
C++动态分配和撤销内存以及结构体类型作为函数参数

C++动态分配内存(new)和撤销内存(delete)
在软件开发过程中,常常需要动态地分配和撤销内存空间,例如对动态链表中结点的插入与删除。在C语言中是利用库函数malloc和free来分配和撤销内存空间的。C++提供了较简便而功能较强的运算符new和delete来取代malloc和free函数。
注意: new和delete是运算符,不是函数,因此执行效率高。
虽然为了与C语言兼容,C++仍保留malloc和free函数,但建议用户不用malloc和free函数,而用new和delete运算符。new运算符的例子:
new int; //开辟一个存放整数的存储空间,返回一个指向该存储空间的地址(即指针) new int(100); //开辟一个存放整数的空间,并指定该整数的初值为100,返回一个指向该存储空间的地址 new char[10]; //开辟一个存放字符数组(包括10个元素)的空间,返回首元素的地址 new int[5][4]; //开辟一个存放二维整型数组(大小为5*4)的空间,返回首元素的地址 float *p=new float (3.14159); //开辟一个存放单精度数的空间,并指定该实数的初值为//3.14159,将返回的该空间的地址赋给指针变量p
new运算符使用的一般格式为:
new 类型 [初值];
用new分配数组空间时不能指定初值。如果由于内存不足等原因而无法正常分配空间,则new会返回一个空指针NULL,用户可以根据该指针的值判断分配空间是否成功。
delete运算符使用的一般格式为:
delete [ ] 指针变量
例如要撤销上面用new开辟的存放单精度数的空间(上面第例,应该用
delete p;
前面用“new char[10];”开辟的字符数组空间,如果把new返回的指针赋给了指针变量pt,则应该用以下形式的delete运算符撤销该空间:
delete [] pt; //在指针变量前面加一对方括号,表示是对数组空间的操作
【例】开辟空间以存放一个结构体变量。
#include <iostream>
#include <string>
using namespace std;
struct Student //声明结构体类型Student
{
string name;
int num;
char sex;
};
int main( )
{
Student *p; //定义指向结构体类型Student的数据的指针变量
p=new Student; //用new运算符开辟一个存放Student型数据的空间
p->name="Wang Fun"; //向结构体变量的成员赋值
p->num=10123;
p->sex='m';
cout<<p->name<<endl<<p->num
<<endl<<p->sex<<endl; //输出各成员的值
delete p; //撤销该空间
return 0;
}
运行结果为:
Wang Fun 10123 m
图为new student开辟的空间。
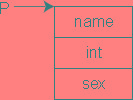
在动态分配/撤销空间时,往往将这两个运算符和结构体结合使用,是很有效的。可以看到:
要访问用new所开辟的结构体空间,无法直接通过变量名进行,只能通过指针p进行访问。如果要建立一个动态链表,必须从第一个结点开始,逐个地开辟结点并输入各结点数据,通过指针建立起前后相链的关系。
C++结构体类型作为函数参数
将一个结构体变量中的数据传递给另一个函数,有下列3种方法:
用结构体变量名作参数。一般较少用这种方法。
用指向结构体变量的指针作实参,将结构体变量的地址传给形参。
用结构体变量的引用变量作函数参数。
下面通过一个简单的例子来说明,并对它们进行比较。
【例】有一个结构体变量stu,内含学生学号、姓名和3门课的成绩。要求在main函数中为各成员赋值,在另一函数print中将它们的值输出。
1) 用结构体变量作函数参数。
#include <iostream> #include <string> using namespace std; struct Student//声明结构体类型Student { int num; char name[20]; float score[3]; }; int main( ) { void print(Student); //函数声明,形参类型为结构体Student Student stu; //定义结构体变量 stu.num=12345; //以下5行对结构体变量各成员赋值 stu.name="Li Fung"; stu.score[0]=67.5; stu.score[1]=89; stu.score[2]=78.5; print(stu); //调用print函数,输出stu各成员的值 return 0; } void print(Student st) { cout<<st.num<<" "<<st.name<<" "<<st.score[0] <<" " <<st.score[1]<<" "<<st.score[2]<<endl; }
运行结果为:
12345 Li Fung 67.5 89 78.5 (2)
2)用指向结构体变量的指针作实参在上面程序的基础上稍作修改即可。
#include <iostream>
#include <string>
using namespace std;
struct Student
{
int num; string name; //用string类型定义字符串变量
float score[3];
}stu={12345,"Li Fung",67.5,89,78.5}; //定义结构体student变量stu并赋初值
int main( )
{
void print(Student *); //函数声明,形参为指向Student类型数据的指针变量
Student *pt=&stu; //定义基类型为Student的指针变量pt,并指向stu
print(pt); //实参为指向Student类数据的指针变量
return 0;
}
//定义函数,形参p是基类型为Student的指针变量
void print(Student *p)
{
cout<<p->num<<" "<<p->name<<" "<<p->score[0]<<" " <<
p->score[1]<<" "<<p->score[2]<<endl;
}
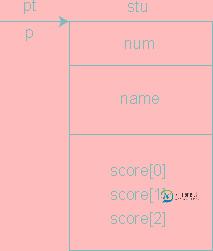
调用print函数时,实参指针变量pt将stu的起始地址传送给形参p(p也是基类型为student的指针变量)。这样形参p也就指向stu,见图。
在print函数中输出p所指向的结构体变量的各个成员值,它们也就是stu的成员值。在main函数中也可以不定义指针变量pt,而在调用print函数时以&stu作为实参,把stu的起始地址传给实参p。
3) 用结构体变量的引用作函数参数
#include <iostream>
#include <string>
using namespace std;
struct Student
{
int num;
string name;
float score[3];
}stu={12345,"Li Li",67.5,89,78.5};
int main( )
{
void print(Student &);
//函数声明,形参为Student类型变量的引用
print(stu);
//实参为结构体Student变量
return 0;
}
//函数定义,形参为结构体Student变量的引用
void print(Student &stud)
{
cout<<stud.num<<" "<<stud.name<<" "<<stud.score[0]
<<" " <<stud.score[1]<<" "<<stud.score[2]<<endl;
}
程序(1)用结构体变量作实参和形参,程序直观易懂,效率是不高的。
程序(2)采用指针变量作为实参和形参,空间和时间的开销都很小,效率较高。但程序(2)不如程序(1)那样直接。
程序(3)的实参是结构体Student类型变量,而形参用Student类型的引用,虚实结合时传递的是stu的地址,因而效率较高。它兼有(1)和(2)的优点。
引用变量主要用作函数参数,它可以提高效率,而且保持程序良好的可读性。在本例中用了string方法定义字符串变量,在某些C++系统中目前不能运行这些程序,读者可以修改程序,使之能在自己所用的系统中运行。
-
问题内容: 这是一段可以毫无问题运行的代码: 但是,如果该函数存在于另一个包中(例如),则该代码将不起作用: 我的问题是: 有没有一种方法可以使用匿名结构作为参数来调用(公共)函数(又名上文)? 以空struct作为参数的函数(也称为上文)可以被调用,即使它存在于另一个包中。这是特例吗? 好吧,我知道我总是可以命名来解决问题,我对此感到很好奇,并且想知道为什么似乎不允许这样做。 问题答案: 您的匿
-
本文向大家介绍Java内存结构和数据类型,包括了Java内存结构和数据类型的使用技巧和注意事项,需要的朋友参考一下 Java内存结构 内存就是暂时对数据的一个存储,他的存储速度非常的快,但是他是暂时的存储,从开机时开始存储,掉电或关机之后数据全部丢失。内存的生命周期就是开机和关机,开机的时候开始计算,关机什么都没有了。优点存储速度快,缺点容易坏掉,如果开机的时候,一点反映都没有,屏幕不亮键盘鼠
-
主要内容:内嵌结构体,结构内嵌特性结构体可以包含一个或多个匿名(或内嵌)字段,即这些字段没有显式的名字,只有字段的类型是必须的,此时类型也就是字段的名字。匿名字段本身可以是一个结构体类型,即结构体可以包含内嵌结构体。 可以粗略地将这个和面向对象语言中的继承概念相比较,随后将会看到它被用来模拟类似继承的行为。Go语言中的继承是通过内嵌或组合来实现的,所以可以说,在Go语言中,相比较于继承,组合更受青睐。 考虑如下的程序: 运行结果如
-
问题内容: 当您知道on上对象/项目的确切数量时,我非常想知道哪种内存分配方法对性能(例如,运行时间)有利,这对性能有好处。少量对象(少量内存)和大量对象(大量内存)的成本。 与 请告诉我。谢谢。 注意:我们可以对此进行基准测试,并且可能知道答案。但是我想知道解释这两种分配方法之间性能差异的概念。 问题答案: 静态分配将更快。静态分配可以在全局范围和堆栈上进行。 在全局范围内,静态分配的内存内置在
-
在V9.0.0版本之前为下列对象分配内存采用动态的方式,在之后的版本才允许应用程序开发者自己静态的分配内存; 任务 软件定时器 队列 事件组 二值信号量 计数信号量 递归信号量 互斥量 当然,具体使用静态分配还是动态分配由开发者自己决定。 动态分配 动态分配的好处在于使用灵活简单、同时潜在的可以降低内存占用。 更少的函数参数 内存分配使用RTOS提供的API自动分配 应用程序开发者不需要自己去考虑
-
动态内存分配 我们之前在 C/C++ 语言等中使用过 malloc/free 等动态内存分配方法,与在编译期就已完成的静态内存分配相比,动态内存分配可以根据程序运行时状态修改内存申请的时机及大小,显得更为灵活,但是这是需要操作系统的支持的,同时也会带来一些开销。 我们的内核中也需要动态内存分配。典型的应用场景有: Box<T> ,你可以理解为它和 malloc 有着相同的功能; 引用计数 Rc<T