
Tortoise ORM


Introduction
Tortoise ORM is an easy-to-use asyncio ORM (Object Relational Mapper) inspired by Django.
Tortoise ORM was built with relations in mind and admiration for the excellent and popular Django ORM.It's engraved in its design that you are working not with just tables, you work with relational data.
You can find the docs at Documentation
Note
Tortoise ORM is a young project and breaking changes are to be expected.We keep a Changelog and it will have possible breakage clearly documented.
Tortoise ORM is supported on CPython >= 3.7 for SQLite, MySQL and PostgreSQL.
Why was Tortoise ORM built?
Python has many existing and mature ORMs, unfortunately they are designed with an opposing paradigm of how I/O gets processed.asyncio is relatively new technology that has a very different concurrency model, and the largest change is regarding how I/O is handled.
However, Tortoise ORM is not the first attempt of building an asyncio ORM. While there are many cases of developers attempting to map synchronous Python ORMs to the async world, initial attempts did not have a clean API.
Hence we started Tortoise ORM.
Tortoise ORM is designed to be functional, yet familiar, to ease the migration of developers wishing to switch to asyncio.
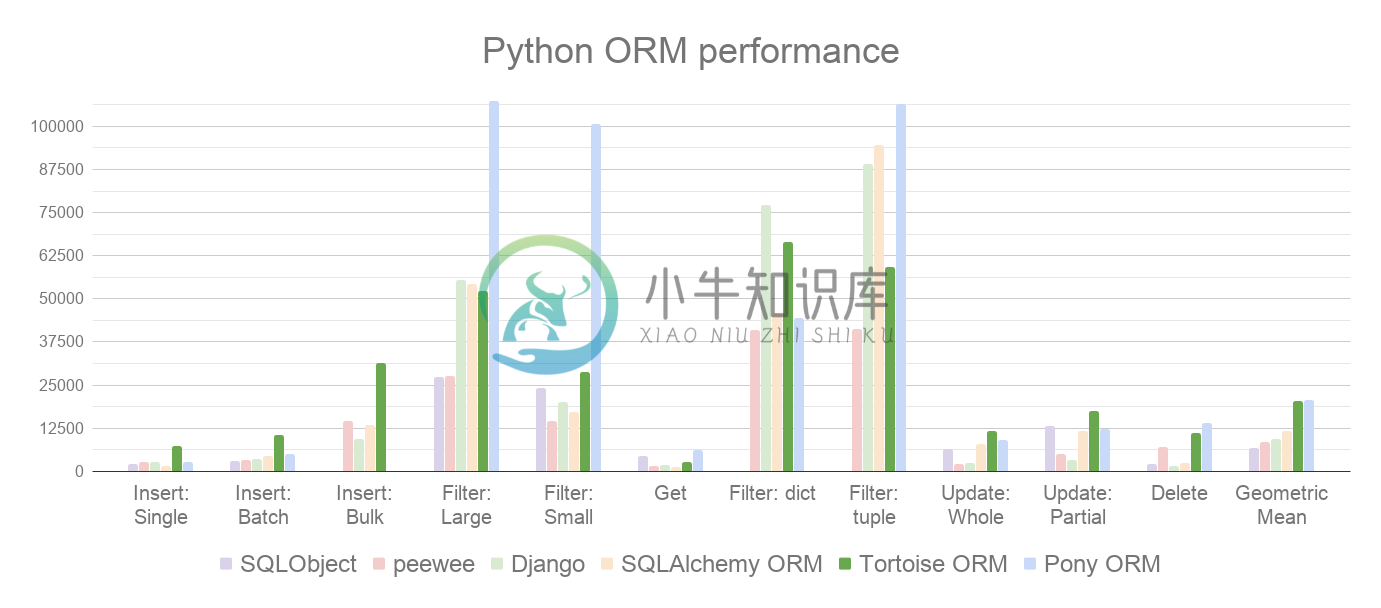
It also performs well when compared to other Python ORMs. In our benchmarks, where we measure different read and write operations (rows/sec, more is better), it's trading places with Pony ORM:
How is an ORM useful?
When you build an application or service that uses a relational database, there is a point where you can't get away with just using parameterized queries or even query builder. You just keep repeating yourself, writing slightly different code for each entity.Code has no idea about relations between data, so you end up concatenating your data almost manually.It is also easy to make mistakes in how you access your database, which can be exploited by SQL-injection attacks.Your data rules are also distributed, increasing the complexity of managing your data, and even worse, could lead to those rules being applied inconsistently.
An ORM (Object Relational Mapper) is designed to address these issues, by centralising your data model and data rules, ensuring that your data is managed safely (providing immunity to SQL-injection) and keeping track of relationships so you don't have to.
Getting Started
Installation
First you have to install Tortoise ORM like this:
pip install tortoise-orm
You can also install with your db driver (aiosqlite is builtin):
pip install tortoise-orm[asyncpg]
Or for MySQL:
pip install tortoise-orm[aiomysql]
Or another asyncio MySQL driver asyncmy:
pip install tortoise-orm[asyncmy]
Quick Tutorial
The primary entity of tortoise is tortoise.models.Model.You can start writing models like this:
from tortoise.models import Model
from tortoise import fields
class Tournament(Model):
id = fields.IntField(pk=True)
name = fields.TextField()
def __str__(self):
return self.name
class Event(Model):
id = fields.IntField(pk=True)
name = fields.TextField()
tournament = fields.ForeignKeyField('models.Tournament', related_name='events')
participants = fields.ManyToManyField('models.Team', related_name='events', through='event_team')
def __str__(self):
return self.name
class Team(Model):
id = fields.IntField(pk=True)
name = fields.TextField()
def __str__(self):
return self.name
After you defined all your models, tortoise needs you to init them, in order to create backward relations between models and match your db client with the appropriate models.
You can do it like this:
from tortoise import Tortoise
async def init():
# Here we connect to a SQLite DB file.
# also specify the app name of "models"
# which contain models from "app.models"
await Tortoise.init(
db_url='sqlite://db.sqlite3',
modules={'models': ['app.models']}
)
# Generate the schema
await Tortoise.generate_schemas()
Here we create a connection to an SQLite database in the local directory called db.sqlite3. Then we discover and initialise the models.
Tortoise ORM currently supports the following databases:
- SQLite (requires
aiosqlite) - PostgreSQL (requires
asyncpg) - MySQL (requires
aiomysql)
generate_schema generates the schema on an empty database. Tortoise generates schemas in safe mode by default whichincludes the IF NOT EXISTS clause, so you may include it in your main code.
After that you can start using your models:
# Create instance by save
tournament = Tournament(name='New Tournament')
await tournament.save()
# Or by .create()
await Event.create(name='Without participants', tournament=tournament)
event = await Event.create(name='Test', tournament=tournament)
participants = []
for i in range(2):
team = await Team.create(name='Team {}'.format(i + 1))
participants.append(team)
# M2M Relationship management is quite straightforward
# (also look for methods .remove(...) and .clear())
await event.participants.add(*participants)
# You can query a related entity with async for
async for team in event.participants:
pass
# After making a related query you can iterate with regular for,
# which can be extremely convenient when using it with other packages,
# for example some kind of serializers with nested support
for team in event.participants:
pass
# Or you can make a preemptive call to fetch related objects
selected_events = await Event.filter(
participants=participants[0].id
).prefetch_related('participants', 'tournament')
# Tortoise supports variable depth of prefetching related entities
# This will fetch all events for Team and in those events tournaments will be prefetched
await Team.all().prefetch_related('events__tournament')
# You can filter and order by related models too
await Tournament.filter(
events__name__in=['Test', 'Prod']
).order_by('-events__participants__name').distinct()
Migration
Tortoise ORM uses Aerich as its database migration tool, see more detail at its docs.
Contributing
Please have a look at the Contribution Guide.
License
This project is licensed under the Apache License - see the LICENSE.txt file for details.
-
用python测试了一下通过接口和model写数据到数据库,发现时区是UTC时区,也就是北京时间减8小时的时间值,经过查找发现有两种解决方法,一个是配置里加上"timezone": "Asia/Shanghai",看官网:https://tortoise.github.io/setup.html?h=timezone#tortoise.Tortoise.init-parameters。另一个是定义
-
#models.py from tortoise.models import Model from tortoise import fields class User(Model): id = fields.IntField(pk=True, , source_field="userID") name = fields.CharField(max_length = 100) date_field
-
Tortoise-ORM提供了bulk_create()方法,可以用于在单个数据库查询中批量插入多条数据。 下面是一个使用bulk_create()方法批量插入商品信息到goods表中的示例: from tortoise import fields from tortoise.contrib.fastapi import register_tortoise from tortoise.models
-
tortoise-orm官方文档 sanic官方文档 需求描述: 由于某些orm没有分页的的封装, 自己写一个分页(tortoise-orm) 我简单看了一下 flask_sqlalchemy 中的 paginate , 他的分页也是先查出过滤查询用的总数量再进行操作的, 所以代码中的 sql_count 就是外面查询出的.count() def paginate(request, sql_cou
-
概述 fastapi+tortoise的测试比较奇葩,tortoise-orm的测试需要传递event_loop,fastapi的异步测试不能直接访问,就算使用httpx的异步功能也不行(因为不会主动调用startup和shutdown)。 解决方案: tortsoie-orm的测试解决方案是通过传递event_loop的方式,自己主动激活数据库(当然顺便创建测试数据库等一系列功能),但是没都要通
-
1. 前情提要: - fastapi官方文档只给了普通异步请求demo,没有orm数据库读写的示例 - 而tortoise-orm的文档还停留在同步版的测试范例 2. 需求: 单元测试函数不仅能通过HTTP请求访问API,还能读写数据库 3. 实现: - 安装依赖:pip install httpx fastapi tortoise-orm pytest - 在tortoise-orm范例的基础上
-
在使用 Tortoise-ORM 时,可以使用 Q 对象来构建复杂的查询条件。 Q 对象是 Tortoise-ORM 中用于构建查询条件的语法结构,它支持以下操作: 1. 比较操作符:`<`, `>`, `<=`, `>=`, `==`, `!=`。 2. 逻辑操作符:`&`(and)、`|`(or)和`~`(not)。 可以通过将多个 Q 对象组合使用来构建复杂的查询条件。例如,假设要查询所有价
-
下面是一个使用Tortoise-ORM的annotate()方法的例子: from tortoise import fields, models from tortoise.queryset import F class Book(models.Model): id = fields.IntField(pk=True) name = fields.CharField(max_l
-
tortoise-orm连接多个数据库 from fastapi import FastAPI from tortoise.contrib.fastapi import register_tortoise from app.configs import config class GetDB(object): def _get_orm_base_conf(self, apps: d
-
tortoise-orm关于pydantic序列化模型外键字段无法生成的问题 首先我们定义两个模型,使用外键关联 from tortoise import fields from tortoise.models import Model class Tournament(Model): """ This references a Tournament """ i
-
安装aerich pip install aerich 创建models.py, 构建数据模型 from tortoise import Model, fields class User(Model): """ 用户基础信息 """ name = fields.CharField(max_length=24, description="姓名") id_no = fiel
-
在将我的计算机升级到乌龟SVN版本从1.6升级到1.8.3(SVN 1.8.4)后,我得到了可怕的403禁止错误。 null 在防火墙或身份验证方面,1.8有什么不同吗?Apache服务器使用html并使用网络密码进行身份验证。下一步有哪些举措?
-
问题内容: 我正在创建一个Android应用,并且需要保留一个。我刚刚开始使用Realm ORM ,因为它支持一对一和一对多的枚举和列表。我还找到了解决字符串列表的方法(即,我必须创建一个封装字符串的StringWrapper类。但是,从文档中我了解,列表并不存在像这样的简单方法。因此,我正在寻找持久化地图的最佳方法。我目前的想法是用封装了(以前的地图关键字)和的对象列表替换我的地图。类似于。是否
-
问题内容: 我在一个Android项目中使用ORMLite,并且我不想使用扩展活动,因为我是在AsyncTask上将值插入数据库中。 在文档中说: “如果您不想扩展和其他基类,那么您将需要复制它们的功能。您需要在代码的开头进行调用,保存帮助程序并根据需要使用它,然后在你完成了。” 它还说要在中添加数据库帮助程序类。所以我不确定我在做什么错。 我正在使用一个为我的数据层调用的类,如下所示: 我正在使
-
问题内容: 我将RoboSpice与Spring for Android结合使用,并希望使用OrmLite保留对象的JSON数组。GSON用于JSON编组。使用默认缓存,一切都会按预期进行。但是OrmLite似乎不喜欢对象数组。 这是JSON的简化版本: 我想在以下对象中坚持这一点: 基于RoboSpice OrmLite示例,我创建了以下GsonSpringAndroidSpiceService
-
问题内容: 我有以下表格- 对于这些表,关联的Dao和DaoImpl如下 数据库助手如下: 现在,当我尝试致电- 它错误并显示以下错误: 现在,如果我在A中没有foreign键-即如果A不包含 公共B b ,那么它可以正常工作。我在这里缺少什么吗? 提前非常感谢您。 问题答案: 我怀疑在异常堆栈跟踪的末尾有您丢失的原因消息。例如,如果我在上面重复了您的示例,则会得到: 因为有一个class的外部字
-
问题内容: 如果我使用的是JPA2之类的ORM-我的实体已映射到数据库,那么我是否仍应使用DAO?似乎要增加很多开销。 例如,我将需要维护三个额外的程序包: 一个指定我的域对象的对象(它几乎映射了我的Entity对象): 一种包含指定我的DAO方法的接口 其中包含实现我的DAO的会话bean 现在,每当我需要执行新的CRUD操作时,都会增加很多额外的负担。 但是,从DAO中我看到的好处是: 您可以