
CockroachDB (蟑螂数据库)是一个可伸缩的、支持地理位置处理、支持事务处理的数据存储系统。
CockroachDB 提供两种不同的的事务特性,包括快照隔离(snapshot isolation,简称SI)和顺序的快照隔离(SSI)语义,后者是默认的隔离级别。
蟑螂是一个分布式的K/V数据仓库,支持ACID事务,多版本值存储是其首要特性。主要的设计目标是全球一致性和可靠性,从蟑螂的命名上是就能看出这点。蟑螂数据库能处理磁盘、物理机器、机架甚至数据中心失效情况下最小延迟的服务中断;整个失效过程无需人工干预。蟑螂的节点是均衡的,其设计目标是同质部署(只有一个二进制包)且最小配置。
蟑螂数据库实现了单一的、巨大的有序映射,键和值都是字节串形式(不是unicode),支持线性扩展,理论上支持4EB的逻辑数据)。映射有一个或者多个Range组成,每一个Range对应一个把数据存储在RocksDB(LevelDB的一个变种,Facebook贡献)上的K/V数据库,并且复制到三个或者更多蟑螂服务器上,Range定义为有开始和结束键值的区间。Range可以合并及分裂来维持总大小在一个全局配置的最大最小范围之间。Range的大小默认是64M,目的是便于快速分裂和合并,在一个热点键值区间快速分配负载。Range的复制确定为分离的数据中心来达到可靠性(比如如下分组:{ US-East, US-West, Japan }, { Ireland, US-East, US-West}, { Ireland, US-East, US-West, Japan, Australia })
Range有一种变化,通过分布式一致性算法实例来调节确保一致性,蟑螂所选择使用Raft一致性算法。所有的一致性状态存在于RocksDB中。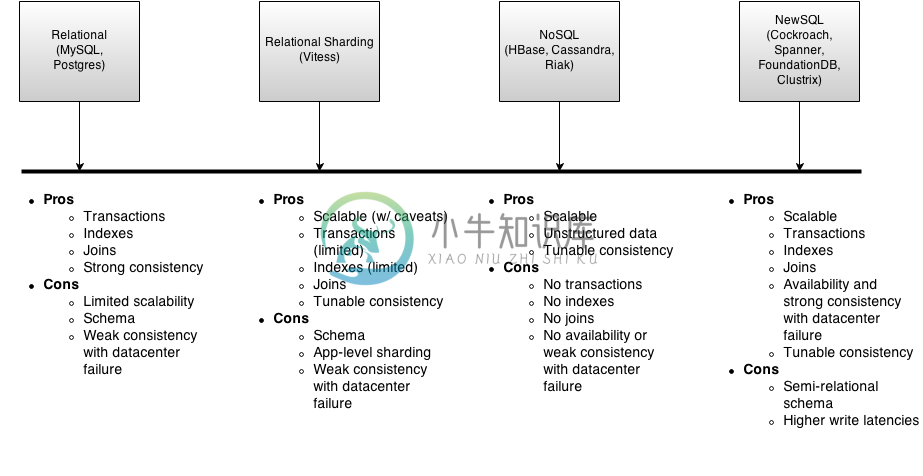
-
功能和特性对比 功能 TiDB CockroachDB 水平扩容/缩容 Y Y 在线扩容 Y 待查 列存储引擎 Y,TiFlash N 行存储引擎 Y,TiKV Y 热点调度 Y 待查 数据重分布 Y 待查 Web UI Y,TiDB DashBoard Admin UI 运维工具 Y,TiUP 待查 分布式事务 Y, read committed/repeatable read Y, seria
-
这段时间老师需要我测试CRDB的性能,因而对CRDB做了些简单的了解,可以进行简单使用及测试编译,首先说明我使用的是阿里云服务器Ubuntu20.04,各位可以根据需要自行选择操作系统,centos和ubuntu,CRDB都支持,下面是我在配置三节点跨域集群过程中记录的执行语句 官方给了个同步时钟的过程,而我的服务器全部由阿里云提供,时钟没啥影响 安装CRDB 下面的版本可以根据需要自行更改 cu
-
CRDB使用CREATE INDEX创建索引,索引用来帮助SQL查询数据而不用进行全表扫描,从而提高性能。表的字段如果被定义为PRIMARY KEY或UNIQUE,会自动创建索引。如果想在JSONB或ARRAY上面创建索引,可以创建GIN索引。 CRDB的索引包括以下几类: 单列索引 多列索引 唯一索引 倒排索引(GIN索引) 空间索引(GIST索引) 覆盖索引 HASH分片索引 部分索引 表达式
-
本文知识点来源于官网地址https://www.cockroachlabs.com/docs/v22.1/architecture/sql-layer.html CRDB的SQL层向开发人员公开SQL API,将高级SQL语句转换为底层键值存储的低级读写请求,并传递给事务层。 它由以下子层组成: SQL API,提供用户访问接口。 解析器,它将SQL文本转换为抽象语法树(AST)。 基于成本的优化
-
本文知识点来源于官网地址https://www.cockroachlabs.com/docs/v22.1/architecture/replication-layer.html 总览 CRDB体系结构的复制层在节点之间复制数据,并通过我们的共识算法确保这些副本之间的一致性。 高可用性要求数据库能够容忍节点离线,而不会中断对应用程序的服务。通过在节点之间复制数据可以确保数据一直可以被访问。 节点离线
-
数据库是世界上每个企业的心脏,支撑着小至几个简单的表格,大到成千上万台服务器。 并且他们进化的速度非常快。 在蟑螂实验室(Cockroach Labs)的大多数工程师在他们的职业生涯中都一直在维护并观察这些数据库的运行状态,当他们发现数据库出现这样或那样的瓶颈的时候,他们便会着力解决这些出现的瓶颈问题。 但是首先,为什么要选择“COckroach”? 虽然他的外表长的很荒诞,但是请相信他有一个强韧
-
CockroachDB被设计用于创建开发者想用的源码可用的数据:集扩展性与一致性一体的数据库。开发者经常问到我们是如何实现的,该指南详细说明了CockroachDB进程的内部工作原理。 然而,使用CockroachDB您肯定不需要理解底层架构。这些内容为认真的用户和数据库爱好者提供了一个高级框架来解释底层发生了什么。 一.指南使用 该指南分为多部分来详细说明CockroachDB的每一层。推荐按顺
-
本文知识点来源于官网地址https://www.cockroachlabs.com/docs/stable/hash-sharded-indexes.html 如果您正在处理一个必须按顺序键建立索引的表,则应该使用哈希分片索引。哈希分片索引将顺序流量均匀分布在不同的范围内,消除了单一范围的热点,并以较小的读性能代价提高了顺序键索引上的写性能。 概览 CRDB根据范围的大小和到范围的负载流自动分割键
-
本文知识点来源于官网地址https://www.cockroachlabs.com/docs/v22.1/architecture/transaction-layer.html 概览 一致性是数据库最重要的特性。为了提供一致性,CRDB在事务层实现了对ACID事务语义的完全支持。所有语句都是作为事务处理的,包括单个语句——“自动提交模式”。 CRDB支持跨集群的事务(包括跨range和跨表事务),
-
CockroachDB架构的分布层提供了集群数据的统一视图。 --注意: 1)如果您还没有准备好,我们建议先阅读架构概览部分。 一.概览 为了从任何节点访问集群中的所有数据,CockroachDB按照整体排序映射来存储键值对。该键空间描述集群中数据的所有信息及其位置,并将其分为我们称为的"范围",其为连续的键空间块,以便每个键值总是能在单个范围内找到。 CockroachDB实施排序映射以开启:
-
前言 公司最近从 Mysql 切换到了 CockroachDB ,所以在这里记录下期间遇到的一些问题 1 开发环境 CockroachDB版本 V20.2.3 maven需要引入依赖 <dependency> <groupId>org.postgresql</groupId> <artifactId>postgresql</artifactId> <version>42.2
-
部署和启动 部署 官网下来的cockroach-v1.0.4.linux-amd64.tgz 解压开后就一个bin文件,拷贝到系统目录即可 cp -i cockroach-v1.0.4.linux-amd64/cockroach /usr/local/bin/ 启动 --host=192.168.143.40也可以指定为--host=localhost [root@40 /]# cockroach
-
CockroachDB架构的存储层对磁盘数据进行读写。 --注意: 1)如果您还没准备好,我们推荐您阅读架构概览。 一.概览 每个CockroachDB节点包含至少一个store,其在节点启动时指定,其是CockroachDB进程在磁盘上读写数据的地方。 数据通过RocksDB以键值对存储于磁盘,RocksDB主要以黑盒API被处理,每个store包含两个RocksDB实例: 1)一个用于存储临时
-
问题内容: 我想将分层的二维科学数据集存储在关系数据库(MySQL或SQLite)中。每个数据集都包含一个数值数据表,其中包含任意数量的列。另外,每个数据集可以具有一个或多个与其表的给定行关联的相同类型的子级。每个数据集通常具有1至100列和1至1.000.000行。数据库应该能够处理许多数据集(> 1000),并且数据的读/写应该相当快。 存储此类数据的最佳数据库模式将是什么?是否有一个“主”表
-
数据存储 Cookie 浏览器中的 Cookie 是指小型文本文件,通常在 4KB 大小左右。(由键值对构成用 ; 隔开)大部分时候是在服务器端对 Cookie 进行设置,在头文件中 Set-Cookie 来对 Cookie 进行设置。 页面可以访问当前页的 Cookie 也可以访问父域的 Cookie。 属性 属性 默认值 作用 Name(必填) 名 Value(必填) 值 Domain 当前文
-
前端数据存储工具 YDN-DB forerunner AlaSQL LokiJS lovefiled Dexie.js localForage pouchdb
-
我在谷歌上搜索过,找不到任何可以在O(1)时间内存储和读取双向数据的DS。例如书籍和作家。有了书的名字,就必须找到作者。有了作者的名字,就必须找到书。 在数据库中,这些关系(如联接表)是如何存储的? 提前谢谢。
-
一个程序免不了要储存数据,对于Chrome扩展也是这样。通常Chrome扩展使用以下三种方法中的一种来储存数据:第一种是使用HTML5的localStorage,这种方法在上一节的内容中已经涉及;第二种是使用Chrome提供的存储API;第三种是使用Web SQL Database。 对于一般的扩展,“设置”这种简单的数据可以优先选择第一种,因为这种方法使用简单,可以看成是特殊的JavaScrip
-
当我扩展CrudRepository接口时,我的子接口中有方法。我可以写 签入我的服务层。