写spring批处理,它从平面文件中读取数据,很少进行处理,并将摘要写入输出文件。与reader相比,我的处理器和写入程序相对更快。我正在使用FlatFileItemReader,并尝试了从50-1000开始的各种提交间隔。我的批处理作业必须以更快的速度处理1000万条记录。请告诉我如何提高FlatFileItemReader的速度。粘贴到我的配置文件和映射器类下面,读取字段集并将值设置为
-
我想用3个步骤建立一个批次。我想配置这个步骤,就像如果有100条记录,当step1读取、处理和写入一个10块时,step02,然后step03开始和结束,然后再次返回step1,读取下一个块。这在Spring批量可能吗?
-
我正在尝试对作业使用Spring批处理。我有两个作业tempJob和tempJob2在两个单独的配置中。当尝试使用命令行参数(-dspring.batch.job.names=tempJob)运行tempJob时,SpringBatch尝试运行tempJob两次,我得到以下错误 2018-06-15 11:36:37.956信息14436---[main]O.S.B.C.L.Support.Sim
-
我有一个springbatch应用程序,我将连接到一个网络数据库进行阅读。我发现的大多数示例都嵌入了数据库,用于独立测试。我不想那样做。我不确定配置是否类似。以下是我所拥有的最具德国特色的部分(带有一些异议): ,然后从应用程序启动: 我没有配置数据源。我不确定,因为我的基本上只是一个到远程网络数据库的客户端连接,它的配置是否会与我找到的各种示例的嵌入式设置不同。所以我自然会出错(如下)。我只是在
-
用例:步骤1:ItemReader:从数据库中读取1000个ItemProcessor块中的数据:处理这些数据。ItemWriter:将数据写入地图,以便下一步使用 步骤2:ItemReader:读取地图ItemProcessor:处理地图数据并获取新对象。ItemWriter:将新的进程对象持久化到数据库中。 现在我希望Map在整个作业中保持不变,目前我已经为Map创建了一个不同的POJO类,并
-
我们的SpringBatch作业只有一个步骤,包括ItemReader、ItemProcessor和ItemWriter。我们用不同的参数同时运行同一个作业。ItemReader是有状态的,因为它包含从中读取的输入流。 因此,我们不希望ItemReader的相同实例用于每个JobInstance(作业参数)调用。 我不太确定哪种是这种情况的最佳“范围界定”。 1) 该步骤是否应该以@JobScop