
详细了解JAVA NIO之Buffer(缓冲区)

当我们需要与 NIO Channel 进行交互时, 我们就需要使用到 NIO Buffer, 即数据从 Buffer读取到 Channel 中, 并且从 Channel 中写入到 Buffer 中。缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
缓冲区基础
Buffer 类型有:
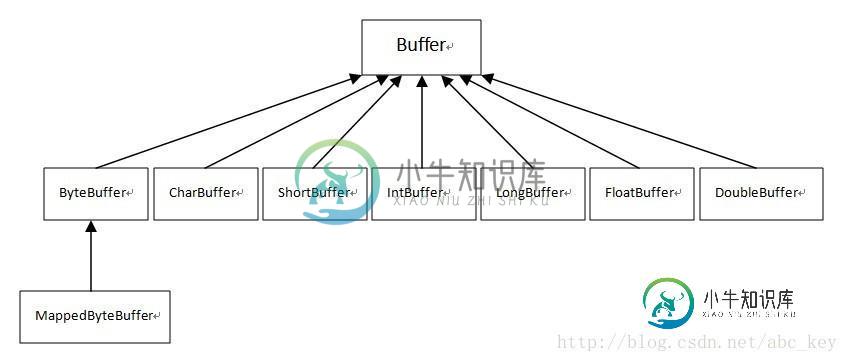
缓冲区是包在一个对象内的基础数据的数组,Buffer类相比一般简单数组而言其优点是将数据的内容和相关信息放在一个对象里面,这个对象提供了处理缓冲区数据的丰富的API。
所有缓冲区都有4个属性:capacity、limit、position、mark,并遵循:capacity>=limit>=position>=mark>=0,下面是对这4个属性的解释:
- Capacity: 容量,即可以容纳的最大数据量;在缓冲区创建时被设定并且不能改变
- Limit: 上界,缓冲区中当前数据量
- Position: 位置,下一个要被读或写的元素的索引
- Mark: 标记,调用mark()来设置mark=position,再调用reset()可以让position恢复到标记的位置即position=mark
我们通过一个简单的操作流程来说明buffer的使用,下图是新创建的容量为10的缓冲区逻辑视图:

然后进行5次调用put:
buffer.put((byte)'A').put((byte)'B').put((byte)'C').put((byte)'D').put((byte)'E')
5次调用put之后的缓冲区为:

现在缓冲区满了,我们必须将其清空。我们想把这个缓冲区传递给一个通道,以使内容能被全部写出,但现在执行get()无疑会取出未定义的数据。我们必须将 posistion设为0,然后通道就会从正确的位置开始读了,但读到哪算读完了呢?这正是limit引入的原因,它指明缓冲区有效内容的未端。这个操作 在缓冲区中叫做翻转:buffer.flip()。
Buffer的基本用法
使用Buffer读写数据一般遵循以下四个步骤:
- 写入数据到Buffer
- 调用flip()方法
- 从Buffer中读取数据
- 调用clear()方法或者compact()方法
当向buffer写入数据时,buffer会记录下写了多少数据。
一旦要读取数据,需要通过flip()方法将Buffer从写模式切换到读模式。在读模式下,可以读取之前写入到buffer的所有数据。
一旦读完了所有的数据,就需要清空缓冲区,让它可以再次被写入。有两种方式能清空缓冲区:调用clear()或compact()方法。clear()方法会清空整个缓冲区。compact()方法只会清除已经读过的数据。任何未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面。
下面我们看一段程序来看一下Buffer的基本用法:
public static void readFile(String fileName) { RandomAccessFile aFile = null; try { //文件流 aFile = new RandomAccessFile(fileName, "rw"); //将文件输入到管道 FileChannel inChannel = aFile.getChannel(); //为buffer分配1024个字节大小的空间 ByteBuffer buf = ByteBuffer.allocate(1024); //将buffer中的内容读取到管道中 int bytesRead = inChannel.read(buf); while (bytesRead != -1) { //反转buffer,将写模式改为读模式 buf.flip(); while (buf.hasRemaining()) { //获取buffer中的数据 System.out.print((char) buf.get()); } //将上次分配的1024字节的内容清空,为下次接收做准备 buf.clear(); //管道重新读取buffer中的内容 bytesRead = inChannel.read(buf); } aFile.close(); } catch (Exception e) { e.printStackTrace(); } }
字节缓冲区
我们将进一步观察字节缓冲区。所有的基本数据类型都有相应的缓冲区类(布尔型除外),但字节缓冲区有自己的独特之处。字节是操作系统及其I/O设备使用的基本数据类型。当在JVM和操作系统间传递数据时,将其他的数据类型拆分成构成它们的字节是十分必要的。如我们在后面的章节中将要看到的那样,系统层次的I/O面向字节的性质可以在整个缓冲区的设计以及它们互相配合的服务中感受到。
直接缓冲区
我们知道操作系统是在内存中进行I/O操作,这些内存区域,就操作系统方面而言,是相连的字节序列。于是,毫无疑问,只有字节缓冲区有资格参与I/O操作。即操作系统会直接存取进程,那么我们现在在JVM中进行操作,java中的内存空间是由JVM直接进行管理,但是在JVM中,字节数组可能不会在内存中连续存储,或者无用存储单元收集可能随时对其进行移动,这就不能保证I/O操作的目标是连续的。
出于这一原因,引入了直接缓冲区的概念。直接缓冲区被用于与通道和固有I/O例程交互。它们通过使用固有代码来告知操作系统直接释放或填充内存区域,对用于通道直接或原始存取的内存区域中的字节元素的存储尽了最大的努力。
直接字节缓冲区通常是I/O操作最好的选择。在设计方面,它们支持JVM可用的最高效I/O机制。非直接字节缓冲区可以被传递给通道,但是这样可能导致性能损耗。通常非直接缓冲不可能成为一个本地I/O操作的目标。如果您向一个通道中传递一个非直接ByteBuffer对象用于写入,通道可能会在每次调用中隐含地进行下面的操作:
- 创建一个临时的直接ByteBuffer对象。
- 将非直接缓冲区的内容复制到临时缓冲中。
- 使用临时缓冲区执行低层次I/O操作。
- 临时缓冲区对象离开作用域,并最终成为被回收的无用数据。
视图缓冲区
就像我们已经讨论的那样,I/O基本上可以归结成组字节数据的四处传递。在进行大数据量的I/O操作时,很又可能你会使用各种ByteBuffer类去读取文件内容,接收来自网络连接的数据,等等。一旦数据到达了你的ByteBuffer,您就需要查看它以决定怎么做或者在将它发送出去之前对它进行一些操作。ByteBuffer类提供了丰富的API来创建视图缓冲区。
视图缓冲区通过已存在的缓冲区对象实例的工厂方法来创建。这种视图对象维护它自己的属性,容量,位置,上界和标记,但是和原来的缓冲区共享数据元素。但是ByteBuffer类允许创建视图来将byte型缓冲区字节数据映射为其它的原始数据类型。例如,asLongBuffer()函数创建一个将八个字节型数据当成一个long型数据来存取的视图缓冲区。
但是使用视图缓冲区的话,一旦ByteBuffer对于视图的维护对象产生非常规行的使用,那么对于工厂方法创建的缓冲区而言,asLongBuffer()函数就不在使用这个视窗,那么这个8字节的数据当成一个long类型的数据类型来存取的数据视图。
以上就是详细了解JAVA NIO之Buffer(缓冲区)的详细内容,更多关于JAVA NIO buffer(缓冲区)的资料请关注小牛知识库其它相关文章!
-
稳定性: 2 - 稳定的 在 ECMAScript 2015 (ES6) 引入 TypedArray 之前,JavaScript 语言没有读取或操作二进制数据流的机制。 Buffer 类被引入作为 Node.js API 的一部分,使其可以在 TCP 流或文件系统操作等场景中处理二进制数据流。 TypedArray 现已被添加进 ES6 中,Buffer 类以一种更优化、更适合 Node.js 用
-
正如我们先前所指出的,网络数据的基本单位永远是 byte(字节)。Java NIO 提供 ByteBuffer 作为字节的容器,但它的作用太有限,也没有进行优化。使用ByteBuffer通常是一件繁琐而又复杂的事。 幸运的是,Netty提供了一个强大的缓冲实现类用来表示字节序列以及帮助你操作字节和自定义的POJO。这个新的缓冲类,ByteBuf,效率与JDK的ByteBuffer相当。设计Byte
-
Java NIO Buffers用于和NIO Channel交互。正如你已经知道的,我们从channel中读取数据到buffers里,从buffer把数据写入到channels. buffer本质上就是一块内存区,可以用来写入数据,并在稍后读取出来。这块内存被NIO Buffer包裹起来,对外提供一系列的读写方便开发的接口。 Buffer基本用法(Basic Buffer Usage) 利用Buf
-
JavaScript 语言自身只有字符串数据类型,没有二进制数据类型。 但在处理像TCP流或文件流时,必须使用到二进制数据。因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。 在 Node.js 中,Buffer 类是随 Node 内核一起发布的核心库。Buffer 库为 Node.js 带来了一种存储原始数据的方法,可以让 Node.js 处理二
-
当你使用画布时,你可以检索读取画布上的像素数据,或者操作画布上的像素。读取图像数据使用createImageData(sw,sh)或者getImageData(sx,sy,sw,sh)。这两个函数都会返回一个包含宽度(width),高度(height)和数据(data)的图像数据(ImageData)对象。图像数据包含了一维数组像素数据,使用RGBA格式进行检索。每个数据的数据范围在0到255之间
-
问题内容: 我是Java的新手。我想做一个游戏。经过大量研究,我不了解缓冲策略的工作原理。.我了解基础知识..它创建了一个屏幕外图像,您以后可以将其放入Windows对象中。 我不知道..我已经研究了很长时间了..根本没有运气..我不知道..也许所有的东西都在里面,而且它很清楚很简单,我我太愚蠢而看不见.. 感谢所有的帮助.. :) 问题答案: 运作方式如下: 该构造了一个当你调用。该知道它属于那