
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。
【主要特点】
-
使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节约不少时间;nodejs使用Google V8作为运行引擎,性能可观;由于nodejs语言本身非阻塞、异步的特性,运行爬虫这类IO密集CPU需求不敏感的系统表现很出色,与其他语言的版本简单的比较,开发量小于C/C++/JAVA,性能高于JAVA的多线程实现以及Python的异步和携程方式的实现。
-
调度中心负责网址的调度,爬虫进程分布式运行,即中央调度器统一决策单个时间片内抓取哪些网址,并协调各爬虫工作,爬虫单点故障不影响整体系统。
-
爬虫在抓取时就对网页进行了结构化解析,摘取到需要的数据字段,入库时不仅是网页源代码还有结构化了的各字段数据,不仅使得网页抓取后数据立马可用,而且便于实现入库时的精准化的内容排重。
-
集成了phantomjs。phantomjs是无需图形界面环境的网页浏览器实现,利用它可以抓取需要js执行才产生内容的网页。通过js语句执行页面上的用户动作,实现表单填充提交后再抓取下一页内容、点击按钮后页面跳转再抓取下一页内容等。
-
重试及容错机制。http请求有各种意外情况,都有重试机制,失败后有详细记录便于人工排查。都返回的页面内容有校验机制,能检测到空白页,不完整页面或者是被代理服务器劫持的页面;
-
可以预设cookie,解决需要登录后才能抓取到内容的问题。
-
限制并发数,避免因为连接数过多被源网站屏蔽IP的问题。
-
集成了代理IP使用的功能,此项功能针对反抓取的网站(限单IP下访问数、流量、智能判断爬虫的),需要提供可用的代理IP,爬虫会自主选择针对源网站还可以访问的代理IP地址来访问,源网站无法屏蔽抓取。
-
产品化功能,爬虫系统的基础部分和具体业务实现部分架构上分离,业务实现部分不需要编码,可以用配置来完成。
-
Web界面的抓取规则设置,热刷新到分布式爬虫。在Web界面配置抓取规则,保存后会自动将新规则刷新给运行在不同机器上的爬虫进程,规则调整不需要编码、不需要重启程序。
可配置项:
1). 用正则表达式来描述,类似的网页归为一类,使用相同的规则。一个爬虫系统(下面几条指的都是某类网址可配置项);
2). 起始地址、抓取方式、存储位置、页面处理方式等;
3). 需要收集的链接规则,用CSS选择符限定爬虫只收集出现在页面中某个位置的链接;
3). 页面摘取规则,可以用CSS选择符、正则表达式来定位每个字段内容要抽取的位置;
4). 预定义要在页面打开后注入执行的js语句;
5). 网页预设的cookie;
6). 评判该类网页返回是否正常的规则,通常是指定一些网页返回正常后页面必然存在的关键词让爬虫检测;
7). 评判数据摘取是否完整的规则,摘取字段中选取几个非常必要的字段作为摘取是否完整的评判标准;
8). 该类网页的调度权重(优先级)、周期(多久后重新抓取更新)。
-
为了减少冗余开发,根据抓取需求划分为实例,每个实例的基础配置(存储数据库、爬虫运行参数、定制化代码)都可以不同,即抓取应用配置的层次为:爬虫系统->实例->网址。
-
爬虫系统结构上参考了scrapy,由core、spider、downloader、extractor、pipeline组成,core是各个组件的联合点和事件控制中心,spider负责队列的进出,downloader负责页面的下载,根据配置规则选择使用普通的html源码下载或者下载后用phantomjs浏览器环境渲染执行js/css,extractor根据摘取规则对文档进行结构化数据摘取,pipeline负责将数据持久化或者输出给后续的数据处理系统。这些组件都提供定制化接口,如果通过配置不能满足需求,可以用js代码很容易个性化扩展某个组件的功能。
【架构】
提示:_建议刚接触本系统的用户跳过架构介绍环节直接进入第二部分,先将系统运行起来,有一个感性认识后再来查阅架构的环节,如果您需要做深入的二次开发,请仔细阅读本环节资料_
整体架构
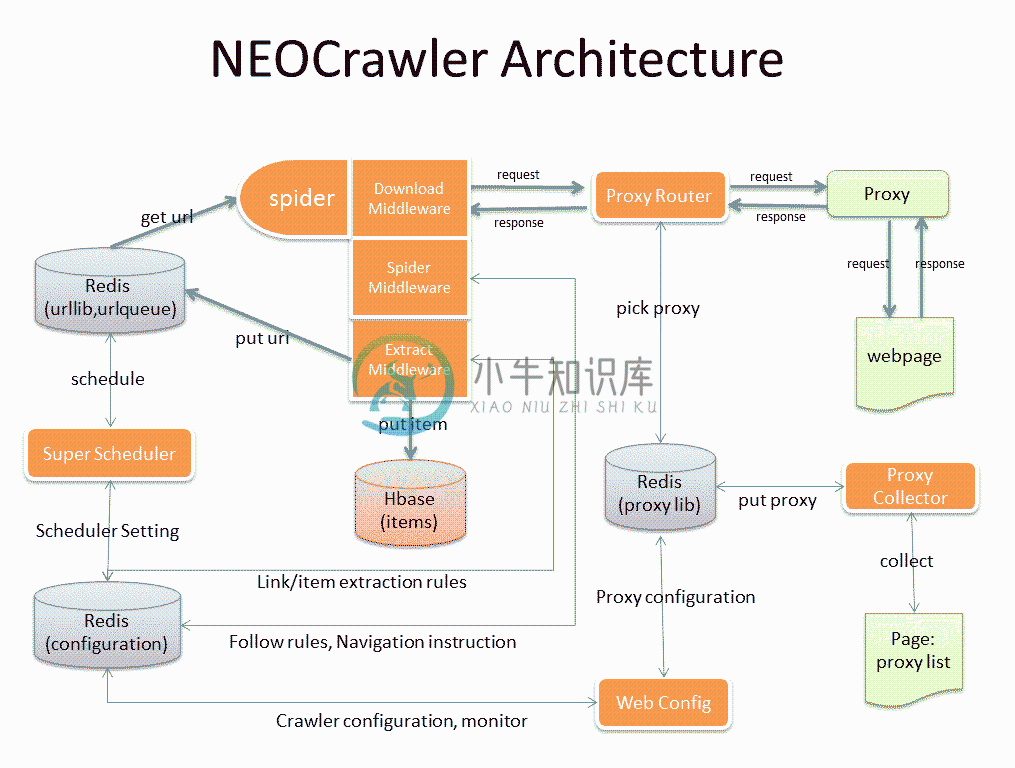
图中黄色部分为爬虫系统的各个子系统。
-
SuperScheduler是中央调度器,Spider爬虫将收集到的网址放入到各类网址所对对应的网址库中,SuperScheduler会依据调度规则从各类网址库抽取相应量的网址放入待抓取队列。
-
Spider是分布式运行的爬虫程序,从调度器调度好的待抓取队列中取出任务进行抓取,将发现的网址放入网址库,摘取的内容存库,将爬虫程序分为core一个核心和download、extract、pipeline 4个中间件,是为了在爬虫实例中能够比较容易的重新定制其中某块功能。
-
ProxyRouter是在使用代理IP的时候将爬虫请求智能路由给可用代理IP的。
-
Webconfig是web的爬虫规则配置后台。
-
来源:http://git.oschina.net/dreamidea/neocrawler 牛抓-neocrawler nodejs 的爬虫系统。 特点: 支持web界面方式的摘取规则配置(css selector & regex); 包含无界面的浏览器引擎(phantomjs),支持js产生内容的抓取; 用http代理路由的方式防止抓取并发量过大的情况下被对方屏蔽; nodejs none-b
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写
-
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种. 通用爬虫 通用网络爬虫 就是 捜索引擎抓取系统,目的是将互联网上的所有的网页下载到本地,形成一个互联网内容的镜像备份。 它决定着整个搜索引擎内容的丰富性和时效性,因此它的性能优劣直接影响着搜索引擎的效果。 通用搜索引擎(Search Engine)工作原理 第一步:抓取网页 搜索引擎网络爬虫的基本工作流程如下: 首先选取一部分的初始UR
-
爬虫项是什么呢?比如采集文章列表、文章详情页,他们都是不同的采集项。 定义示例: 继承Yurun\Crawler\Module\Crawler\Contract\BaseCrawlerItem类。 <?php namespace Yurun\CrawlerApp\Module\YurunBlog\Article; use Imi\Bean\Annotation\Bean; use Yurun\C
-
网络爬虫,即 Web Spider,是一个很形象的名字。目前爬虫开发的语言的主要是 Python,本教程是作者实际开发使用的心得总结,还附加几个小的爬虫案例,帮助读者更好的学习 Python 开发爬虫。 适用人群 适用于爬虫初学者,如果你对高效抓取数据有兴趣,那么本教程将会是你不错的选择。 学习前提 学习本教程前,你需要对 Python 语言有一定的了解。 版本信息 书中演示代码基于以下版本: 语
-
拼多多爬虫工程师面试题 电话面: http协议、tcp协议(几次握手) top命令 Linux/Mac 下虚拟内存(Swap) 线程、进程、协程 Async 相关、事件驱动相关 阻塞、非阻塞 Python GIL 布隆过滤器原理:如何实现、一般要几次哈希函数 给我留下了一个作业:抓取天猫超市上某些商品的可以配送省份信息。(当时做这个也花了很久,主要是需要解决PC端的登陆问题,后来通过h5接口) 现