
ABTestingGateway 是一个可以动态设置分流策略的灰度发布系统,工作在7层,基于nginx和ngx-lua 开发,使用 redis 作为分流策略数据库,可以实现动态调度功能。
ABTestingGateway 是在 @平凡的香草 指导下完成,作者是:@bg2bkk 和 @helloyi 。
nginx 是目前使用较多的7层服务器,可以实现高性能的转发和响应;ABTestingGateway 是在 nginx 转发的框架内,在转向 upstream 前,根据 用户请求特征 和 系统的分流策略 ,查找出目标upstream,进而实现分流。
在以往的基于 nginx 实现的灰度系统中,分流逻辑往往通过 rewrite 阶段的 if 和 rewrite 指令等实现,优点是性能较高,缺点是功能受限、容易出错,以及转发规则固定,只能静态分流。针对这些缺点,我们设计实现了ABTesingGateway,采用 ngx-lua 实现系统功能,通过启用lua-shared-dict和lua-resty-lock作为系统缓存和缓存锁,系统获得了较为接近原生nginx转发的性能。
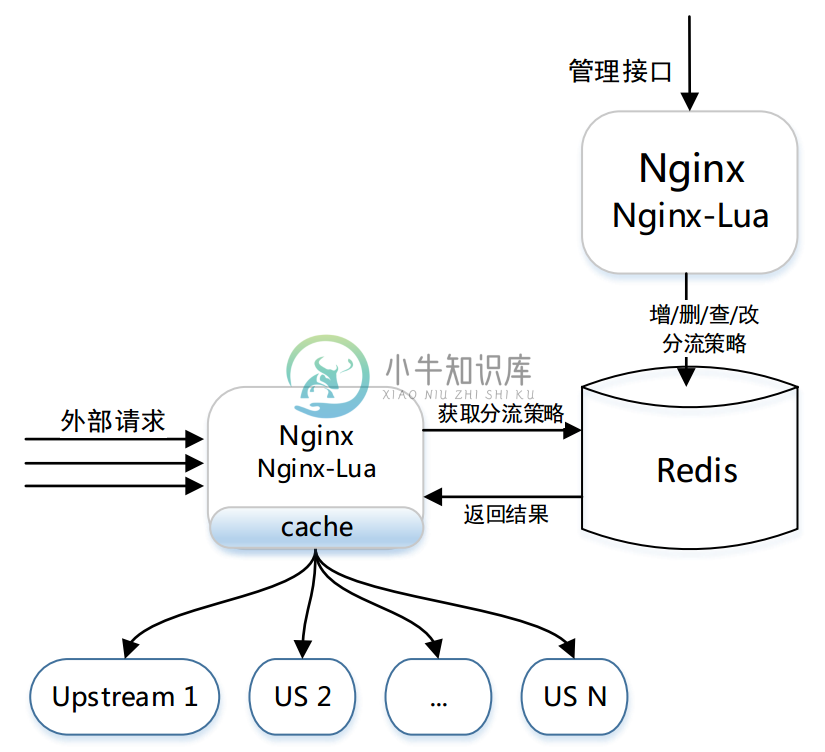
ABTesingGateway 的架构简图
Features:
-
支持多种分流方式,目前包括iprange、uidrange、uid尾数和指定uid分流
-
动态设置分流策略,即时生效,无需重启
-
可扩展性,提供了开发框架,开发者可以灵活添加新的分流方式,实现二次开发
-
高性能,压测数据接近原生nginx转发
-
灰度系统配置写在nginx配置文件中,方便管理员配置
-
适用于多种场景:灰度发布、AB测试和负载均衡等
系统实现
分流功能:
转发分流是灰度系统的主要功能,目前 ABTesingGateway 支持ip段分流(iprange)、uid用户段分流(uidrange)、uid尾数分流(uidsuffix)和指定特殊uid分流(uidappoint)四种方式。
ABTesingGateway 依据系统中配置的运行时信息runtimeInfo进行分流工作;通过将 runtimeInfo 设置为不同的分流策略,实现运行时分流策略的动态更新,达到动态调度的目的。
-
系统运行时信息设置
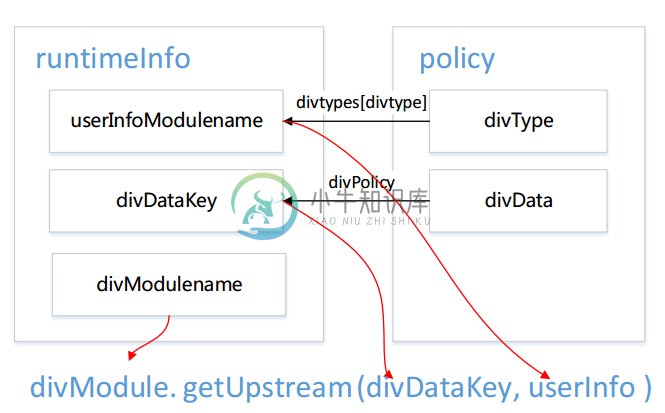
如图所示
-
系统管理员通过系统管理接口将分流策略policy设置为运行时策略,并指定该策略对应的分流模块名divModulename和用户信息提取模块名userInfoModulename后,系统可以进行分流工作。
-
系统对用户请求进行分流时,首先获得系统运行时信息runtimeInfo中的信息,然后提取用户特征userInfo,最后分流模块divModule根据分流策略dviDataKey和用户特征userInfo查找出应该转发到的upstream。如果没有对应的upstream,则将该请求转向默认upstream。
-
-
以iprange分流为例
以某个iprange分流策略为例: { "divtype":"iprange", "divdata":[ {"range":{"start":1111, "end":2222}, "upstream":"beta1"}, {"range":{"start":3333, "end":4444}, "upstream":"beta2"}, {"range":{"start":7777, "end":8888}, "upstream":"beta3"} ] }其中divdata中的每个 range:upstream 对中,range 为 ip 段,upstream 为 ip 段对应的后端;range 中的 start 和 end 分别为 ip 段的起始和终止, ip以整型表示。 当灰度系统启用iprange分流方式时,会根据用户请求的ip进行分流转发。 假如用户请求中的ip信息转为整型后是4000,将被转发至beta2 upstream。
-
分流过程流程图
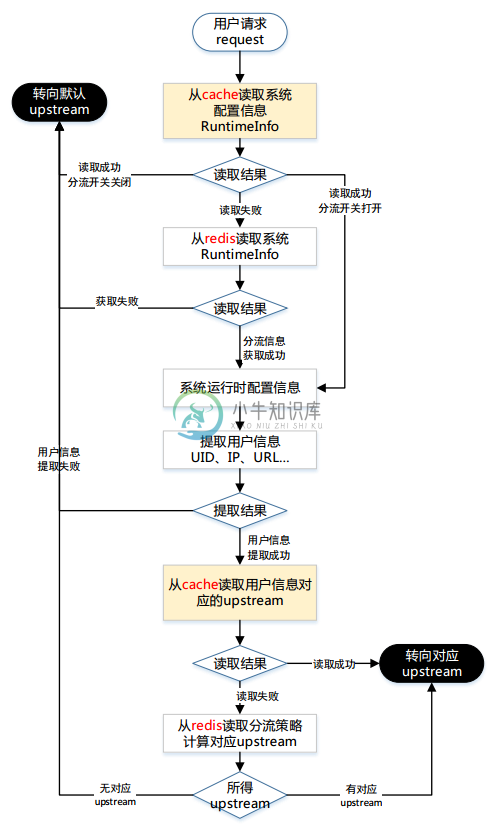
分流过程流程图
管理功能:
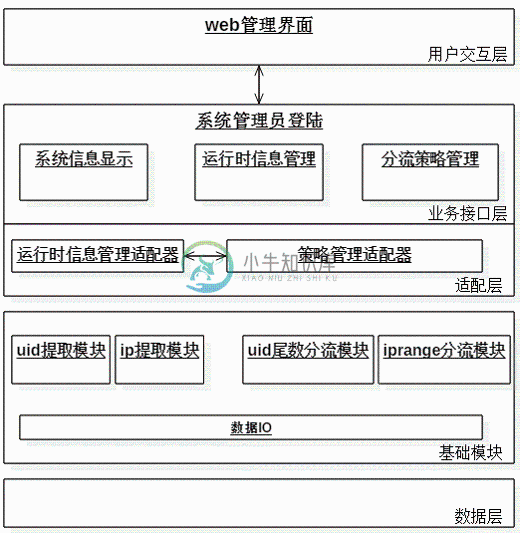
管理功能架构图
1. 管理员登入后,得到系统信息视图,运行时信息视图,可以进行策略管理和运行时信息管理 2. 业务接口层向管理员提供 增/删/查/改 接口 3. 适配层将承担业务接口与分流模块的沟通工作 4. 适配层提出统一接口,开发人员可以通过实现接口来添加新的分流方式
管理接口:
[策略管理接口] #分流策略检查,参数为一个分流策略数据的json串 1. /admin/policy/check #分流策略添加,参数与check接口一致 2. /admin/policy/set #分流策略读取,参数为要读取策略的policyid 3. /admin/policy/get #分流策略删除,参数为要删除策略的policyid 4. /admin/policy/del [运行时信息管理接口] #设置分流策略为运行时策略,参数为policyid 1. /admin/runtime/set #获取系统当前运行时信息,无参数 2. /admin/runtime/get #删除系统运行时信息,关闭分流接口,无参数 3. /admin/runtime/del
快速部署
软件依赖
-
tengine-2.1.0
-
LuaJIT-2.1-20141128
-
ngx_lua-0.9.13
-
lua-cjson-2.1.0.2
-
redis-2.8.19
系统部署
repo中的utils/conf文件夹中有灰度系统部署所需的最小示例
1. git clone https://github.com/SinaMSRE/ABTestingGateway 2. cd /path/to/ABTestingGateway/utils #启动redis数据库 3. redis-server conf/redis.conf #启动upstream server,其中stable为默认upstream 4. /usr/local/nginx/sbin/nginx -p `pwd` -c conf/stable.conf 5. /usr/local/nginx/sbin/nginx -p `pwd` -c conf/beta1.conf 6. /usr/local/nginx/sbin/nginx -p `pwd` -c conf/beta2.conf 7. /usr/local/nginx/sbin/nginx -p `pwd` -c conf/beta3.conf 8. /usr/local/nginx/sbin/nginx -p `pwd` -c conf/beta4.conf #启动灰度系统,proxy server,灰度系统的配置也写在conf/nginx.conf中 9. /usr/local/nginx/sbin/nginx -p `pwd` -c conf/nginx.conf
灰度系统使用demo
-
管理功能
1. 部署并启动系统 2. 查询系统运行时信息,得到null 0> curl 127.0.0.1:8030/admin/runtime/get {"errcode":200,"errinfo":"success ","data":{"divModulename":null,"divDataKey":null,"userInfoModulename":null}} 3. 查询id为9的策略,得到null 0> curl 127.0.0.1:8030/admin/policy/get?policyid=9 {"errcode":200,"errinfo":"success ","data":{"divdata":null,"divtype":null}} 4. 向系统添加策略,返回成功,并返回新添加策略的policyid 以uidsuffix尾数分流方式为例,示例分流策略为: { "divtype":"uidsuffix", "divdata":[ {"suffix":"1", "upstream":"beta1"}, {"suffix":"3", "upstream":"beta2"}, {"suffix":"5", "upstream":"beta1"}, {"suffix":"0", "upstream":"beta3"} ] } 添加分流策略接口 /admin/policy/set 接受json化的policy数据 0> curl 127.0.0.1:8030/admin/policy/set -d '{"divtype":"uidsuffix","divdata":[{"suffix":"1","upstream":"beta1"},{"suffix":"3","upstream":"beta2"},{"suffix":"5","upstream":"beta1"},{"suffix":"0","upstream":"beta3"}]}' {"errcode":200,"errinfo":"success the id of new policy is 0"} 5. 查看添加结果 0> curl 127.0.0.1:8030/admin/policy/get?policyid=0 {"errcode":200,"errinfo":"success ","data":{"divdata":["1","beta1","3","beta2","5","beta1","0","beta3"],"divtype":"uidsuffix"}} 6. 设置系统运行时策略为 0号策略 0> curl 127.0.0.1:8030/admin/runtime/set?policyid=0 {"errcode":200,"errinfo":"success "} 7. 查看系统运行时信息,得到结果 0> curl 127.0.0.1:8030/admin/runtime/get {"errcode":200,"errinfo":"success ","data":{"divModulename":"abtesting.diversion.uidsuffix","divDataKey":"ab:test:policies:0:divdata","userInfoModulename":"abtesting.userinfo.uidParser"}} 8. 当访问接口不正确返回时,将返回相应的 错误码 和 错误描述信息 0> curl 127.0.0.1:8030/admin/policy/get?policyid=abc {"errcode":50104,"errinfo":"parameter type error for policyID should be a positive Integer"} -
分流功能
在验证管理功能通过,并设置系统运行时策略后,开始验证分流功能 1. 分流,不带用户uid,转发至默认upstream 0> curl 127.0.0.1:8030/ this is stable server 2. 分流,带uid为30,根据策略,转发至beta3 0> curl 127.0.0.1:8030/ -H 'X-Uid:30' this is beta3 server 3. 分流,带uid为33,根据策略,转发至beta2 0> curl 127.0.0.1:8030/ -H 'X-Uid:33' this is beta2 server
压测结果:
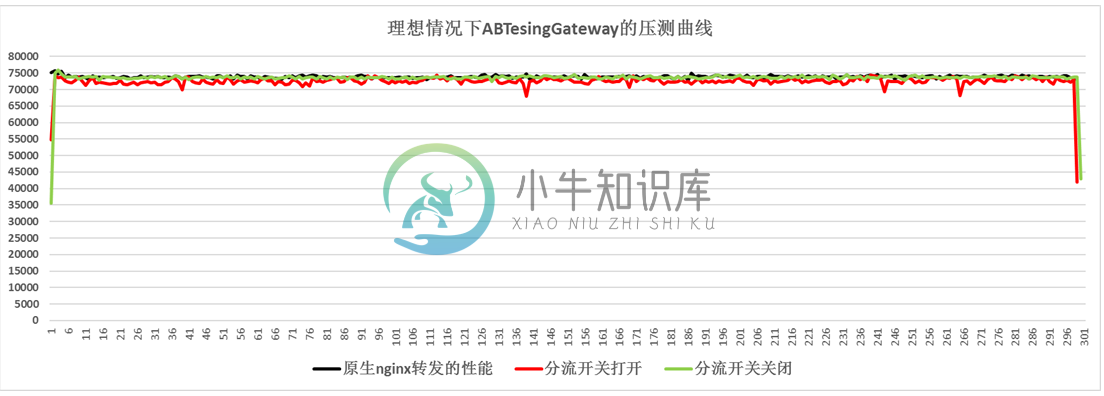
压测环境下灰度系统与原生nginx转发的对比图
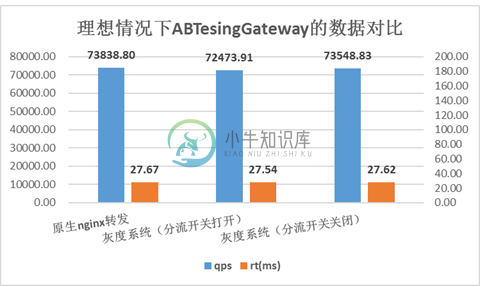
压测环境下灰度系统与原生nginx转发的数据对比
如图所示,用户请求完全命中cache是理想中的情况,灰度系统在理想情况下可以达到十分接近原生nginx转发的性能。
产生图中压测结果的场景是:用户请求经过proxy server转向upstream server,访问1KB大小的静态文件。
proxy server的硬件配置:
-
CPU:E5620 2.4GHz 16核
-
Mem:24GB
-
Nic:千兆网卡,多队列
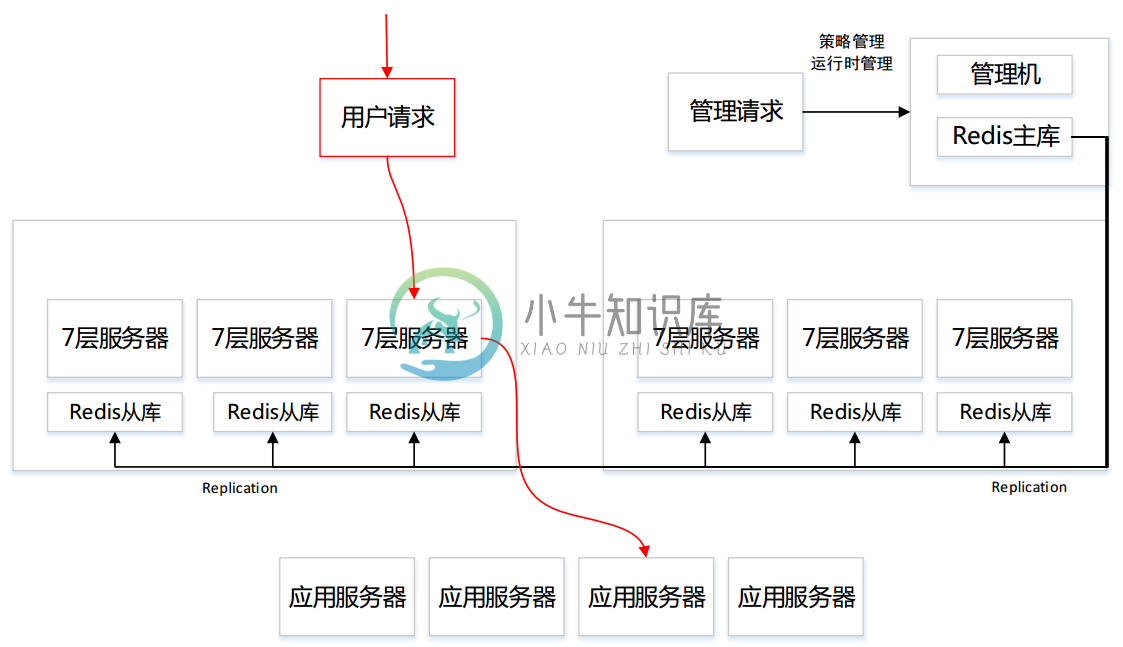
线上部署简图:
-
目录结构分布 我们从GitHub上把它下载后解压出来,有以下5个目录,分别是: admin 管理模块,对策略增删改查等功能 diversion 主模块吧,看源码是匹配redis存储的key doc 文档 lib 各个操作的子模块 utils 专门存放nginx相关文件的 我这次更改的需求是 添加一个分流策略 从哪里开始入手 我们了解每个目录是干啥的后,我们开始从lib这个模块开始入手 我们切换到l
-
依赖软件版本 tengine-2.3.2 lua-5.1.5-coco (openresty-1.13.6.2中集成的版本,在lua-5.1.5的基础上打了补丁 LuaCoco-1.1.9) LuaCoco-1.1.9 redis-5.0.8 lua-cjson-2.1.0.6 (openresty-1.13.6.2中集成的版本,bundle下面) LuaJIT-2.1-20180420 (ope
-
2015 年度新增开源软件排名 TOP 100 - 开源中国社区 http://www.oschina.net/news/69808/2015-annual-ranking-top-100-new-open-source-software
-
管理接口访问报错 系统版本 内核版本 Ubuntu 14.04.2 3.13.0-32-generic 我们在这里通过curl来插入命令的时候直接报错: curl命令写入规则 curl 'http://127.0.0.1:8080/ab_admin?token=zuesx&action=policy_set' -d '{"divtype":"30102","divdata":[{"30102_se
-
2020博客地址汇总 2019年博客汇总 abtestinggateway 中 iprange 中涉及IP和整型间相互转换。用java转换如下 package com.loit.common; import java.math.BigInteger; public class IPToLong { /** * 将字符串类型的IP转换为整型: * 1.IP中每个"
-
http://www.cnblogs.com/beautiful-code/p/6278779.html
-
接下来我们要实现演示应用最难的功能:微博动态流。基本上本节的内容算是全书最高深的。完整的动态流以 11.3.3 节的动态流原型为基础实现,动态流中除了当前用户自己的微博之外,还包含他关注的用户发布的微博。我们会采用循序渐进的方式实现动态了。在实现的过程中,会用到一些相当高级的 Rails、Ruby 和 SQL 技术。 因为我们要做的事情很多,在此之前最好先清楚我们要实现的是什么样的功能。图 12.
-
Linux 系统的启动,从计算机开机通电自检开始,一直到登陆系统,需要经历多个过程。学习 Linux 的启动过程,有助于了解 Linux 系统的结构,也对系统的排错有很大的帮助。 CentOS 6.x 系统启动过程发生了较大的变化,使用 Upstart 启动服务取代了原先的 System V init 启动服务。Upstart 启动服务的效率更高,启动速度更快。 Linux 系统启动过程比较复杂,
-
我正在使用dataflow处理存储在GCS中的文件,并写入Bigquery表。以下是我的要求: 输入文件包含events记录,每个记录属于一个EventType; 需要按EventType对记录进行分区; 对于每个eventType输出/写入记录到相应的Bigquery表,每个eventType一个表。 每个批处理输入文件中的事件各不相同; 我正在考虑应用诸如“GroupByKey”和“Parti
-
主要内容:动态分区比固定分区的优势,动态分区的缺点,复杂的内存分配动态分区试图克服由固定分区造成的问题。 在这种技术中,分区大小最初并未声明。 它在进程加载时声明。 第一个分区是为操作系统保留的。 剩余空间分成几部分。 每个分区的大小将等于进程的大小。 分区大小根据进程的需要而变化,以避免内部碎片。 动态分区比固定分区的优势 1. 没有内部碎片 考虑到动态分区中的分区是根据进程的需要创建的,很明显,不会有任何内部碎片,因为分区中不会有任何未使用的剩余空间。 2.
-
我一直在玩动态LINQ,我想知道Java是否有可能做类似的事情。例如,如果我使用这个工作代码: 有没有一种方法可以让它像使用动态LINQ一样动态
-
我需要从配置文件动态创建kafka流,其中包含每个流的源主题名称和配置。应用程序需要有几十个Kafka流和流将是不同的每个环境(例如阶段,prod)。它可能做到这一点与库? 我们可以通过轻松做到这一点: 我们需要实现spring接口,这样所有流都将自动启动和关闭。 是否可以使用做同样的事情?正如我所看到的,我们需要在代码中创建每个Kafka流,我看不到如何使用创建Kafka流列表的可能性。 但是如