
详解SQL中的DQL查询语言

DQL
DQL:data Query language 数据查询语言
格式:select[distinct] 字段1,字段2 from 表名 where 控制条件
(distinct: 显示结果时,是否去除重复列 给哪一列去重就在哪一列字段前加入distinct)
学生表
(1)查询表中的所有信息
SELECT * FROM student
(2)查询表中的所有学生姓名和对应的英语成绩
SELECT name,english FROM student
注:可显示部分字段,如果显示哪列数据,就直接写字段名称即可
(3) 过滤表中重复的math成绩
SELECT DISTINCT math FROM student;
(4) 创建一个student类 添加属性id,name,sex,chinese,English,math
并随机增加5条属性
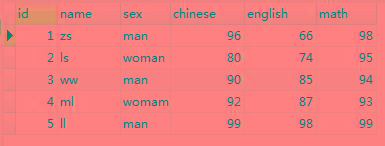
select * from student; – 查询英语在70到75之间的学生的信息 -- html" target="_blank">select * from student where english BETWEEN 70 AND 75; – 查询语文是80或者82或者90分的学生信息 -- select * from student where chinese IN(80,82,90); – 查询所有首字母为l的学生的成绩 -- select * from student where name like "l%"; – 查询数学大于80且语文大于80 的同学 -- select * from student where math>80 and chinese>90; – 对数学成绩排序后输出 (默认升序 ASC) -- select * from student order by math; – 对数学成绩排序后输出(降序 DESC) -- SELECT * FROM student order by math DESC; – 指定多个字段进行排序,先按第一个字段进行排序,如果相同则按第二个字段进行排序 -- SELECT * FROM student ORDER BY math DESC,chinese DESC; – WHERE后可以加 ORDER BY -- SELECT * from student where name like "%l" ORDER BY math DESC; – 显示student 表格中的前3行 SELECT * from student LIMIT 2; – 显示student 表格中的第3~5行 SELECT * from student LIMIT 2,3; -- 2表示偏移量,3表示显示的行数
附录:①在where中经常使用的运算符
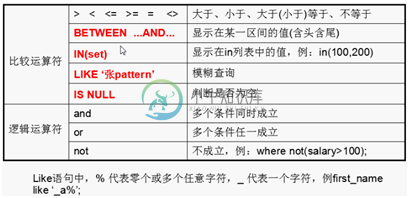
注:逻辑运算符优先级 not>and>or
*②select |{column1|expression、column2|expression,…}from table;
select column as 别名 from table;
注:
expression : mysql支持表达式 加减乘除;
as: 表示给某一列起别名;并且as 可以省略;
– 关联(1对N)
create table customer(
id int PRIMARY KEY auto_increment,
name varchar (20) not null,
adress varchar (20) not null
);
create table orders(
order_num varchar(20) PRIMARY KEY,
price FLOAT not NULL,
customer_id int, -- 进行和customer 关联的字段 外键
constraint cus_ord_fk foreign key (customer_id) REFERENCES customer(id)
);
insert into customer(name,adress) values("zs","北京");
insert into customer(name,adress) values("ls","上海");
SELECT * from customer;
INSERT INTO orders values("010",30.5,1);
INSERT INTO orders values("011",60.5,2);
INSERT INTO orders values("012",120.5,1);
SELECT * from orders;
主键和唯一标识
unique 唯一性标识
primary key 主键 (auto_increment 设置自动增长)
-- UNIQUE 表约束 唯一性标识
-- PRIMARY KEY 主键
CREATE TABLE t4 (
id INT PRIMARY KEY auto_increment,
NAME VARCHAR (20) NOT NULL,
gender CHAR (5) NOT NULL,
idCard VARCHAR (20) UNIQUE -- UNIQUE 唯一性标识
);
desc t4;
insert into t4 (name,gender,idCard) VALUE("zs","man","110");
insert into t4 (name,gender,idCard) VALUE("ls","woman","112");
总结
以上所述是小编给大家介绍的SQL中的DQL查询语言,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对小牛知识库网站的支持!
-
主要内容:一、案例,1.实际问题,2.子查询的基本使用,3.子查询的分类,二、单行子查询,1.单行比较操作符,2.代码示例,3.having中的子查询,,4.非法子查询,三、多行子查询,1.多行比较操作符,2.代码示例,四、相关子查询,1.执行流程,,2.代码示例,3.EXISTS 与 NOT EXISTS关键字,4.相关更新,5.相关删除,6.相关插入子查询指一个查询语句嵌套在另一个查询语句内部的查询。 SQL 中子查询的使用大大增强了 SELECT 查询的能力,因为很多时候查询需要从结果集中
-
主要内容:一、错误案例引入问题,二、多表查询的分类,1.等值连接和非等值连接,2.自连接和非自连接,3.内连接和外连接,三、实现多表查询的语法,1.内连接(INNER JOIN)的实现,2.外连接(OUTER JOIN)的实现,四、UNION的使用,五、7种SQL JOINS的实现,1.代码实现,六、SQL99语法新特性,1.自然连接,2.USING连接关联查询,也称为多表查询,指两个或更多个表一起完成查询操作。 前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字
-
本文向大家介绍SQL Server中的连接查询详解,包括了SQL Server中的连接查询详解的使用技巧和注意事项,需要的朋友参考一下 在查询多个表时,我们经常会用“连接查询”。连接是关系数据库模型的主要特点,也是它区别于其它类型数据库管理系统的一个标志。 什么是连接查询呢? 概念:根据两个表或多个表的列之间的关系,从这些表中查询数据。 目的:实现多个表查询操作。 知道了连接查询的概念之后,什么时
-
本文向大家介绍详解MySQL中的分组查询与连接查询语句,包括了详解MySQL中的分组查询与连接查询语句的使用技巧和注意事项,需要的朋友参考一下 分组查询 group by group by 属性名 [having 条件表达式][ with rollup] “属性名 ”指按照该字段值进行分组;“having 条件表达式 ”用来限制分组后的显示,满足条件的结果将被显示;with rollup 将会在所
-
问题内容: 假设我有一个事件()实例,其中有许多,则需要获取属于的所有对象,其中AttendancePerson.person参加了多个事件,该事件的 相匹配,并且在上一年结束的位置。 模式减去不相关的列名: 目的是找到任何给定事件的老成员。在上一年中多次参加共享同一日历的活动的任何活动出席者都是该活动的“老会员”。 我阅读了许多相关的问题。他们都没有帮助。谢谢任何对此有帮助的人。 问题答案: 对
-
问题内容: 我有一个带下表的sqlite数据库: 两个示例记录如下所示: (大麦的球队输了,安娜的赢了。每场比赛每队都有几名球员。)我想创建一个查询,该查询将返回所有有x个玩家在一个团队而y个玩家在另一个团队的游戏,以及这些游戏的累积结果。游戏。 我知道如何使用perl和csv文件来执行此操作,并且我相信我可以对dbi接口使用相同的方法。但是,我想学习如何仅使用SQL查询来创建此报告。我是SQL的