
JavaScript 正则应用详解【模式、欲查、反向引用等】

本文实例讲述了JavaScript 正则应用。分享给大家供大家参考,具体如下:
正则应用
正则表达式在web开发中的常用
邮箱验证
用户名验证
替换字符串某一部分
信息采集,用来分析有效代码段
...
有规律的字符串描述
正则表达式是一门独立的知识,同样的一段描述,比如,对于email的匹配表达式,在不同的语言是一样的,但是调用的函数不同。
正则表达式--规则表达式
正则表达式:正则表达式
正则表达式语法:正则表达式语法
正则表达式语言:正则表达式语言
准备性的工作
在js中,如何写正则表达式。 /RegExp/
在js里,用正则表达式来验证字符串是否满足, 使用 reg.test(str);
用正则表达式的exec函数,用来查找匹配的选项,并把查找的值取出。
reg.test(str); 返回true 或者false 。 常在表单验证中使用。
<from action="xxx.php" id="biaodan">
<p>请输入姓名:<input type="text" id="name" /></p>
<p>请输入年龄:<input type="text" id="age" /></p>
<p><input type="submit" /></p>
</from>
<script>
var oBD = document.getElementById('biaodan');
var oName = document.getElementById('name');
var oAge = document.getElementById('age');
//表单试图提交的时候,触发onsubmit事件
//这个函数返回了false,表单不会被提交
oBD.onclick = function(){
//验证name
if( !/^[\u4e00-\u9fa5]{2,4}$/.test(oName.value) ) return false;
//验证年龄
if( !/^\d{2,3}$/.test(oAge.value) ) return false;
if( parseInt( oAge.value )<10 || parseInt( oAge.value )>104 ) alert('您输入的年龄不在范围') return
false;
return true;
}
</script>
exec(); 返回 数组 或 null。
exec是英语execute的意思,CEO首席执行官,E就是executive执行的
“执行” 把正则式放到字符串上执行
每次执行结果按序输出,不管结果有几个,一次只输出一个 ,如果多次输出,会保持前面的引用。当匹配超过原字符串的时候,会返回null。然后遇到null,指针返回到匹配的字符的第一位。 具有迭代器的感觉。
var str = 'ABCDEFG1234567abcdefg';
var reg = /[a-z]/g;
console.log( a=/[a-z]/g.exec(str) );
var a;
while( a=reg.exec(str) ){ //这边 null 为 fasle。 exec() 会保持对前面一次的引用。 需要使用 值来赋值。
console.log( a );
}
使用exec() 找最大子串
var str = 'AAABBBCCCCCCC';
var reg = /(\w)\1+/g;
var maxLength = 0;
var maxLetter = '';
var a;
while( a=reg.exec(str) ){
if( a[0].length>maxLength ){
maxLength = a[0].length;
maxLetter = a[0];
}
}
console.log( maxLetter );

var str='BCDEFG1234567abcdefg';
var reg = /[a-z]/g;
var a;
while( (a=reg.exec(str)) != null ){ //先赋值给a,然后再与后边判断。
console.log( a );
}

str.match( reg ); //查找,匹配到,返回数组
str.split( reg ); //拆分,返回数组
str.serch( reg ); //查找位置
str.replace( reg,'new str'); //正则替换,返回string
//测试是否含有hi
var reg = /hi/; //仅看字符串是否有 hi
console.log( reg.test('hello') ); //fasle
console.log( reg.test('this is iqianduan') ); //true
//测试单词 hi
var reg01 = /\bhi\b/;
console.log( reg01.test('this is') ); //false
console.log( reg01.test('this is, hi,his') );//true
正则表达式 3 句话
要找什么字符?
从哪儿找?
找几个?
要找什么字符
字面值, ‘hi' ,就是找‘hi'。
用字符的集合来表示 , [abcd], 指匹配abcd中任意一个
//找不吉利的数字
//3,4,7
var reg = /[3,4,7]/; //字符集合, 不能使用 /347/ 字面值表示,是表示整体。
console.log( reg.test('12121212') );//false
console.log( reg.test('12341234') ); //true
用范围表示字符 , [0-9] [0123456789] [a-z] [A-Z]
// var reg = /[0123456789]/;
var reg = /[0-9]/;
console.log( reg.test('123afsdf') ); //true
console.log( reg.test('asdf') ); //false
//是否有大写字母
var reg = /[A-Z]/;
console.log( reg.test('asdf') );//false
console.log( reg.test('Tomorrow is another day') ); //true
字符簇, 花团锦簇-> 一坨字符。
系统为常用的字符集合,创建的简写.
例如:
-
[0-9] --> \d
-
[0-9a-zA-Z_] --> \w .. 域名,注册用户名常用的模式.
-
[\t\v\f\r\n] --> \s 空白符.
//是否含有数字
var reg = /\d/;
console.log( reg.test('123afsdf') ); //true
console.log( reg.test('asdf') ); //false
补集的形式来表示字符集合 在集合前面使用表示补集。
-
[0-9]---> [^0-9] ^ 脱字符号: 念法: caret。['kærət] 。
-
[abcdef]-->[^abcdef]
//验证全为数字
var reg = /^[0-9]/; //匹配非数字
// var reg = /^d/ //字符簇补集
console.log( reg.test('aaaaa') );//非数字存在 false
console.log( reg.test('123aaa') ); //有数字存在 true
字符簇的补集:
-
d -- > D(非数字)
-
s --> S(非空白字符)
-
w --> W
-
任意字符 : . 唯独不包括换行符
从哪儿找,找到哪儿
b 单词边界
/bhi/ --> 从单词的边界开始匹配hi。
// 匹配单词hi,包括hi本身
// var reg = /\bhi.+/;//错误
// var reg = /\bhi\w+/; //错误。 + --> 至少有 一个
var reg = /\bhi\w*/;
console.log( reg.exec('this is') ); //null
console.log( reg.exec('his') ); //["his", index: 0, input: "his"]
console.log( reg.exec('history') ); //["history", index: 0, input: "history,hi"]
//匹配进行时的结尾
var reg = /\b[a-zA-Z]+ing\b/;
console.log( reg.exec('going') );//["going", index: 0, input: "going"]
console.log( reg.exec('1ting.com') );//null
console.log( reg.exec('ing') );//null //2 -> to 4->for 0->zero
//匹配un前缀的反义词
//unhappy happy,hungry,sun,unhappy
var reg = /\bun[\w]+\b/;
console.log( reg.exec('happy,hungry,sun,unhappy') ); //["unhappy", index: 17, input: "happy,hungry,sun
,unhappy"]
B 单词的非边界
// 把单词中间的某一个部分取出来。
// 把中间含有hi的单词取出,即hi不能在两端。
var reg = /\Bhi\B/;
console.log( reg.exec('this') ); //["hi", index: 1, input: "this"]
console.log( reg.exec('hi') ); //null
^ creat , 从字符串的起始位置开始匹配
$ 匹配到字符串的结束位置
从字符串的开头到结尾开始匹配,模拟运行顺序.
var reg = /^lishi$/;
console.log( reg.exec('lishinihao') ); null
console.log( reg.exec('lishi') ); //["lisi", index: 0, input: "lisi"]
找多少
*, [0,n] --> {0, }
+ , [1,n] -->{1, }
? , [0,1] -->{0,1}
n {n} {3} a{n} , 字符a准确的出现n次
a{n,} 字符a,至少出现n次。
a{n,m} 字符串a,出现n到m次。
模式
以匹配为例,默认情况下,找到一次结果符合就结束。
告知匹配过程,一直找,在全文范围内一直找。
g -> 全局模式, global 找所有的,而不是找一次就结束
i -> 忽略大小写,ignore
//查找所有中间含有hi的单词 var reg = /\Bhi\B/gi; var str = 'shit,hi,this,thit,THIS'; console.log( str.match(reg) ); //["hi", "hi", "hi", "HI"]
确定边界是什么,那些东西必须有,那些东西可能有可能没有。配合+,*
//把链接换成 # //<a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ></a> --> <a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ></a> //1,不能保留链接的文字(反向引用) //2,不能跨行(贪婪模式) var reg = /<a[\s]+.*<\/a>/g; var str = '<a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" ></a>'; console.log( str.replace(reg,'<a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >文字</a>') );
js不支持单行模式。
//s 单行模式:把整个字符串看成一行 . 代表任意,但不包括换行。
在js里,不支持当行模式的情况下,如何换行?
什么样的模式能代表“所有” 字符串
sS 全部字符 使用一个技巧, 一个集合加补集,就是全集
[dD] [sS] [wW]
var reg = /\<a[\s][\s\S]+<\/a>/g; var str = '<a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >'+ '</a>'; console.log( str.replace(reg,'<a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >文字</a>') ); //s 多行模式:碰到一行就把当前的当成一个字符串来解析
//把每一行的结尾的数字换成 # //车牌号 //Cx003 //A0008 //B3456 var str = 'Cx003'+ 'A0008'+ 'B3456'; var reg = /\d+$/gm; console.log( str.replace(reg,'#') );
贪婪模式
贪婪模式
如果'?'紧跟在在任何量词*, + , ?,或者是{}的后面,将会使量词变成非贪婪模式(匹配最少的次数),和默认的贪婪模式(匹配最多的次数)正好相反。
比如,使用/d+/非全局的匹配“123abc”将会返回“123”,如果使用/d+?/,那么就只会匹配到“1”。
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
任何量词后面 跟 ? 代表非贪婪模式 , 满足条件就不找了,小富即安,打完收工。 修饰个数,尽量少找和多找的。
//goooooooooods --> goods
var str = 'goooooooooods,goooods,goooood,gooooo,gooooods';
var reg = /g[o]{3,}?ds/g;
console.log( str.replace(reg,'goods') ); //goods,goods,goooood,gooooo,goods
欲查
正向欲查
欲查不消耗字符。
//查找进行时的单词的词根, 即 不要ing 。 going -> go var str = 'going,comming,fly'; // var reg = /\b[a-zA-Z]+ing\b/g; var reg = /\b[\w]+(?=ing)\b/g; // 类似探照灯,先去判断几位是否满足,满足返回,不满足继续下一位. console.log( str.match(reg) );



满足 ing ,找到com。

不满足接着走。 看见不满足条件,并不会一次性调到ing后面接下去寻找,而是从该处光标继续寻找。
已经查找的词是消耗了,下次从该处光标开始寻找。

//查找进行时的单词的词根, 即 不要ing 。 going -> go var str = 'going,comming,fly'; // var reg = /\b[a-zA-Z]+ing\b/g; // var reg = /\b[a-zA-Z]+(?=ing)\b/g; //结尾\b 是错误的, 欲查不消耗字符, 相当于/\b[a-zA-Z]+\b/ 这种形式 var reg = /\b[a-zA-Z]+(?=ing)/g; // 类似探照灯,先去判断几位是否满足,满足返回,不满足继续下一位. console.log( str.match(reg) ); // ["go", "comm"]
负向欲查
不是谁才行。 往后看一定位数,不是谁才可以。 不要后面是某某某的东西。
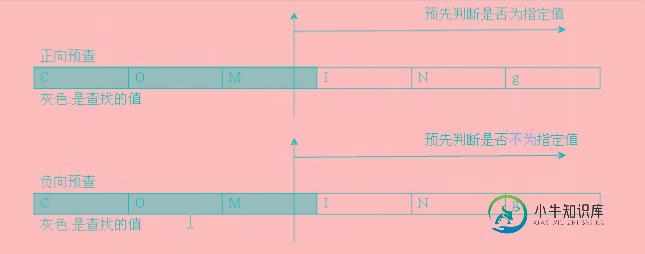
//查找win98,win95,win32,win2003,winxp -->win98,win32,win2003,winxp var str = 'win98,win95,win32,win2003,winxp'; var reg = /\bwin(?!95)/g; console.log( str.match(reg) ); // ["win", "win", "win", "win"]
js不支持,向前正向欲查,向前负向欲查:
//找出 un系列单词的词根 var reg = /[\w]+(?<=un)/g; var str = 'unhappy'; console.log(str.match(reg)); //报错 var reg = /[\w]+(?<!=un)/g; //向前负向欲查
反向引用
反向引用,也叫后向引用。或者分组或子表达式
一般是整个表达式, 但是中间的部分 有特殊做了描述。 需要的部分特殊处理。使用分组,叫做子表达式。
//把链接换成空连接,保持文字信息。
var str = '<a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >阴天快乐</a>';
var reg = /<a[\s]+[^>]+>([^<>]+)<\/a>/; //超链接的表达式
console.log( reg.exec(str) ); //["<a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >阴天快乐</a>", "阴天快乐", index: 0
, input: "<a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >阴天快乐</a>"] //能够把子表达式的东西匹配出来。
// console.log( str.replacte(reg,'#') );
/**
<a[\s]+[^>]>([^<>]+)<\/a> 主要目的是想要中间那一块
除了>之外的都可行 , 取> 的补集 [^>]
中间部分纯文字,不含大于号,和小于号。 取小于号和大于号的补集 [^<>]+ / [\s\S]+
*/
//一般是整个表达式, 但是中间的部分 有特殊做了描述。 需要的部分特殊处理。使用分组,叫做子表达式。
//匹配html
// /<\s*(\S+)(\s[^>]*)?>[\s\S]*<\s*\/\1\s*>/
/*exec为例:
匹配到的数组,第0个单元,代表"整个正则表达式的匹配结果"
1,2,3,4....N,则代表第N个子表达式匹配的结果。 //js顶多有9个子表达式。 // ["<a href="http://www.baidu
.com">阴天快乐</a>", "阴天快乐", index: 0, input: "<a href="http://www.baidu.com" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >阴天快乐</a>"]
*/
console.log( str.replace(reg,'<a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >$1</a>') ); //<a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >阴天快乐</a>
var str = '<html></html>';
var reg = /<\s*(\S+)(\s[^>]*)?>[\s\S]*<\s*\/\1\s*>/;
console.log( reg.exec(str) );
str.replace(reg,function( $1,$2 ){
console.dirxml($2); //html
});
如何引用子表达式所匹配的结果?
-
在正则外边使用:$N 来匹配 第N个子表达式的匹配结果。
-
在正则里边使用N来 使用第N个子表达式。
更多关于JavaScript相关内容感兴趣的读者可查看本站专题:《JavaScript正则表达式技巧大全》、《JavaScript替换操作技巧总结》、《JavaScript查找算法技巧总结》、《JavaScript数据结构与算法技巧总结》、《JavaScript遍历算法与技巧总结》、《JavaScript中json操作技巧总结》、《JavaScript错误与调试技巧总结》及《JavaScript数学运算用法总结》
希望本文所述对大家JavaScript程序设计有所帮助。
-
问题内容: 我必须先匹配一个数字,然后再匹配14次。然后,我来到了regexstor.net/tester中的以下正则表达式: 编辑 当我将其粘贴到代码中时,包括正确的反斜杠: 我已经用来替换了反向引用,该反向引用用于替换Java中的匹配项。 然后我意识到这是行不通的。在Java中,当需要在REGEX中向后引用匹配项时,必须使用,但是要替换它时,运算符为。 我的问题是:为什么? 问题答案: 在Ja
-
本文向大家介绍Java正则表达式中的反向引用,包括了Java正则表达式中的反向引用的使用技巧和注意事项,需要的朋友参考一下 捕获组是一种将多个字符视为一个单元的方法。通过将要分组的字符放在一组括号内来创建它们。例如,正则表达式(狗)创建一个包含字母“ d”,“ o”和“ g”的单个组。 捕获组通过从左到右计数其开括号来编号。例如,在表达式((A)(B(C)))中,有四个这样的组- 示例 反向引用允
-
本文向大家介绍javascript中的正则表达式使用详解,包括了javascript中的正则表达式使用详解的使用技巧和注意事项,需要的朋友参考一下 [1]定义:正则又叫规则或模式,是一个强大的字符串匹配工具,在javascript中是一个对象 [2]特性: [2.1]贪婪性,匹配最长的 [2.2]懒惰性,不设置/g,则只匹配第1个 [3]两种写法: [3.1]perl写法(使用字面量形
-
本文向大家介绍正则表达式捕获Java中的组和反向引用,包括了正则表达式捕获Java中的组和反向引用的使用技巧和注意事项,需要的朋友参考一下 捕获组是一种将多个字符视为一个单元的方法。通过将要分组的字符放在一组括号内来创建它们。例如,正则表达式(狗)创建一个包含字母“ d”,“ o”和“ g”的单个组。 捕获组通过从左到右计数其开括号来编号。例如,在表达式((A)(B(C)))中,有四个这样的组-
-
本文向大家介绍常用JavaScript正则表达式汇编与示例详解,包括了常用JavaScript正则表达式汇编与示例详解的使用技巧和注意事项,需要的朋友参考一下 1.1 前言 目前收集整理了21个常用的javaScript正则表达式,其中包括用户名、密码强度、整数、数字、电子邮件地址(Email)、手机号码、身份证号、URL地址、 IP地址、 十六进制颜色、 日期、 微信号、车牌号、中文正则等。表单
-
本文向大家介绍JavaScript正则表达式中的ignoreCase属性使用详解,包括了JavaScript正则表达式中的ignoreCase属性使用详解的使用技巧和注意事项,需要的朋友参考一下 ignoreCase是正则表达式对象的只读布尔属性。它指定是否一个特定的正则表达式执行不区分大小写的匹配。,它与“i”属性创建。 语法 下面是参数的详细信息: NA 返回值: 如果“i”修改被设