
牧羊犬(Sheepdog) 是一个新的第三方的KVM开源项目,提供分布式存储管理功能。牧羊犬提供高可用性的KVM提供块级存储卷类似亚马逊电子交易系统(弹性块存储虚拟 机)的客户机。事实上,对牧羊犬项目待办事项列表中的项目之一是支持亚马逊电子交易系统的API。牧羊犬的目的是扩展到几百个节点。你可以认为这是条带您遇 到类似袭击没有什么多个节点的虚拟磁盘上的数据的技术。该项目仍然非常早期的发展周期,但已提供的基本功能。
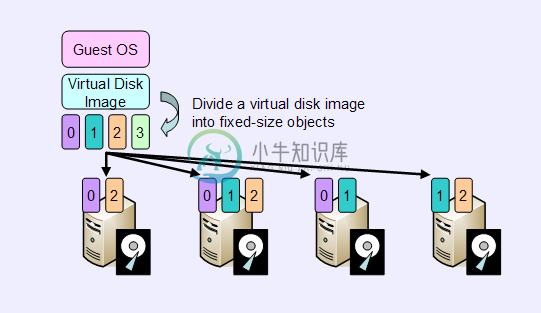
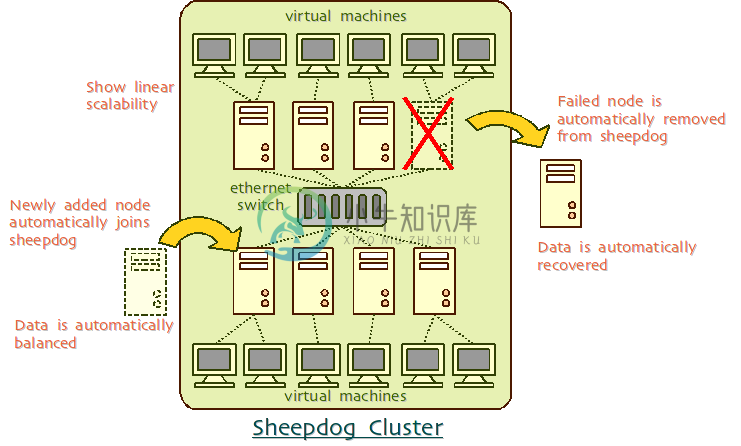
-
1、corosync,single ring最多支持50个节点;zookeeper,500个节点可稳定支撑,1000-1500个节点挑战比较大,需要优化消息传递机制。 2、sheepdog一开始为分布式块存储,如今覆盖多个应用领域,包括IAAS,File Server,冷数据存储等。 3、sheepdog目前满足可用性(iSCSI多路径机制)、持久性(全副本或EC冗余策略)、可扩展性(负载均衡,I
-
首先部署sheepdog集群。然后选择两个不同的计算节点分别进行如下操作 1、tgt安装 获取源码包https://github.com/fujita/tgt (注意需要支持的vdi大小,控制大小的宏#define MAX_DATA_OBJS (UINT64_C(1) << 22)) make && make install 启动tgt:tgtd start,并添加该命令到/etc/rc.d/rc
-
注意事项: 在开始安装sheepdog之前,应该先安装如下内容 yum install -y make automake autoconf gcc nss-devel wget git glib2 yum isntall -y libtool yasm userspace-rcu-devel 再有就是安装2.0以上版本的corosync 1.epel的安装 epel全称Extra Package
-
最近比较忙,做毕设(sheepdog),要在sheepdog的基础上做点东西,也就是说要改sheepdog源码。我只有一个月时间,所以最近一直都在读sheepdog源码。C 语言太菜,里面好多用法都不会,基本都是现边看边查。。。 sheepdog 可以干什么,首先,你需要启动sheep,启动的命令可以用下面这个。当然可以用 test 目录下的测试脚本来启动一个 虚拟的 sheepdog 集群。何谓
-
1、首先在4个存储节点中的3个节点上安装3节点zookeeper,详见 http://blog.csdn.NET/u010855924/article/details/52847308 2、第四个存储节点仅仅需要rpm -ivh zookeeper-3.4.6-redhat6.4.x86_64.rpm即可,不需要配置和启动,原因在于安装sheepdog的时候./configure需要指定sheep
-
前言 sheepdog是一个专门为qemu设计的虚拟机分布式文件系统,采用完全对称的结构,没有元数据服务的中心节点,因此免除了单点故障的隐患.本文基于最新的0.8.2版本测试,介绍sheepdog的安装配置和使用,测试过的,应该是可以使用的,有什么问题,随时联系hj198708706@163.com sheepdog的后端集群管理 sheepdog的后端集群管理用于管理节点间的成员关系和消息通讯.
-
1、sheepdog中http simple storage中nginx后台配置文件模板留存: events { worker_connections 1024; } http { server { listen 80; server_name localhost; location / { fastcgi_pass localhost:8000; fastcgi_param SCRIPT_NAM
-
工作中有用到sheepdog这东西 所以就学习总结一下 一.原理 sheepdog是专门为 kvm-qemu设计的分布式对象存储系统 也就是说 虚拟机镜像放在sheepdog里面 【1】官方网站:https://github.com/sheepdog/sheepdog/wiki 【2】启动sheepdog:https://github.com/sheepdog/sheepdog/wiki/Gett
-
sheepdog是近几年开源社区新兴的分布式块存储文件系统,采用完全对称的结构,没有类似元数据服务的中心节点。这种架构带来了线性可扩展性,没有单点故障和容易管理的特性。对于磁盘和物理节点,SheepDog实现了动态管理容量以及隐藏硬件错误的特性。对于数据管理,SheepDog利用冗余来实现高可用性,并提供自动恢复数据数据,平衡数据存储的特性。除此之外,sheepdog还有具有零配置、高可靠、智能节
-
一、介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成: NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,
-
差不多70MIN 面试官人很帅,而且上来就介绍面试流程,整个面试下来感觉很舒服,写算法题的时候也在和面试官沟通确定一些特殊情况 1.自我介绍 2.集中管理平台是什么#面经# 3.发布是怎样实现的 4.Exporter是怎么采集到数据的 (没答好 确实没了解过) 5.交付相关 6.Prometheus规则是怎样的 具体存储在哪里 7.仪表盘数据是哪里来的 Prometheus支持多少台机器 8.怎么
-
本文向大家介绍Hadoop 分布式存储系统 HDFS的实例详解,包括了Hadoop 分布式存储系统 HDFS的实例详解的使用技巧和注意事项,需要的朋友参考一下 HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统。 一、HDFS的优缺点 1.HDFS优点: a.高容错性 .数据保存多个副本 .数据丢的失后自动恢复
-
在分布式系统中,常困扰我们的还有上线问题。虽然目前有一些优雅重启方案,但实际应用中可能受限于我们系统内部的运行情况而没有办法做到真正的“优雅”。比如我们为了对去下游的流量进行限制,在内存中堆积一些数据,并对堆积设定时间或总量的阈值。在任意阈值达到之后将数据统一发送给下游,以避免频繁的请求超出下游的承载能力而将下游打垮。这种情况下重启要做到优雅就比较难了。 所以我们的目标还是尽量避免采用或者绕过上线
-
FILESYSTEM AND STORAGE DEVICE MANAGEMENT 如果您来自 Windows 环境,那么 Linux 表示和管理存储设备的方式在您看来将非常不同。您已经看到,文件系统没有驱动器的物理表示形式,就像 Windows 中的 C:、D:或 E:系统一样,而是有一个文件树结构,其顶部或根目录是/。本章将介绍 Linux 如何表示存储设备,如硬盘驱动器、闪存驱动器和其他存储设
-
在阅读了T. Otwell关于Laravel中良好设计模式的书后,我在Laravel 4中创建了一个应用程序,我发现自己为应用程序上的每个表创建了存储库。 我最终得到了以下表格结构: 学生:身份证,姓名 我有用于所有这些表的find、create、update和delete方法的存储库类。每个存储库都有一个与数据库交互的雄辩模型。根据Laravel的文档在模型中定义了关系:http://larav
-
一面 11.1 分布式存储 阿里天池比赛,问了一些模块的优化 问存储项目 问TinyKV 项目 操作系统:cpu cache,false sharing,gdb C++:移动语义,std::map,rbtree和b+tree区别。 perf 观察程序性能 算法题:二叉树的路径和 二面 11.2 leader 面 开局先选方向:DB,分布式,操作系统,体系结构,计算机网络。选了分布式,狂问raft